-
【深度学习实验】循环神经网络(三):门控制——自定义循环神经网络LSTM(长短期记忆网络)模型
目录
经验是智慧之父,记忆是智慧之母。
——谚语
一、实验介绍
LSTM(长短期记忆网络)是一种循环神经网络(RNN)的变体,用于处理序列数据。它具有记忆单元和门控机制,可以有效地捕捉长期依赖关系。
- 基于门控的循环神经网络(Gated RNN)
- 门控循环单元(GRU)
- 门控循环单元(GRU)具有比传统循环神经网络更少的门控单元,因此参数更少,计算效率更高。GRU通过重置门和更新门来控制信息的流动,从而改善了传统循环神经网络中的长期依赖问题。
- 长短期记忆网络(LSTM)
- 长短期记忆网络(LSTM)是另一种常用的门控循环神经网络结构。LSTM引入了记忆单元和输入门、输出门以及遗忘门等门控机制,通过这些门控机制可以选择性地记忆、遗忘和输出信息,有效地处理长期依赖和梯度问题。
- 门控循环单元(GRU)
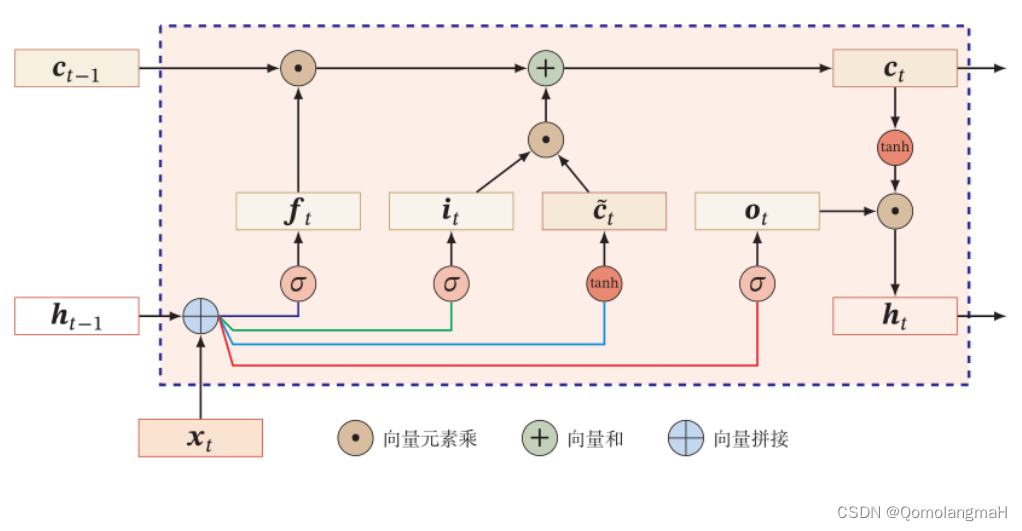
- LSTM示意图
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.htmlconda install matplotlibconda install scikit-learn2. 库版本介绍
软件包 本实验版本 目前最新版 matplotlib 3.5.3 3.8.0 numpy 1.21.6 1.26.0 python 3.7.16 scikit-learn 0.22.1 1.3.0 torch 1.8.1+cu102 2.0.1 torchaudio 0.8.1 2.0.2 torchvision 0.9.1+cu102 0.15.2 三、实验内容
导入必要的工具包
- import torch
- from torch import nn
- import torch.nn.functional as F
- from d2l import torch as d2l
- import math
(一)自定义LSTM类
循环神经网络(RNN)是一种经典的神经网络架构,用于处理序列数据,其中每个输入都与先前的信息相关。长短期记忆网络(LSTM)是RNN的一种特殊类型,它通过引入记忆单元和门控机制来解决传统RNN中的梯度消失和梯度爆炸问题。
LSTM的关键思想是通过门控单元来控制信息的流动和存储。它由三个主要的门组成,分别是输入门(input gate)、遗忘门(forget gate)和输出门(output gate)。这些门通过学习参数来决定是否传递、遗忘或输出信息,从而使LSTM能够更好地处理长期依赖关系。
在LSTM中,记忆单元(memory cell)是网络的核心组件。记忆单元类似于存储单元,可以存储和读取信息。它通过遗忘门来决定要删除哪些信息,通过输入门来决定要添加哪些新信息,并通过输出门来决定要输出哪些信息。
LSTM模型的训练过程通常使用反向传播算法和梯度下降优化器来最小化损失函数。在自然语言处理(NLP)任务中,LSTM广泛应用于语言建模、机器翻译、情感分析等领域,因为它能够有效地捕捉和利用文本序列中的上下文信息。
class LSTM(nn.Module):1.__init__(初始化)- def __init__(self, input_size, hidden_size):
- super(LSTM, self).__init__()
- self.input_size = input_size
- self.hidden_size = hidden_size
- # 初始化模型,即各个门的计算参数
- self.W_i = nn.Parameter(torch.randn(input_size, hidden_size))
- self.W_f = nn.Parameter(torch.randn(input_size, hidden_size))
- self.W_o = nn.Parameter(torch.randn(input_size, hidden_size))
- self.W_a = nn.Parameter(torch.randn(input_size, hidden_size))
- self.U_i = nn.Parameter(torch.randn(hidden_size, hidden_size))
- self.U_f = nn.Parameter(torch.randn(hidden_size, hidden_size))
- self.U_o = nn.Parameter(torch.randn(hidden_size, hidden_size))
- self.U_a = nn.Parameter(torch.randn(hidden_size, hidden_size))
- self.b_i = nn.Parameter(torch.randn(1, hidden_size))
- self.b_f = nn.Parameter(torch.randn(1, hidden_size))
- self.b_o = nn.Parameter(torch.randn(1, hidden_size))
- self.b_a = nn.Parameter(torch.randn(1, hidden_size))
- self.W_h = nn.Parameter(torch.randn(hidden_size, hidden_size))
- self.b_h = nn.Parameter(torch.randn(1, hidden_size))
-
定义LSTM模型的各个参数以及参数的计算方式:
input_size表示输入的特征维度;hidden_size表示隐藏状态的维度;- 一系列可学习的参数,用于定义LSTM的各个门和计算
W_i,W_f,W_o,W_a: 输入到隐藏状态的权重矩阵,形状为(input_size, hidden_size)。U_i,U_f,U_o,U_a: 隐藏状态到隐藏状态的权重矩阵,形状为(hidden_size, hidden_size)。b_i,b_f,b_o,b_a: 各个门的偏置项,形状为(1, hidden_size)。W_h,b_h: 隐藏状态到输出的权重矩阵和偏置项,用于计算最终的输出,形状分别为(hidden_size, hidden_size)和(1, hidden_size)。
2.init_state(初始化隐藏状态)- def init_state(self, batch_size):
- hidden_state = torch.zeros(batch_size, self.hidden_size)
- cell_state = torch.zeros(batch_size, self.hidden_size)
- return hidden_state, cell_state
-
接收
batch_size参数,返回一个大小为(batch_size, hidden_size)的全零张量作为隐藏状态和细胞状态的初始值。 -
前向传和细胞状态的初始值。
3.forward(前向传播)- def forward(self, inputs, states=None):
- batch_size, seq_len, input_size = inputs.shape
- if states is None:
- states = self.init_state(batch_size)
- hidden_state, cell_state = states
- outputs = []
- for step in range(seq_len):
- inputs_step = inputs[:, step, :]
- i_gate = torch.sigmoid(torch.mm(inputs_step, self.W_i) + torch.mm(hidden_state, self.U_i) + self.b_i)
- f_gate = torch.sigmoid(torch.mm(inputs_step, self.W_f) + torch.mm(hidden_state, self.U_f) + self.b_f)
- o_gate = torch.sigmoid(torch.mm(inputs_step, self.W_o) + torch.mm(hidden_state, self.U_o) + self.b_o)
- c_tilde = torch.tanh(torch.mm(inputs_step, self.W_a) + torch.mm(hidden_state, self.U_a) + self.b_a)
- cell_state = f_gate * cell_state + i_gate * c_tilde
- hidden_state = o_gate * torch.tanh(cell_state)
- y = torch.mm(hidden_state, self.W_h) + self.b_h
- outputs.append(y)
- return torch.cat(outputs, dim=0), (hidden_state, cell_state)
- 接收输入
inputs和可选的初始状态statesinputs的形状为(batch_size, seq_len, input_size),表示一个批次的输入序列- 如果没有提供初始状态,则调用
init_state函数初始化隐藏状态
- 对于输入序列中的每一时间步:
- 获取当前时间步的输入
inputs_step,形状为(batch_size, input_size); - 根据输入、隐藏状态和模型参数计算输入门、遗忘门、输出门和细胞更新值:
i_gate表示输入门;f_gate表示遗忘门;o_gate表示输出门;c_tilde表示细胞更新值;
- 这些门和细胞更新值的计算都是基于输入、隐藏状态和模型参数的矩阵乘法和激活函数的组合;
- 更新细胞状态和隐藏状态:
cell_state根据输入门、遗忘门和细胞更新值更新;hidden_state根据输出门和细胞状态计算;
- 计算当前时间步的输出
y,形状为(batch_size, hidden_size),通过对隐藏状态应用线性变换得到; - 将输出
y添加到outputs列表中;
- 获取当前时间步的输入
- 返回所有时间步的输出
outputs拼接的结果,形状为(batch_size * seq_len, hidden_size),以及最后一个时间步的隐藏状态和细胞状态。
(二)定义RNNModel类
0. 基础RNN模型
参照前文;
将LSTM作为RNN层,和一个线性层封装为RNNModel类,用于完成从输入到预测词典中的词的映射,并实现了初始化隐状态的函数。
class RNNModel(nn.Module):1.__init__(初始化)- def __init__(self, rnn_layer, vocab_size, **kwargs):
- super(RNNModel, self).__init__(**kwargs)
- self.rnn = rnn_layer
- self.vocab_size = vocab_size
- self.num_hiddens = self.rnn.hidden_size
- self.num_directions = 1
- self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
- 初始化函数接收三个参数
rnn_layer表示RNN层的类型vocab_size表示词表大小**kwargs表示可变数量的关键字参数
- 首先调用父类
nn.Module的初始化函数,然后将传入的rnn_layer赋值给self.rnn,将vocab_size赋值给self.vocab_size。 - 根据
rnn_layer的隐藏状态大小,将其赋值给self.num_hiddens。 self.num_directions表示RNN层的方向数,默认为1。- 最后,创建一个全连接层
self.linear,该层的输入大小为self.num_hiddens,输出大小为self.vocab_size。
2.forward(前向传播)- def forward(self, inputs, state):
- X = F.one_hot(inputs.T.long(), self.vocab_size)
- X = X.to(torch.float32)
- Y, state = self.rnn(X, state)
- output = self.linear(Y.reshape((-1, Y.shape[-1])))
- return output, state
- 前向传播函数接收两个参数
inputs表示输入数据state表示隐藏状态
- 使用
F.one_hot函数将inputs转换为独热编码表示的张量X,- 其中
inputs.T.long()将输入进行转置并转换为整型。
- 其中
- 将
X转换为torch.float32数据类型 - 将
X和state传入RNN层self.rnn进行计算,得到输出Y和更新后的隐藏状态state - 接下来,通过将
Y的形状改变为(-1, Y.shape[-1]),将其展平,并将其输入到全连接层self.linear中,得到最终的输出output。
3.begin_state(初始化隐藏状态)- def begin_state(self, device, batch_size=1):
- if not isinstance(self.rnn, nn.LSTM):
- return torch.zeros((self.num_directions * self.rnn.num_layers,
- batch_size, self.num_hiddens),
- device=device)
- else:
- return (torch.zeros((
- self.num_directions * self.rnn.num_layers,
- batch_size, self.num_hiddens), device=device),
- torch.zeros((
- self.num_directions * self.rnn.num_layers,
- batch_size, self.num_hiddens), device=device))
- 两个参数
device表示计算设备batch_size表示批量大小,默认为1。
- 判断RNN层的类型是否为
nn.LSTM- 如果不是,则返回一个形状为
(num_directions * num_layers, batch_size, num_hiddens)的全零张量作为初始隐藏状态。 - 如果是
nn.LSTM类型,则返回一个由两个元组组成的元组,每个元组包含一个形状为(num_directions * num_layers, batch_size, num_hiddens)的全零张量,用作LSTM层的初始隐藏状态。
- 如果不是,则返回一个形状为
(三)代码整合
- # 导入必要的库
- import torch
- from torch import nn
- import torch.nn.functional as F
- from d2l import torch as d2l
- import math
- class LSTM(nn.Module):
- def __init__(self, input_size, hidden_size):
- super(LSTM, self).__init__()
- self.input_size = input_size
- self.hidden_size = hidden_size
- # 初始化模型,即各个门的计算参数
- self.W_i = nn.Parameter(torch.randn(input_size, hidden_size))
- self.W_f = nn.Parameter(torch.randn(input_size, hidden_size))
- self.W_o = nn.Parameter(torch.randn(input_size, hidden_size))
- self.W_a = nn.Parameter(torch.randn(input_size, hidden_size))
- self.U_i = nn.Parameter(torch.randn(hidden_size, hidden_size))
- self.U_f = nn.Parameter(torch.randn(hidden_size, hidden_size))
- self.U_o = nn.Parameter(torch.randn(hidden_size, hidden_size))
- self.U_a = nn.Parameter(torch.randn(hidden_size, hidden_size))
- self.b_i = nn.Parameter(torch.randn(1, hidden_size))
- self.b_f = nn.Parameter(torch.randn(1, hidden_size))
- self.b_o = nn.Parameter(torch.randn(1, hidden_size))
- self.b_a = nn.Parameter(torch.randn(1, hidden_size))
- self.W_h = nn.Parameter(torch.randn(hidden_size, hidden_size))
- self.b_h = nn.Parameter(torch.randn(1, hidden_size))
- # 初始化隐藏状态
- def init_state(self, batch_size):
- hidden_state = torch.zeros(batch_size, self.hidden_size)
- cell_state = torch.zeros(batch_size, self.hidden_size)
- return hidden_state, cell_state
- def forward(self, inputs, states=None):
- batch_size, seq_len, input_size = inputs.shape
- if states is None:
- states = self.init_state(batch_size)
- hidden_state, cell_state = states
- outputs = []
- for step in range(seq_len):
- inputs_step = inputs[:, step, :]
- i_gate = torch.sigmoid(torch.mm(inputs_step, self.W_i) + torch.mm(hidden_state, self.U_i) + self.b_i)
- f_gate = torch.sigmoid(torch.mm(inputs_step, self.W_f) + torch.mm(hidden_state, self.U_f) + self.b_f)
- o_gate = torch.sigmoid(torch.mm(inputs_step, self.W_o) + torch.mm(hidden_state, self.U_o) + self.b_o)
- c_tilde = torch.tanh(torch.mm(inputs_step, self.W_a) + torch.mm(hidden_state, self.U_a) + self.b_a)
- cell_state = f_gate * cell_state + i_gate * c_tilde
- hidden_state = o_gate * torch.tanh(cell_state)
- y = torch.mm(hidden_state, self.W_h) + self.b_h
- outputs.append(y)
- return torch.cat(outputs, dim=0), (hidden_state, cell_state)
- class RNNModel(nn.Module):
- def __init__(self, rnn_layer, vocab_size, **kwargs):
- super(RNNModel, self).__init__(**kwargs)
- self.rnn = rnn_layer
- self.vocab_size = vocab_size
- self.num_hiddens = self.rnn.hidden_size
- self.num_directions = 1
- self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
- def forward(self, inputs, state):
- X = F.one_hot(inputs.T.long(), self.vocab_size)
- X = X.to(torch.float32)
- Y, state = self.rnn(X, state)
- # 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
- # 它的输出形状是(时间步数*批量大小,词表大小)。
- output = self.linear(Y.reshape((-1, Y.shape[-1])))
- return output, state
- # 在第一个时间步,需要初始化一个隐藏状态,由此函数实现
- def begin_state(self, device, batch_size=1):
- if not isinstance(self.rnn, nn.LSTM):
- # nn.GRU以张量作为隐状态
- return torch.zeros((self.num_directions * self.rnn.num_layers,
- batch_size, self.num_hiddens),
- device=device)
- else:
- # nn.LSTM以元组作为隐状态
- return (torch.zeros((
- self.num_directions * self.rnn.num_layers,
- batch_size, self.num_hiddens), device=device),
- torch.zeros((
- self.num_directions * self.rnn.num_layers,
- batch_size, self.num_hiddens), device=device))
- 基于门控的循环神经网络(Gated RNN)
-
相关阅读:
接口自动化测试
第2次作业
Python实现Token过期自动刷新并重试原请求
【科技素养】蓝桥杯STEMA 科技素养组模拟练习试卷D
用于数据增强的十个Python库
前端ES6-ES11新特性
宏定义实现二进制数的奇偶位交换
【每日一题Day360】LC1465切割后面积最大的蛋糕 | 贪心
Javase | StringBuffer、StringBuilder
JAVAEE初阶相关内容第十三弹--文件操作 IO
- 原文地址:https://blog.csdn.net/m0_63834988/article/details/133864731

 https://blog.csdn.net/m0_63834988/article/details/133778440
https://blog.csdn.net/m0_63834988/article/details/133778440