-
如何使用FME开发自动化分析报告功能
目录
前言
一个标准项目分析报告需要需要包括3个方面:
- 文本叙述,主要体现在对某项专项数据的分布情况,总体情况,分类情况进行描述,需要使用真实数据,能够直观的反馈数据的存在情况。
- 表格展示,使用表格数据展示,能够更加直观的反馈数据的数量,分布,分类情况。
- 专题图展示,一个标准的专题图,需要包括图例、图样、行政区界限等要素,让数据的分布情况一目了然。
按照常规的生产模式,一个分析报告往往涉及多个图层、多种数据、多种维度的数据分析。以城镇国土空间监测项目为例,完成一个分析报告往往需要好几天时间。通过城镇国土空间监测分析报告自动处理方案,能够实现在3分钟以内,完成分析报告的自动化编制,并且能实现无任何逻辑错误,文档和数据库的一致性。
一、使用的技术栈
整套方案整体流程通过FME开发,数据分析通过FME和pandas分析库辅助实现,专题图通过FME和python的opencv库实现,word文档和表格部分通过python-docx库实现。
二、技术难点解析
1.专题图
众所周知,大部分的专题图都是由专业软件Arcgis或者Qgis等制作,需要手动配置图例,样式,文本,颜色,指北针等信息。优点是自定义化程度高,能实现各式各样的专题图制作,缺点也很明显,很难实现自动化图,样式,图例随动的出图,同时也不能和WORD联动,实现自动插图。
FME虽然在出图方面没有arcgis优秀,但其优秀的数据处理和整合能力是无可比拟的。它能让你的逻辑图形化,让你的思维能更加清晰。
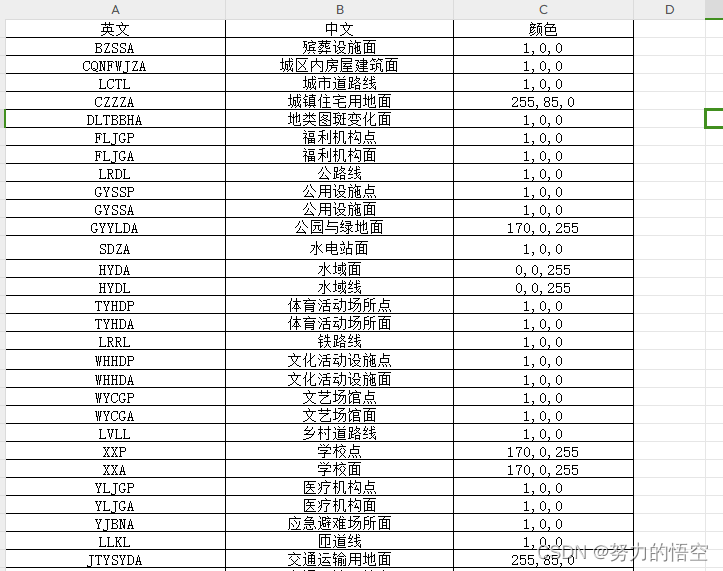
以城镇国土空间监测项目为例,我们先做一个config配置表格,通过该文件实现对图层名称,颜色的配置。
行政区裁剪和环绕文本制作,先上成果图
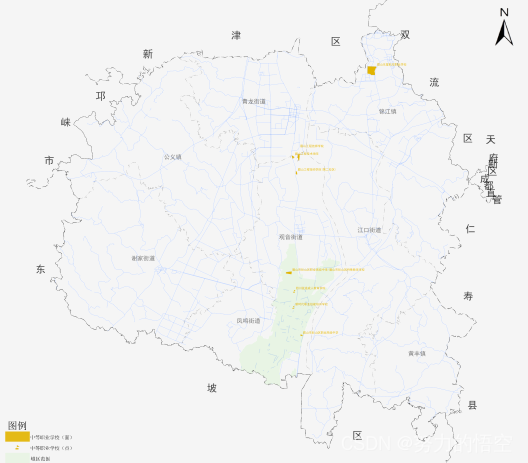
首先我们先说一下如何实现文字环绕的逻辑,其实非常简单,就是将行政区buff后,裁剪当前区域,获得环绕行政区

再通过一系列的数学算法,让文本均匀分布在图形内部,同时保证字的顺序的方向性一致。

然后是就是需要注意字体大小和图形面积是有比例关系的,因为很多样本的图形大小差距很大,将字体大小固定下来的话就很难有适配性,那么就应该通过总面积大小求得一个比例参数,并将该参数发布为全局变量。

文本的固定使用TextStroker转换器实现,该转换器可以将label的点文字注记转换为文本的几何。

考虑到部分要素面积小,要素个数较少,很难在图形上看到分布,则设置一个阈值将文字标记展示出来。

但是这样也会存在一个问题,就是文字注记的压盖,这里我们使用了一个算法,来调整几个文本box的空间位置,让其能较好的分布。整体的逻辑就是使用递归,不断的调整相互重叠字体的位置,来达到比较正常分布。
- import fme
- import fmeobjects
- import copy
- def adjust_boxes(boxes):
- moved_boxes = copy.deepcopy(boxes) # 创建一个副本用于移动
- overlap = True # 初始化重叠标志为True
- while overlap:
- overlap = False
- for i in range(len(boxes)):
- for j in range(i+1, len(boxes)):
- if check_overlap(moved_boxes[i], moved_boxes[j]):
- overlap = True
- move_box(moved_boxes, i, j)
- return moved_boxes
- def check_overlap(box1, box2):
- # 检查两个box是否重叠
- return not (box1[1] < box2[0] or box1[0] > box2[1] or box1[3] < box2[2] or box1[2] > box2[3])
- def move_box(boxes, index1, index2):
- # 移动box2以保证与box1不重叠
- box1 = boxes[index1]
- box2 = boxes[index2]
- x_overlap = min(box1[1], box2[1]) - max(box1[0], box2[0])
- y_overlap = min(box1[3], box2[3]) - max(box1[2], box2[2])
- x_offset = max(box1[1], box2[1]) - min(box1[0], box2[0]) + 1 - x_overlap
- y_offset = max(box1[3], box2[3]) - min(box1[2], box2[2]) + 1 - y_overlap
- if x_offset < y_offset: # 选择较小的偏移方向
- if box1[1] < box2[0]: # box2在box1的右侧
- offset = x_offset
- else: # box2在box1的左侧
- offset = -x_offset
- boxes[index2][0] += offset
- boxes[index2][1] += offset
- else:
- if box1[3] < box2[2]: # box2在box1的上方
- offset = y_offset
- else: # box2在box1的下方
- offset = -y_offset
- boxes[index2][2] += offset
- boxes[index2][3] += offset
- class FeatureProcessor(object):
- """Template Class Interface:
- When using this class, make sure its name is set as the value of the 'Class
- to Process Features' transformer parameter.
- """
- def __init__(self):
- self.features = []
- """Base constructor for class members."""
- pass
- def input(self, feature):
- self.features.append(feature)
- """This method is called for each FME Feature entering the
- PythonCaller. If knowledge of all input Features is not required for
- processing, then the processed Feature can be emitted from this method
- through self.pyoutput(). Otherwise, the input FME Feature should be
- cached to a list class member and processed in process_group() when
- 'Group by' attributes(s) are specified, or the close() method.
- :param fmeobjects.FMEFeature feature: FME Feature entering the
- transformer.
- """
- def close(self):
- """This method is called once all the FME Features have been processed
- from input().
- """
- pass
- def process_group(self):
- boxes = []
- for feature in self.features:
- box = [feature.getAttribute('_xmin'), feature.getAttribute('_xmax'), feature.getAttribute('_ymin'), feature.getAttribute('_ymax')]
- boxes.append(box)
- new_boxes = adjust_boxes(boxes)
- for i,item in enumerate(new_boxes):
- cent_x = (item[0]+item[1])/2
- cent_y = (item[2]+item[3])/2
- self.features[i].setAttribute('cent_x',cent_x)
- self.features[i].setAttribute('cent_y',cent_y)
- for feature in self.features:
- self.pyoutput(feature)
- self.features = []
最后设置好每类要素的透明度,宽度等样式信息,并写入属性中。最终将几何信息和样式信息输出到Matplotlib中,导出png专题图。

用同样的方式制作图例


最后将预设的指北针图标,图例与图形结合,使用PIL库的镶嵌实现,最终构成完整的专题图。

2.WORD文档实现
分析报告和一般的有固定模板的wrod文档批量出具有很大的不同,主要在于其没有固定模板,不能像邮件合并一样在固定位置插入数据。其所有的标题,二级标题,以及表格的样式,行列数都是无法固定的。
2.1 动态标题
标题的添加通过python-docx的add_heading函数实现,通过提前分析计算各图层的标题等级和标题顺序号来完成添加


形成标题成果

2.3动态表格和文本
这里我通过python-docx二次封装了几个函数
1、add_paragraph_to_word(location,text,size,align = None,font_name = None,args = [])函数,能直接添加段落到文档的指定位置,并能设置字体大小,对齐,字体名,args里面可以设置下划线、艺术字、加粗等样式信息。
2、add_df_to_word(word, df)函数,该函数能够直接实现pandas的dataframe对象直接插入到wrod文档中,并自动将标题加粗,文本居中。比如如下代码
- if feature.getAttribute('几何类型') == "线":
- data = {'类型': TYPE, '长度(千米)': LEN ,"要素数量":count}
- else:
- data = {'类型': TYPE, '面积(亩)': LEN ,"要素数量":count}
- df = pd.DataFrame(data)
- name = feature.getAttribute('CCN')
- add_paragraph_to_word(word,"表4-{} {}统计表".format(i_table,name),14,"center","仿宋")
- add_df_to_word(word,df)
df打印如下所示

插入wrod如下所示

2.3专题图插入
使用python-docx自带的add_picture函数实现

三、完成NewGIS部署
在自研平台NewGIS Integration平台完成方案的部署(该平台由我团队自主研发,前端VUE,后端 GoLang,能够实现对FME模板自动化部署,并且支持高并发运行)


导入行政区界限,和成果GDB数据并提交

在成果预览中下载分析报告

点击下载,解压压缩包

完成分析报告的自动化出具

四、模板总览图
总计340个转换器

总结
该方案不单单能应用于城镇国土空间监测项目,能定制开发所有项目的分析报告,包括规划的合规分析,可行性分析,调查监测的变更调查数据库分析报告等等。
-
相关阅读:
临界区(critical section 每个线程中访问 临界资源 的那段代码)和互斥锁(mutex)的区别(进程间互斥量、共享内存、虚拟地址)
leetcode刷题(131)——背包问题理解
nacos
openai-dotnet:OpenAI官方提供的.NET SDK库!
使用Jedis远程连接redis
sqli-labs 靶场闯关基础准备、学习步骤、SQL注入类型,常用基本函数、获取数据库元数据
创建对象内存分析
Mockito单元测试说明
web常见的攻击方式有哪些?如何防御?
[C++](19)AVL树插入,旋转,详细图解与代码
- 原文地址:https://blog.csdn.net/weixin_57664381/article/details/133795367
