-
Python爬虫(二十三)_selenium案例:动态模拟页面点击

本篇主要介绍使用selenium模拟点击下一页,更多内容请参考:Python学习指南
#-*- coding:utf-8 -*- import unittest from selenium import webdriver from selenium.webdriver.common.keys import Keys from bs4 import BeautifulSoup import time class douyuSelenium(unittest.TestCase): #初始化方法 def setUp(self): self.driver = webdriver.PhantomJS(service_args=['--ignore-ssl-errors=true', '--ssl-protocol=any']) #具体的测试用例方法,一定要以test开头 def testDouyu(self): self.driver.get("http://www.douyu.com/directory/all") while True: #指定xml解析 soup = BeautifulSoup(self.driver.page_source, "lxml") #返回当前页面的所有房间标题列表和观众人数列表 titles = soup.find_all('h3' , {'class':"ellipsis"}) print(len(titles)) nums = soup.find_all('span', {'class': "dy-num fr"}) # #使用zip()函数把列表合并,并创建一个远相对的列表[(1, 2), (3, 4)] for title, num in zip(nums, titles): print(u'观众人数: '+num.get_text().strip(), u'\t房间标题: '+title.get_text().strip()) #page_source.find()未找到内容则返回-1 if self.driver.page_source.find('shark-pager-disable-next') != -1: break self.driver.find_element_by_class_name('shark-pager-next').click() time.sleep(1) # 退出时的清理方法 def tearDown(self): print("加载完成...") self.driver.quit() if __name__ == '__main__': unittest.main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
最后
分享一份Python的学习资料,但由于篇幅有限,完整文档可以扫码免费领取!!!

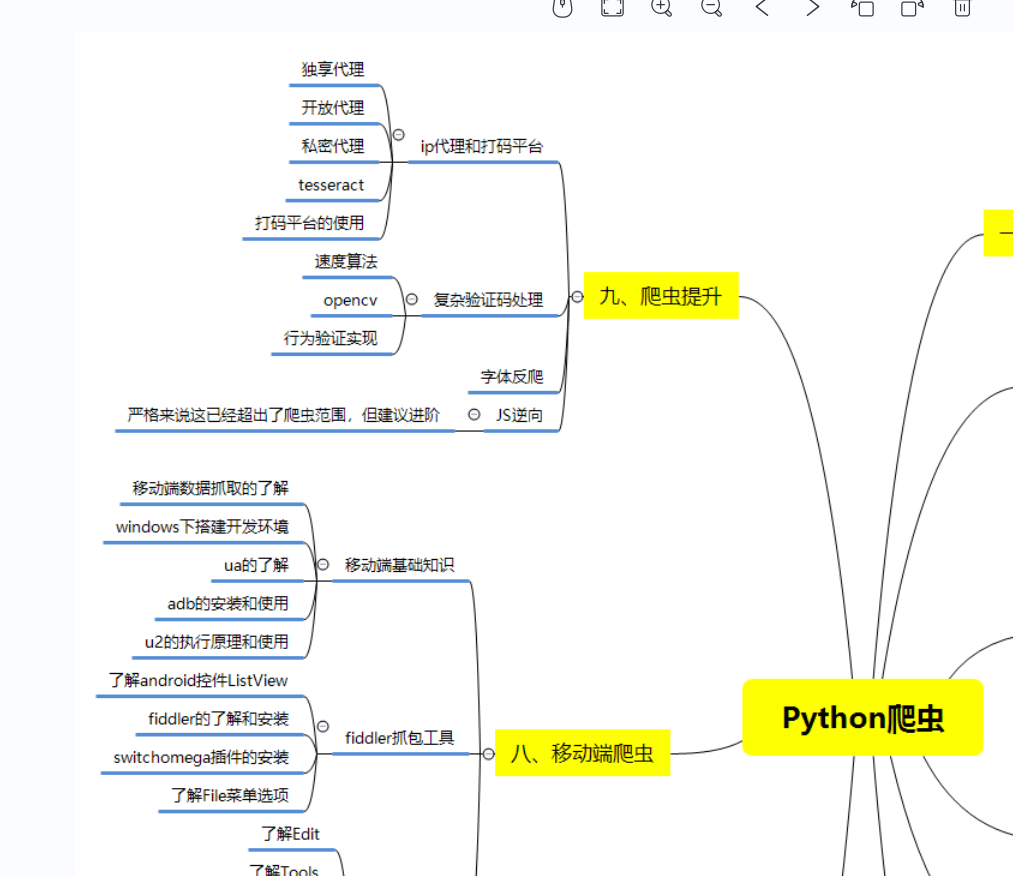
1)Python所有方向的学习路线(新版)
总结的Python爬虫和数据分析等各个方向应该学习的技术栈。

比如说爬虫这一块,很多人以为学了xpath和PyQuery等几个解析库之后就精通的python爬虫,其实路还有很长,比如说移动端爬虫和JS逆向等等。
(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然达不到大佬的程度,但是精通python是没有问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。
。
-
相关阅读:
java代码审计
【BOOST C++ 8 输入输出流】(2)过滤器
Elasticsearch 聚合字段aggregate-metric-double
0基础学习VR全景平台篇第120篇:极坐标处理接缝 - PS教程
【VulnHub靶场】——BOREDHACKERBLOG: SOCIAL NETWORK
唯品会电商api接口
07_ElasticSearch:倒排序索引与分词Analysis
delegate使用方法C#(Demo)
龟速乘【模板】
haproxy+keepalived搭建和配置
- 原文地址:https://blog.csdn.net/javasdn/article/details/133771638
