-
Redis
Redis
Redis_ 找笔记系列
Redis 笔记(13)— scan 和 keys 寻找特定前缀key 字段(命令格式、使用示例、定位大key)_keys 前缀-CSDN博客前半为尚,后面学习黑马Redis
进阶看 :深入学习Redis(1):Redis内存模型 - 编程迷思 - 博客园 (cnblogs.com)
Redis 6.0 新特性 ACL 介绍 - WeihanLi - 博客园 (cnblogs.com)
Redis是什么?
Redis(Remote Dictionary Server ),即远程字典服务。
是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis能该干什么?
- 内存存储、持久化,内存是断电即失的,所以需要持久化(RDB、AOF)
- 高效率、用于高速缓冲
- 发布订阅系统
- 地图信息分析
- 计时器、计数器(eg:浏览量)
- 。。。
特性
- 多样的数据类型
- 持久化
- 集群
- 事务
后端启动Redis:
在
/usr/local/bin/下:redis-cli- 1
Redis关闭
shutdown- 1
再输入
exit退出 且关闭redis
此时服务仅为一个 (共两个)

若此时再次启动redis 拒绝访问

解决:因为此时服务端已关闭,故需要重启Redis服务端:🔽
Redis启动:
需要:在
/usr/local/bin/下:- 开启redis服务端:
redis-server /root/myredis/redis.conf- 1
- 开启客户端:
redis-cli- 1

此时服务有俩

redis的单线程+多路IO复用Redis03——Redis之单线程+多路IO复用技术 - 琥珀呀 - 博客园 (cnblogs.com)
redis基础和使用(三)–单线程与IO多路复用_aizhupo1314的博客-CSDN博客_单线程io多路复用
多路IO复用: (异步阻塞)
- 使用一个线程来检查多个文件描述符的就绪状态
如果有一个文件描述符就绪,则返回; 否则阻塞直到超时
得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(线程池)
可达到在同一个线程内同时处理多个IO请求的目的
IO多路复用机制详解 - 简直😓 - 博客园 (cnblogs.com)
Redis的8个数据类型
Redis 键 (key)
1为真;0为假
键值对的形式
添加数据:
set k1 aaakeys *查看当前库所有key (匹配:keys *1)# 创建一些 key 并赋值 redis> MSET firstname Jack lastname Stuntman age 35 "OK" # 查找含有 name 的 key redis> KEYS *name* 1) "firstname" 2) "lastname" # 查找以 a 为开头长度为 3 的 key redis> KEYS a?? 1) "age" # redis 获取所有的 key 使用 *。 redis> KEYS * 1) "age" 2) "firstname" 3) "lastname"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Redis 千万不要乱用KEYS命令,不然会挨打的 - 兔子托尼啊 - 博客园 (cnblogs.com)
exists key判断某个key是否存在type key查看你的key是什么类型del key删除指定的key数据unlink key根据value选择非阻塞删除-
仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作。
-
unlink:- 惰性删除
lazyfree的机制, - 它可以将删除键或数据库的操作放在后台线程里执行,删除对象时只是进行逻辑删除,从而尽可能地避免服务器阻塞。
- 惰性删除
-
setex<过期时间> -
设置键值的同时,设置过期时间,单位秒。
-
setex ke 30 v1- 1
-
-
expire key 1010秒钟:为给定的key设置过期时间 -
ttl key查看还有多少秒过期,-1表示永不过期,-2表示已过期
select命令切换数据库dbsize查看当前数据库的key的数量flushdb清空当前库flushall通杀全部库Redis的五种(常见)数据类型 指的是其 Value的类型
Redis的所有操作都是原子性的,
要么都成功、要么都失败Redis 字符串 String
-
一个key对应一个value。
-
String类型是二进制安全的。意味着Redis的
string可以包含任何数据。比如jpg图片或者序列化的对象。 -
value 字符串最大为 512M
数据结构:
- 简单动态字符串 (Simple Dynamic String, 缩写 SDS),是可以修改的字符串,
- 内部结构实现上类似于 Java 的
ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.
常用命令:
set添加键值对
get查询对应键值append将给定的 追加到原值的末尾strlen获得值的长度setnx只有在 key 不存在时 设置 key 的值incr将 key 中储存的数字值增1- 只能对数字值操作,如果为空,新增值为1
- 若
key不存在,自动创建value为 0 且 加一,
decr- 将 key 中储存的数字值减1
只能对数字值操作,如果为空,新增值为-1
incrby / decrby将 key 中储存的数字值增减。自定义步长。<步长> mset..... 同时设置一个或多个 key-value对
mget..... 同时获取一个或多个 value

msetnx..... 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。
*原子性,有一个失败则都失败*
getrange<起始位置> <结束位置> 获得值的范围,类似java中的substring,
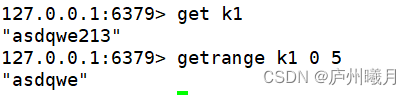
setrange<起始位置> 用 覆写所储存的字符串值,从<起始位置>开始(*索引从0开始*)。

setex<过期时间>
设置键值的同时,设置过期时间,单位秒。
getset以新换旧,设置了新值同时获得旧值。

左边放就是栈了,右边放就是队列
Redis 链表(List)
单键多值: 简单的字符串列表:按照插入顺序排序
-
可以向左边
/右边添加元素 -
底层实现: 双向链表
数据结构
List的数据结构为快速链表quickList。
-
数据较小时:
- 在列表元素较少的情况下会使用一块连续的内存存储,这个结构是
ziplist,也即是压缩列表。
它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
- 在列表元素较少的情况下会使用一块连续的内存存储,这个结构是
-
数据量比较多的时候才会改成quicklist。
-
因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。
Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
-
常用命令
lpush / rpush从左边/右边插入一个或多个值。.... lpush: 头插法:一直在元素的左边插入rpush: 尾插法: 一直在元素的右边插入

-
lpop/rpop从左边/右边吐出一个值。值在键在,值光键亡。- 吐出即删除
-
rpoplpush- 从列表右边吐出一个值,插到列表左边。
- 将
key1的最右边元素 移除;且插入到key2的左边
-
lrange按照索引下标获得元素(从左到右)lrange mylist 0 -10左边第一个,-1右边第一个,(0 -1表示获取所有)
-
lindex按照索引下标获得元素(从左到右) -
llen获得列表长度 -
linsertbefore -
在 value 的前面插入 newvalue 插入值
-
在 1元素前 插入 newWords
-
-
lrem从左边删除n个value(从左到右) Redis Lrem 命令 | 菜鸟教程- Redis Lrem 根据参数 COUNT 的值,移除列表中与参数 VALUE 相等的元素。
- 返回值:被移除元素的数量。 列表不存在时返回 0 。
- COUNT 的值可以是以下几种:
- count > 0 : 从表头开始向表尾搜索,移除与 VALUE 相等的元素,数量为 COUNT。
- count < 0 : 从表尾开始向表头搜索,移除与 VALUE 相等的元素,数量为 COUNT的绝对值。
- count = 0 : 移除表中所有与 VALUE 相等的值。
- COUNT 的值可以是以下几种:
-
lset- 将列表key下标为index的值替换成value
Redis 集合(Set)
无序、不重复
它底层:是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
map,使用键-值对(key-value)存储,查找速度快。
字典是无序的对象集合,元素是通过键来存取的,而不是通过索引值存取。
字典是可变数据类型常用命令
sadd..... 将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略
smembers取出该集合的所有值。sismember判断集合 是否为含有该值,有1,没有0scard返回该集合的元素个数。srem.... - 删除集合中的某个元素。
spop*随机从该集合中吐出一个值。*srandmember随机从该集合中取出n个值。不会从集合中删除 。smove把集合中一个值从一个集合移动到另一个集合sinter返回两个集合的交集元素。sunion返回两个集合的并集元素。sdiff返回两个集合的差集元素 (key1中的,不包含key2中的)Redis 哈希(Hash)
哈希是一个键值对集合;
形如
value=[{field1,value1},...{fieldN,valueN}],String类型的 field 和value 的映射表,适合存储对象
数据结构
Hash类型对应的数据结构是两种:
ziplist(压缩列表),hashtable(哈希表)。- 当field-value长度较短且个数较少时,使用
ziplist,否则使用hashtable。
常见命令
hset- 给集合中的 键赋值
hget- 从集合取出 value
hmset... - 批量设置hash的值
hexists- 查看哈希表 key 中,给定域 field 是否存在。
hkeys列出该hash集合的所有fieldhvals列出该hash集合的所有valuehincrby为哈希表 key 中的域 field 的值加上增量n (可正负)hsetnx- 将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 时生效.
Redis有序集合(Zset)
无重复元素、有序的集合
每个成员都关联了一个评分(score)用来排序成员
成员唯一;评分可以重复
因为元素是有序的, 可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也很快,因此你能够使用有序集合作为一个没有重复成员的智能列表。
数据结构
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
跳跃表:层数是随机生成的…
跳跃表原理 - thrillerz - 博客园 (cnblogs.com)
跳跃表(skip list) - 简书 (jianshu.com)
常用命令
-
zadd… - 将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
-
zrange[WITHSCORES] -
返回有序集 key 中,下标在
之间的元素 带
WITHSCORES,可以让分数一起和值返回到结果集。
-
-
zrangebyscore key min max [withscores] [limit offset count]- 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。
- 有序集成员按 score 值递增(从小到大)次序排列。
-
zrevrangebyscore key max min [withscores] [limit offset count]- 同上,改为从大到小排列。
-
zincrby为元素的score加上增量 -
zrem删除该集合下,指定值的元素 -
zcount- 统计该集合,分数区间内的元素个数
-
zrank返回该值在集合中的排名,从0开始。
Redis Bitmaps
(1) 对字符串的位进行操作。
(2) Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。偏移量是整数!!
常见命令
1、setbit
(1)格式
setbit设置Bitmaps中某个偏移量的值(0或1)offset:偏移量从0开始
2、getbit
(1)格式
getbit获取Bitmaps中某个偏移量的值3、bitcount
统计****字符串****被设置为1的bit数。
(1)格式
bitcount <key> [start end]- 1
- 统计字符串从start字节到end字节比特值为1的数量
4、bitop
(1)格式
bitop and(or/not/xor)[key…] bitop是一个复合操作, 它可以做多个Bitmaps的and(交集) 、 or(并集) 、 not(非) 、 xor(异或) 操作并将结果保存在destkey中。
看了博客好像懂了,就是用这个表示每一个用户的状态,比如是否愿意收到邮件,用512MB就可以表示40亿用户每个人的选择
交集 :
bitop and 【随意取名】 key1 key2并集:
bitop or【随意取名】 key1 key2Redis HyperLogLog
-
这个无法查看值,它就是用来计算基数的,如果可以看值那和set就没差别了
-
不存放值 只计算基数 估计会有个标识来记录是否存在 占用内存小
-
HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
-
用于 求集合中不重复元素个数的问题,即基数问题。
UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题。
即 同一ip访问网站只记一个用户访问
比如: 数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
常用命令
1、pfadd
(1)格式
pfadd添加指定元素到[element ...] HyperLogLog中- 将所有元素添加到指定HyperLogLog数据结构中。如果执行命令后HLL估计的近似基数发生变化,则返回1,否则返回0。
2、pfcount
(1)格式
pfcount计算HLL的近似基数,可以计算多个HLL,[key ...] - 比如用HLL存储每天的UV,计算一周的UV可以使用7天的UV合并计算即可
3、pfmerge
(1)格式
pfmerge**将一个或多个HLL合并后的结果存储在另一个HLL中,**比如每月活跃用户可以使用每天的活跃用户来合并计算可得[sourcekey ...] Redis Geospatial
该类型,就是元素的2维坐标,在地图上就是经纬度。
redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
常见命令
-
geoadd添加地理位置(经度,纬度,名称)[longitude latitude member...] - 两极无法直接添加,一般会下载城市数据,直接通过 Java 程序一次性导入。
- 有效的经度从 -180 度到 180 度。
- 有效的纬度从 -85.05112878 度到 85.05112878 度。
- 当坐标位置超出指定范围时,该命令将会返回一个错误。
- 已经添加的数据,是无法再次往里面添加的。
-
geopos获得指定地区的坐标值[member...] -
geodist获取两个位置之间的直线距离[m|km|ft|mi ] -
单位:
- m 表示单位为米[默认值]。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺。
-
-
georadius< longitude> radius m|km|ft|mi - 以给定的经纬度为中心,找出某一半径内的元素
-
GEOHASH key member [member ...]- 用于获取一个或多个位置元素的 geohash 值。
redis的配置文件:
- bind=127.0.0.1 注释掉
protected-mode将本机访问保护模式设置no- port: 6379
bind:是绑定本机的IP地址,(准确的是:本机的网卡对应的IP地址,每一个网卡都有一个IP地址),而不是redis允许来自其他计算机的IP地址。
Redis学习总结(5)之redis.conf配置文件说明_jokeMqc的博客-CSDN博客_redis.conf
注意配置文件里的持久化路径dir ./一定要修改成绝对路径,否则redis会在你启动redis-server的位置读取/存储持久化文件
123456
redis设置、查看密码
#查看密码: config get requirepass #设置密码: config set requirepass- 1
- 2
- 3
- 4
如何查看redis密码及修改 - 腾讯云开发者社区-腾讯云 (tencent.com)
(79条消息) Redis设置密码,查看密码,修改密码,忘记密码。_JerryKit的博客-CSDN博客
Jedis
连接超时:
-
配置文件修改 bind和protected
-
关闭防火墙 或开放 6379端口
- 你不想关闭也没事,开放防火墙的端口
firewall-cmd --zone=public --add-port=6379/tcp --permanentfirewall-cmd --permanent --add-port=6379/tcp
-
开放端口还不可以的重启一下防火墙:sudo firewall-cmd --reload
-
如果之前设置过密码的话,要在创建对象后设置auth
手机输入且发送时,系统发出验证码
比较系统验证码 与 输入的验证码
整合Springboot
RedisTemplate集合使用说明-opsForList(二)_椰汁菠萝-CSDN博客_redis rightpop
Springboot 所有的配置类,都有一个自动配置类;
自动配置类都会绑定一个
XXXProperties的配置类 可通过 配置文件修改其属性的值过时用这个 om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, DefaultTyping.NON_FINAL);
定制
RedisTemplate的模板:尚硅谷
@EnableCaching @Configuration public class RedisConfig extends CachingConfigurerSupport { @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { // 将 template 泛型直接设置为:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
"\"qff=\"""是json序列化的产物
2023年7月3日19:38:31
黑马:
@Configuration public class RedisConfig { @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){ // 创建RedisTemplate对象 RedisTemplate<String, Object> template = new RedisTemplate<>(); // 设置连接工厂 template.setConnectionFactory(connectionFactory); // 创建JSON序列化工具 GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer(); // 设置Key的序列化 template.setKeySerializer(RedisSerializer.string()); template.setHashKeySerializer(RedisSerializer.string()); // 设置Value的序列化 template.setValueSerializer(jsonRedisSerializer); template.setHashValueSerializer(jsonRedisSerializer); // 返回 return template; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
自定义Redis工具类
使用RedisTemplate需要频繁调用.opForxxx然后才能进行对应的操作,这样使用起来代码效率低下,工作中一般不会这样使用,而是将这些常用的公共API抽取出来封装成为一个工具类,然后直接使用工具类来间接操作Redis,不但效率高并且易用。
工具类参考博客:
https://www.cnblogs.com/zeng1994/p/03303c805731afc9aa9c60dbbd32a323.html
https://www.cnblogs.com/zhzhlong/p/11434284.html
————————————————
版权声明:本文为CSDN博主「每天进步一點點」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/DDDDeng_/article/details/108118544Redis 事务 锁机制秒杀
事务
- 定义: 单独的隔离操作:
- 事务中的所有命令都序列化、按顺序进行且 事务在执行过程中,不会被其他客户端发送来的命令请求所打断
- 作用: 串联多个命令防止别的命令插队
(14条消息) NoSQL数据库Redis支持的简单事务_猿人小郑的博客-CSDN博客
事务的三命令:
Multi 、 Exec 、discard- 1
-
从输入
Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行, -
直到输入
Exec后,Redis会将之前的命令队列中的命令依次执行。 -
组队的过程中可以通过
discard来放弃组队。- 若在组队阶段 出错 则都不执行

-
若 执行阶段某命令出错,则仅是报错的命令不执行,其他的都执行;不回滚

-
这就好像是编译时异常和运行时异常。
- 编译时异常就全没了,
- 运行时异常就只没有出错那句
即使是多个任务,但操作redis始终是单线程。因此不会出现“同时”两个线程,操作一个redis数据
乐观锁和悲观锁
【BAT面试题系列】面试官:你了解乐观锁和悲观锁吗? - 编程迷思 - 博客园 (cnblogs.com)
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
每次操作都上锁,别人不能操作;待锁释放后才可进行
一般数据库本身锁的机制都是基于悲观锁的机制实现的;
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号、CAS(比较合适交换)机制 (Redis 使用的是版本号)。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的。
乐观锁 允许多个请求同时访问数据,同时也省掉了对数据加锁和解锁的过程,这种方式因为节省了悲观锁加锁的操作,所以可以一定程度的的提高操作的性能,
乐观锁Redis应用
WATCH key [key ...]
监视之后,若事务执行之前 key已被其他人操作,则事务中断
UNWATCH
取消 WATCH 命令对所有 key 的监视。
如果在执行 WATCH 命令之后,EXEC 命令或DISCARD 命令先被执行了的话,那么就不需要再执行UNWATCH 了。
-
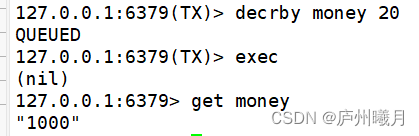
正常执行:

-
存在 别人 抢先操作(插队)

此时模拟线程插队:

回到线程1 执行事务:
锁的应用场景
如果悲观锁和乐观锁都可以使用,那么选择就要考虑竞争的激烈程度:
- 当竞争不激烈 (出现并发冲突的概率小)时,乐观锁更有优势,因为悲观锁会锁住代码块或数据,其他线程无法同时访问,影响并发,而且加锁和释放锁都需要消耗额外的资源。
- 当竞争激烈(出现并发冲突的概率大)时,悲观锁更有优势,因为乐观锁在执行更新时频繁失败,需要不断重试,浪费CPU资源。
Redis事务三特性
Redis的单条命令是保证原子性的,但是redis事务不能保证原子性
-
不保证原子性
- 事务中有命令执行失败、其他命令仍会执行
-
顺序性
- 事务中的所有命令都会序列化、按顺序执行,
-
排他性:
- 不被其他客户端发送来的命令请求所打断。
-
一次性
- 队列中的命令在提交
exec后再 被执行
- 队列中的命令在提交
Redis事务原子性
面试官:Redis的事务满足原子性吗? - 码农参上 - 博客园
事务:
- 存在语法错误的情况下,所有命令都不会执行 –仅保证该程度的原子性
- 存在运行错误的情况下,除执行中出现错误的命令外,其他命令都能正常执行。 此时不会原子性。
lua脚本:
- redis 在执行 一个lua脚本时,其他的脚本不能插入,打断 。 –仅保证该程度的原子性
- 但如果lua脚本 执行时某行命令报错,报错之前的写命令正常执行,不会回滚,不能保证向数据库一样的原子性。
Redis 持久化
RDB
-
定义:Redis DataBase (Rdb)
- 在指定时间间隔后,将内存中的数据集快照写入数据库 ;
- 在恢复时候,直接读取快照文件,进行数据的恢复 ;
默认情况下, Redis 将数据库快照保存在名字为 dump.rdb的二进制文件中。文件名可以在配置文件中进行自定义。
dump.rdb 默认保存在Redis的路径:
/usr/local/bin -
触发机制
- 满足
save命令规则 - 执行
flushdb - 退出Redis
- 满足
-
原理:
-
主线程 生成fork (子线程)将数据写至临时文件,待持久化完成后,再去替换上次已持久化的文件。
-
整个过程中,**主进程是不进行任何IO操作的,**这就确保了极高的性能 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
-
save命令讲解:
-
是同步命令;会占用Redis主进程;当redis的数据很多时,会阻塞客户端请求
-
save 300 100- 1
-
After 300 seconds if at least 100 key changed
-
每一个 300s 内 出现 >=100 个key被修改,则进行持久化到 dump.rdb 文件
-
-
还是推荐
bgsave:Redis会在后台异步进行快照操作, 快照同时还可以响应客户端请求。 -
bgsave和save对比
命令 save bgsave IO类型 同步 异步 阻塞? 是 是(阻塞发生在fock(),通常非常快) 复杂度 O(n) O(n) 优点 不会消耗额外的内存 不阻塞客户端命令 缺点 阻塞客户端命令 需要fock子进程,消耗内存
-
-
RDB:
-
优点:
- 适合大规模的数据恢复
- 对数据的完整性要求不高
-
缺点:
- 在最后一次持久化容易数据 丢失(当未达到持久化的条件或正在持久化时,突然断电)
- fork进程的时候,会占用一定的内容空间。
RDB的备份
先通过config get dir 查询rdb文件的目录
将
dump.rdb的文件拷贝到别的地方rdb的恢复
-
关闭Redis
-
先把备份的文件拷贝到工作目录下 cp dump2.rdb dump.rdb
-
启动Redis, 备份数据会直接加载
这是save命令产生的dump文件,当达到60s 执行5次修改的规则,会自行执行bgsave命令
大家注意了,这里就算你只set一条数,但是你使用了shutdow正常关闭服务器还是会在后台自动执行save命令对数据进行持久化操作,下次你再重启还是能看到那一条数据 并未丢失
-
他那样==直接修改配置文件估计得重启redis才会有效==,我和他一样得方式修改重启后才生效,如果通过客服端直接修改可能可以直接生效(这个没试验过),
-
,生成得rdb文件是由save生成的,save其实也能生成rbd文件,只不过不是由子进程生成,而是直接由服务器生成,关于这点书上有说。
-
flushdb本身其实是不会生成rdb文件的
-
flushall是会生成,但是flushdb自己本身是不会生成
save命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止在此期间服务器不能处理任何命令的请求
AOF
-
定义: 以日志的形式记录每个 写操作 (读操作不记录);只允许追加文件、不可修改aof 文件
-
数据恢复
- 通过redis 重启会将 aof的文件的 写的指令都执行一遍达到数据恢复
-
AOF 默认不开启
- aof文件 与RDB 的文件 保存路径一致
-
AOF和RDB同时开启,系统默认读取AOF文件的数据(数据不会存在丢失)
AOF的备份
-
修改配置文件默认的
appendonly no,改为yes -
将有数据的aof文件复制一份保存到对应目录
-
重启 redis
AOF异常恢复
如果这个aof文件有错位,这时候redis是启动不起来的,我需要修改这个aof文件
redis给我们提供了一个工具
redis-check-aof --fixbin 目录下
redis-check-aof--fix appendonly.aofAOF同步频率设置
appendfsync always 始终同步,每次Redis的写入都会立刻记入日志;性能较差但数据完整性比较好 appendfsync everysec 每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。 appendfsync no redis不主动进行同步,把同步时机交给操作系统。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
优劣点:
缺点:
比起RDB占用更多的磁盘空间。
恢复备份速度要慢。
每次读写都同步的话,有一定的性能压力。
存在个别Bug,造成恢复不能。
主从复制
主从复制基于rdb文件的 不关aof rdb不会生效
-
定义:
- 将主服务器数据 复制到其他的从 服务器
- 数据的复制是单向的!只能由主节点复制到从节点(主节点以写(Master)为主、从节点以读(Slave)为主)。
- 默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
-
作用:
-
读写分离
- 主服务器专门写、从服务器 负责读

-
容灾快速恢复
- 如果 主服务器坏了 解决方法: 集群
-
一主二从配置

conf
#引入原配置文件 include /root/myredis/redis.conf #Pid文件名字 pidfile /var/run/redis_6380.pid # 端口号 port 6380 # 设置 RDB文件 dbfilename dump6380.rdb- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
ps -ef |grep redis # 查看redis的进程是否启动- 1
- 2
info replication #打印主从复制的相关信息- 1
- 2
- 三者默认都为主机

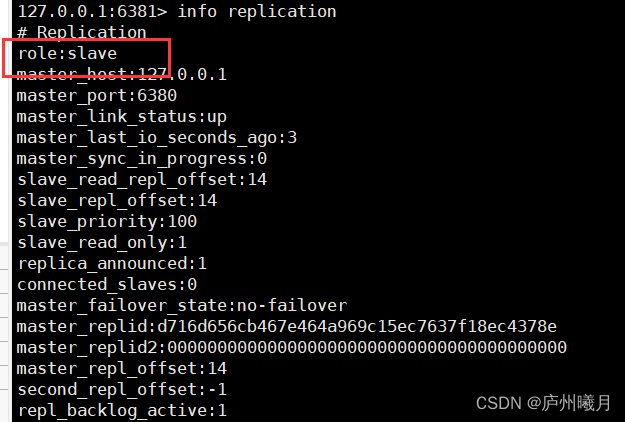
配置从服务器
slaveof <主机ip> <主机port> slaveof 127.0.0.1 6380- 1
- 2
- 3
成为某主机的从机
如果从机挂掉;又变成主机则需要重设为从机
可以将配置增加到文件中。永久生效。
- 从机只能读,不能写,主机可读可写但是多用于写

一主二仆

- 如果主机挂掉;则从机不会上位成主机
- 如果主机又回来了;主机仍为主机
-
当主机断电宕机后,默认情况下从机的角色不会发生变化 ,集群中只是失去了写操作,
- 当主机恢复以后,又会连接上从机恢复原状

-
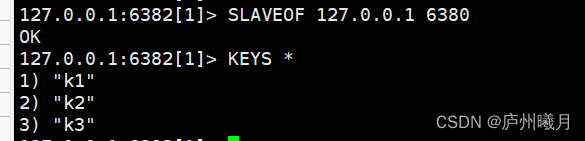
当从机断电宕机后,
- 若不是使用配置文件配置的从机,再次启动后作为主机是无法获取之前主机的数据的,

- 若此时重新配置称为从机,又可以获取到主机的所有数据。这里就要提到一个同步原理。
-
复制原理:
-
Slave启动成功连接到master后会发送一个sync命令
-
此时为第一次请求 : 从机主动向主机请求
-
Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令, 在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
-
全量复制:
-
而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
-
增量复制:
-
Master继续将新的所有收集到的修改命令依次传给slave,完成同步
-
但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
-
此后都是 主机主动向从机发送更新指令
-

- 操作完后的 主机配置文件

薪火相传
一个从机也可以有 从机的从机
上一个Slave可以是下一个slave的Master,
Slave同样可以接收其他 slaves的连接和同步请求,
那么该slave作为了链条中下一个的master,
可以有效减轻master的写压力,去中心化降低风险。

风险是一旦某个slave宕机,后面的slave都没法备份
主机挂了,从机还是从机,无法写数据了
反客为主
- 当 主机宕机后 ,从机可升为主机
slaveof no one- 从节点断开复制后,不会删除已有的数据,只是不再接受主节点新的数据变化。
哨兵模式
- 哨兵检测到主机挂掉(出现故障等)之后根据投票数自动将从机升为主机
作用
哨兵::在复制的基础上,哨兵实现了自动化的故障恢复。
缺陷:写操作无法负载均衡;存储能力受到单机的限制。
哨兵的核心配置
sentinel monitor mymaster 127.0.0.1 6380 1- 1
-
该哨兵节点 监控
127.0.0.1 6380这个主节点,主节点的名称为mymaster -
1表示 至少要有一个哨兵节点同意,才能判定哨兵节点故障时 进行故障转移
启动哨兵
执行 redis-sentinel /root/myredis/testMaster/sentinel.conf- 1

- 当主机挂掉,从机选举中产生新的主机
此时 6382转为 主机;6380、6381为从机
哨兵系统的搭建过程,有几点需要注意:
(1)哨兵系统中的主从节点,与普通的主从节点并没有什么区别**,故障发现和转移是由哨兵来控制和完成的。**
(2)哨兵节点本质上是redis节点。
(3)每个哨兵节点,只需要配置监控主节点,便可以自动发现其他的哨兵节点和从节点。
(4)在哨兵节点启动和故障转移阶段,各个节点的配置文件会被重写(config rewrite)。
(5)本章的例子中,一个哨兵只监控了一个主节点;实际上,一个哨兵可以监控多个主节点,通过配置多条sentinel monitor即可实现。

选拔新主机的机制
-
优先级在redis.conf中默认:
slave-priority 100,值越小优先级越高 -
偏移量是指获得原主机数据最全的
-
每个redis实例启动后都会随机生成一个40位的runid
Redis 集群
redis-cli --cluster命令Redis 5.0 redis-cli --cluster help说明 - jyzhou - 博客园去中心化: 任意 一主机 写的数据;其他主从机都可读到数据
即使连接的不是主机,集群会自动切换主机存储。主机写,从机读。
主机: redis6380 redis6381 redis6382
从机: redis6390 redis6391 redis6392
vim 替换
:%s/6379/6380没有生成nodes文件的,用kill -9 端口号 杀掉进程,再重新启动redisXXX.conf
集群只实现了主节点的故障转移;从节点故障时只会被下线,不会进行故障转移。
使用集群时,应谨慎使用读写分离技术,因为从节点故障会导致读服务不可用,可用性变差。
六个服务组合
-
组合之前,请确保所有redis实例启动后,nodes-xxxx.conf文件都生成正常。
-
合体:
- 在
/root/下载/redis-6.2.6/src下
- 在
执行命令:
redis-cli --cluster create --cluster-replicas 1 192.168.200.130:6380 192.168.200.130:6381 192.168.200.130:6382 192.168.200.130:6390 192.168.200.130:6391 192.168.200.130:6392- 1
- 1不代表以最简单方式,1代表从机数量。语法是这样的 --cluster-replicas
- 选项
--cluster-replicas 1表示我们希望为集群中的每个主节点创建一个从节点。
- 选项
此处不要用127.0.0.1, 请用真实IP地址

登录Redis
redis-cli -c -p 6380- 1
- -c 采用集群策略连接,设置数据会自动切换到相应的写主机
cluster nodes- 1
- 查看集群信息

分配六个节点
一个集群至少要有三个主节点。
选项
--cluster-replicas 1表示我们希望为集群中的每个主节点创建一个从节点。分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
slots(插槽)
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个,
集群使用公式
CRC16(key) % 16384来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。集群中的每个节点(数据库)负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
节点 A 负责处理 0 号至 5460 号插槽。 节点 B 负责处理 5461 号至 10922 号插槽。 节点 C 负责处理 10923 号至 16383 号插槽。- 1
- 2
- 3
插槽: Redis集群中,key存放在slot中,而不是指定到某个Redis节点。
好处:若某个节点宕机,插槽上的key会转入其余节点。
数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
在集群中录入值
-
直接
set;此时集群会计算 该key属于哪个卡槽 -
在使用:
mset、mget时,卡槽需要一致:- 通过{ }来定义组
- 使key中{ }内相同内容;使得多个
key放到一个slot中去
查询集群中的值
-
clust keyslot k1- 1
-
查找 k1 在哪个插槽
-
cluster countkeysinslot 126706- 1
count keys in slot:即 12706插槽下有多少key
-
cluster getkeysinslot 13270 10- 1
get keys in slot:即 列举 13270插槽下 的10个值

故障恢复
- 如果主节点下线; 从节点能否自动升为主节点?注意:15秒超时
15秒超时是:在十五秒内,重启好,还是主机,否则就是从机。
因为集群中的每个数据库复制某段插槽;
- 若某一段插槽的主从节点都宕掉,redis服务是否还能继续?
- ·看配置:
- 配置中 :
cluster-require-full-coverage为yes:,整个集群都挂掉 cluster-require-full-coverage为no:,仅该段插槽挂掉 不能使用,也无法存储。
- 配置中 :
集群的Jedis开发
public class JedisClusterTest { public static void main(String[] args) { Set<HostAndPort>set =new HashSet<HostAndPort>(); set.add(new HostAndPort("192.168.31.211",6379)); // set : 可加多个数据库 JedisCluster jedisCluster=new JedisCluster(set); jedisCluster.set("k1", "v1"); System.out.println(jedisCluster.get("k1")); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
常见问题:
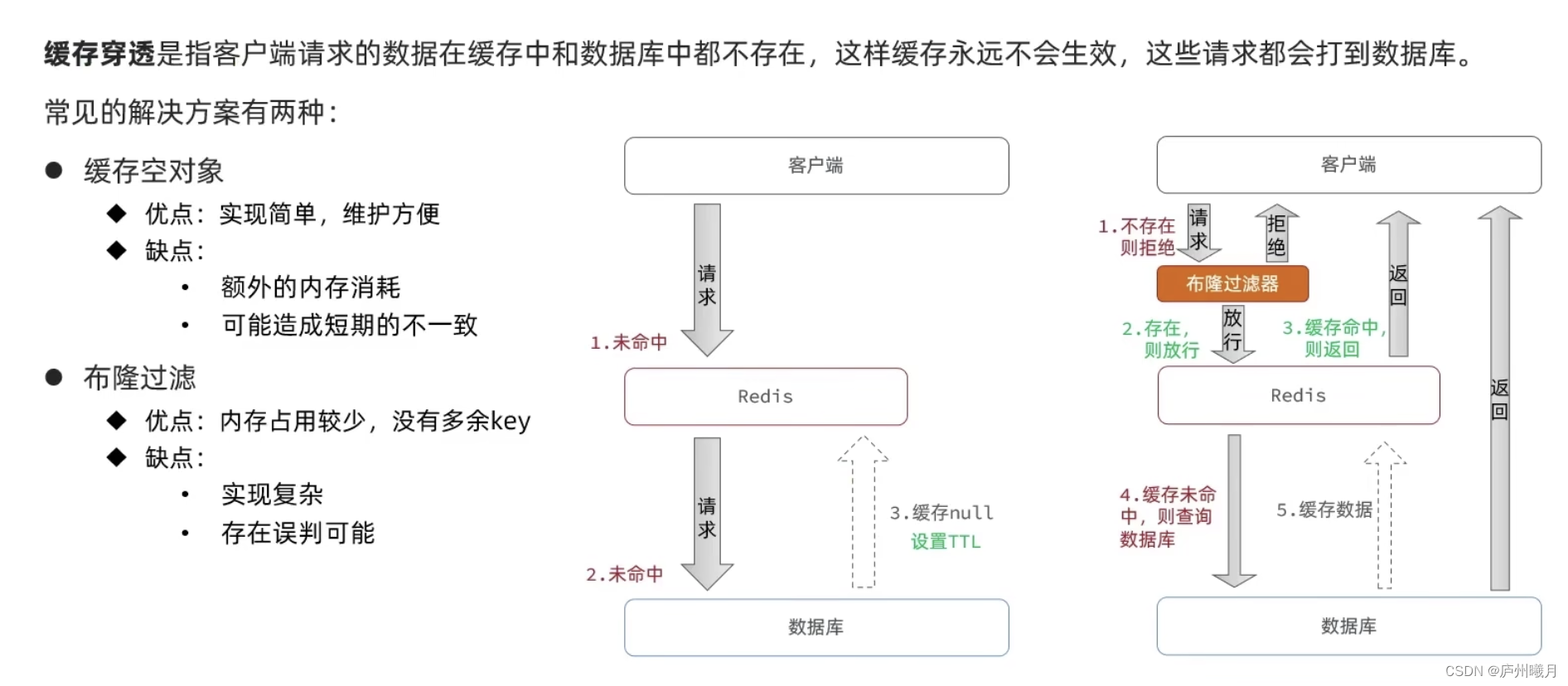
缓存穿透(查不到)
因为都查不到,所以给透了
-
缓存穿透是指缓存和数据库中都没有的数据
- 每次用户请求的数据在
redis查不到 (redis的命中率降低),只能都去请求数据库,使得缓存失效。导致压垮数据库
- 每次用户请求的数据在
-
为什么查不到缓存,应为你数据库的数据没有全部在redis缓存中,请求进来,还是要去数据库查询的
-
解决方案:
-
(1)对空值缓存:如果一个查询返回的数据为空(不管是数据是否不存在),我们仍然把这个空结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过五分钟
-
(2) 设置可访问的名单(白名单):
使用
bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量(数组的下标在Bitmaps中叫做偏移量),每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问。 -
(3) 采用布隆过滤器:(布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。
- 用于检索一个元素是否在一个集合中。
- 它的优点是空间效率和查询时间都远远超过一般的算法,
- 缺点:
有一定的误识别率和删除困难。- 布隆过滤器与数据库数据的操作原子性无法保证。
- eg:数据库数据改动,布隆过滤器无法删除数据,导致不一致
- 布隆过滤器,这一篇给你讲的明明白白-阿里云开发者社区 (aliyun.com)
-
(4) **进行实时监控:**当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
-
预防做法: 黑马:
- 增强对请求数据的校验,比如id > o
- 增强对数据格式的控制,比如 id设置为10位,不为10位的请求直接拒绝
- 增强用户权限校验
- 通过限流来保护数据库
- 缓存穿透,如果是秒杀这种场景,面对软件刷的话,我们做的时候发现缓存null值(针对同key)和用布隆(针对不同key)都不是特别好,因为请求还是进入到系统了。
- 在上层用nginx+lua脚本,对ip进行封禁,比如5秒内,请求超过多少次的ip,直接拉黑。优点是外部解决,缺点是需要在redis缓存大量的ip地址。
- 使用bitmap来解决缓存穿透的方案
我们可以将数据库的数据,所对应的所有用户id写入到一个list集合中,当用户过来访问的时候,我们直接去判断list中是否包含当前的要查询的数据,如果说用户要查询的id数据并不在list集合中,则直接返回,如果list中包含对应查询的id数据,则说明不是一次缓存穿透数据,则直接放行。
-
-
现在的问题是这个主键其实并没有那么短,而是很长的一个 主键。哪怕你单独去提取这个主键,但是在11年左右,淘宝的商品总量就已经超过10亿个。所以如果采用以上方案,这个list也会很大,所以我们可以使用bitmap来减少list的存储空间
-
把list数据抽象成一个非常大的bitmap,我们不再使用list,而是将db中的id数据利用哈希思想,比如:
- id % bitmap.size = 算出当前这个id对应应该落在bitmap的哪个索引上,然后将这个值从0变成1,然后当用户来查询数据时,此时已经没有了list,让用户用他查询的id去用相同的哈希算法, 算出来当前这个id应当落在bitmap的哪一位,然后判断这一位是0,还是1,如果是0则表明这一位上的数据一定不存在, 采用这种方式来处理,需要重点考虑一个事情,就是误差率,所谓的误差率就是指当发生哈希冲突的时候,产生的误差。

- id % bitmap.size = 算出当前这个id对应应该落在bitmap的哪个索引上,然后将这个值从0变成1,然后当用户来查询数据时,此时已经没有了list,让用户用他查询的id去用相同的哈希算法, 算出来当前这个id应当落在bitmap的哪一位,然后判断这一位是0,还是1,如果是0则表明这一位上的数据一定不存在, 采用这种方式来处理,需要重点考虑一个事情,就是误差率,所谓的误差率就是指当发生哈希冲突的时候,产生的误差。
缓存击穿:
解决方案丶黑马
-
定义:
- 一个
key对应的数据此时过期;同时又有大量请求访问这个key的值; 只能都访问DB数据库
- 一个
-
原因:这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮,来不及回设
-
解决方法:
-
**(1)预先设置热门数据:**在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长
-
**(2)实时调整:**现场监控哪些数据热门,实时调整key的过期时长
-
(3)使用加互斥锁(分布式锁)锁:
-
在缓存失效的时候(判断拿出来的值为空),不是立即去load db。
-
(1) 先使用缓存工具的原子性操作(比如Redis的SETNX)去set一个mutex key
(2) 当操作返回成功时,再进行load db的操作(抢到锁),并回设缓存,最后删除mutex key;
(3) 当操作返回失败,证明有线程在load db(抢锁失败),当前线程睡眠一段时间再重试整个get缓存的方法。
-
-
黑马:
-
互斥锁:缓存过期。只有一个线程去重建该缓存,其余线程如果没有获得到,则休眠,过一会再进行尝试,直到获取到锁为止,才能进行查询
-
具体做法:使用redis的
SETNX原子操作新增key 充当加锁; 使用del 删除key 充当 解锁。 -
// Redis 使用 setnx 加锁。 private boolean tryLock(String key) { Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS); return BooleanUtil.isTrue(flag); } private void unlock(String key) { stringRedisTemplate.delete(key); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
一致性强,但容易不可用。
-
-
逻辑过期: 该key永不过期,value 另设个属性 记录过期时间,若缓存过期,返回旧数据,创建新的子线程获得锁去更新缓存。重置过期时间。
- 其余线程发现过期会尝试获取锁,若失败则仍返回过期的数据。 否则开启新线程异步更新缓存。
逻辑过期:
存数据的时候,给数据加上逻辑过期的字段
可用性强,不保证一致性
[逻辑删除代码](#Redis 工具类封装)
-
-

优缺点:
击穿与穿透的区别
- 击穿是热频key过期了,然后就一直访问数据库,
- 穿透是大量的无效访问,缓存中没有,增大服务器压力
缓存雪崩
-
定义: 大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
-
解决方案
-
解决方案:
(1) **构建多级缓存架构:**nginx缓存 + redis缓存 +其他缓存(ehcache等)
(2) 使用锁或队列**:**
用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
(3) 设置过期标志更新缓存:
记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
(4) 将缓存失效时间分散开:
比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
-
击穿与雪崩
缓存雪崩与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key
redis分布式锁
(70条消息) 如何用Redis实现分布式锁_redis分布式锁_GeorgiaStar的博客-CSDN博客
- 背景:
Redis集群之后,锁只对当前节点有效;对其他节点无效。
需要一种跨JVM的互斥机制来控制共享资源的访问
分布式锁特点之一就是互斥性,所以锁必须唯一。

- 方式一
- 添加key 就使用
setnx
- 添加key 就使用
setnx- 1
del k1- 1
该命令用于在 key 存在时删除 key。
-
方式一的问题:
- 若 该锁一直没有释放;导致key无法更新
解决方法:
expire key time- 1
该命令去 设置 key的有效时间;
-
存在的问题: 不是原子操作,但若🔒加上之后节点宕机;就尴尬了
-
方式三:
- 方式一的解决方法:
- 既上锁 又设置时间
set users 10 nx ex 20- 1
- setex 不可上锁,
- 因为上锁,是需要锁不存在的情况下才能上锁成功。
- 而setex可以对已有的key进行覆盖
分布式指的是java服务器是多个的,多个分布的java服务器共同操作一个变量,使用setnx来判断那个变量当前状态
分布式锁是给部署在多台服务器上的java程序同步用的,不是给redis集群用的
a先拿到锁,还没操作完,因为服务器故障,被自动释放,这时候b拿到锁,执行操作几秒后,a那边又开始执行操作,操作完成后,需要手动释放锁,此时锁被b拿着,所以只能释放b的锁
锁的值value 是uuid
锁上的key为 num 记录的是每次加一
uuid是为每个不同阶段的上锁生成的
而 判断 uuid 与锁的uuid 是否相等 是判断 是不是这个锁的uuid

Redis新特性:
Redis 6.0 新特性 ACL 介绍 - WeihanLi - 博客园 (cnblogs.com)****
黑马
Redis 共享Session
解决方法:
使用Redis统一存储用户信息或手机验证码。登录、注册去统一访问Redis 。
存储用户信息
Key: 随机生成token作为key,不拼接用户信息,
Value:
将user信息存入Redis,则Value结构采用Hash,hash可对用户信息动态修改。而string结构 则需要对整个JSON字符串进行替换。

注意事项
- 存入Redis 需要设置过期时间
- 已经登录的用户,对每个路径需要进行刷新用户的
过期时间 - TTL

ThreadLocal用户信息在后端可以使用
ThreadLocal来存储当前线程的用户信息。(可将不同用户之间进行屏蔽)(68条消息) ThreadLocal 常见使用场景_threadlocal使用场景_lsz冲呀的博客-CSDN博客
public class UserHolder { private static final ThreadLocal<UserDTO> tl = new ThreadLocal<>(); public static void saveUser(UserDTO user){ tl.set(user); } public static UserDTO getUser(){ return tl.get(); } public static void removeUser(){ tl.remove(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
缓存一致性
三种思路:
- redis缓存在 数据库更新后,随之更新缓存。 ✅
- 将数据库和缓存统一由服务A维护,使用者将数据写入该服务,由该服务维护两者的一致性。 服务不太好实现。
- 先更新缓存,随后 使用异步线程定时将缓存持久化到数据库。 如果缓存宕机,则数据丢失。
缓存与数据库的三个问题:
-
删除缓存还是更新缓存?
- 删除缓存。 频繁更新缓存,存在无效写操作。应该在更新数据库数据后直接替换缓存数据。
-
如何保证缓存与数据库的数据原子性?(同时成功或失败)
- 单一系统: 缓存与数据库 放在一个事务
- 分布式系统:TCC 分布式事务
-
先操作缓存还是先操作数据库?
-
先删缓存,再更新数据库:
- 删除缓存,更新数据库,添加到缓存。
- 删除缓存后, 线程2发现缓存被删,则将数据库的旧数据存入redis,随后数据库更新数据,容易出现不一致情况。
-
先更新数据库再删除缓存:✅
- 更新 数据库,删掉缓存,写入缓存
- 当且仅当 key失效后, 线程1查出旧数据,此时线程2更新数据库,再删除缓存后,线程1将旧数据存入redis,此时出现不一致。(往往缓存未命中,需要查询数据库再放入redis)。
第二点 第二个出现不一致的概率更小。
-

缓存穿透,击穿
Redis 工具类封装
(69条消息) 黑马点评-Redis工具类的封装_redistemplate hutool jsonutil_兜兜转转m的博客-CSDN博客
(69条消息) 仿黑马点评-redis整合【三、缓存工具封装】_笑霸final的博客-CSDN博客
如下:以 其中一种讲解。
/** * 根据指定的key查询缓存,并反序列化为指定类型,需要利用逻辑过期解决缓存击穿问题 * @param keyPrefix key前缀 * @param id 需要查询的数据id * @param type 需要查询的数据类型 * @param dbFallback 查询的具体实现,参数为数据id,返回值为需要查询的数据类型 * @param time * @param unit * @return * @param* @param */ - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
// 逻辑过期 查询 -- 用于缓解缓存击穿 public <R, ID> R queryWithLogicalExpire( String keyPrefix, ID id, Class<R> type, Function<ID, R> dbFallback, Long time, TimeUnit unit) { String key = keyPrefix + id; // 1.从redis查询商铺缓存 String json = stringRedisTemplate.opsForValue().get(key); // 2.判断是否存在 if (StrUtil.isBlank(json)) { // 3.存在,直接返回 return null; } // 4.命中,需要先把json反序列化为对象 RedisData redisData = JSONUtil.toBean(json, RedisData.class); R r = JSONUtil.toBean((JSONObject) redisData.getData(), type); LocalDateTime expireTime = redisData.getExpireTime(); // 5.判断是否过期 if(expireTime.isAfter(LocalDateTime.now())) { // 5.1.未过期,直接返回店铺信息 return r; } // 5.2.已过期,需要缓存重建 // 6.缓存重建 // 6.1.获取互斥锁 String lockKey = LOCK_SHOP_KEY + id; boolean isLock = tryLock(lockKey); // 6.2.判断是否获取锁成功 if (isLock){ // 6.3.成功,开启独立线程,实现缓存重建 ExcutorService_CACHE_RECUTOR.submit(() -> { try { // 查询数据库 R newR = dbFallback.apply(id); // 重建缓存 this.setWithLogicalExpire(key, newR, time, unit); } catch (Exception e) { throw new RuntimeException(e); }finally { // 释放锁 unlock(lockKey); } }); } // 6.4.返回过期的商铺信息 return r; } // Redis 使用 setnx 加锁。 private boolean tryLock(String key) { Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS); return BooleanUtil.isTrue(flag); } private void unlock(String key) { stringRedisTemplate.delete(key); } // Redis设置普通key JSON序列化 public void set(String key, Object value, Long time, TimeUnit unit) { stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), time, unit); } // 逻辑过期设置Key,用于处理缓存击穿 public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit) { // 设置逻辑过期 RedisData redisData = new RedisData(); redisData.setData(value); redisData.setExpireTime(LocalDateTime.now().plusSeconds(unit.toSeconds(time))); // 写入Redis stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
其中的 R 为返回的类型,ID为 参数id 的类型,
Function为 数据库以id为参数,R为返回的数据,调用:
Shop shop = cacheClient .queryWithLogicalExpire(CACHE_SHOP_KEY, id, Shop.class, queryid -> getById(queryid), CACHE_SHOP_TTL, TimeUnit.MINUTES);- 1
- 2
线程池创建使用:
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10); CACHE_REBUILD_EXECUTOR.submit(() -> { try { // 查询数据库 R newR = dbFallback.apply(id); // 重建缓存 this.setWithLogicalExpire(key, newR, time, unit); } catch (Exception e) { throw new RuntimeException(e); }finally { // 释放锁 unlock(lockKey); } });- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Redis秒杀
分布式全局ID
背景:数据库主键自增带来的问题:
- id 规律过于明显,容易被看出一段时间的订单数量
- 若数量很大,分表后不同表订单号id 会重复
全局ID 应满足:
- 唯一:整个系统id唯一
- 递增:整体订单id呈递增趋势,便于数据库索引查询
- 安全:id不能暴露敏感信息
- 高可用:功能应该稳定,不能影响其他业务功能。
- 高性能:被调用很频繁,
为了增加ID的安全性,我们可以不直接使用Redis自增的数值,而是拼接一些其它信息:

ID的组成部分:符号位:1bit,永远为0
时间戳:31bit,以秒为单位,可以使用69年 (通过now - start)时间戳差值
序列号:32bit,每秒内的计数器,支持每秒产生2^32个不同ID。如:每秒可能会生成的下单数量
全局id: 使用Redis
string类型。- 时间戳:(通过now - start)时间戳差值
timestamp - 自增
incr记录序列号。其中KEY为incr:业务功能:日期。count - 使用日期区分,每天创建新的key 自增序列号,如果一直使用一个 key,其值可能 自增超过32bit,(如:订单数超了)
- 使用位运算返回结果。
return timestamp << 32 | count- 时间戳向左位移 32位再加上 序列号count。
- 32: 为序列号留下位置。
- 时间戳向左位移 32位再加上 序列号count。
全局唯一ID生成策略:
- UUID
- 由128位数字组成的标识符,几乎可以保证在全球范围内的唯一性。使用UUID生成器,每次生成的ID都是唯一的,但是它的长度较长,不适合作为数据库索引或URL参数。
- Redis自增 黑马。
- 利用
incr命令实现单 key 的自增
- 利用
- snowflake算法 雪花算法:性能更高,引入机器序号,但依赖全局时钟
- 它使用一个64位的整数来表示生成的ID,其中包含了数据中心的ID、机器ID、时间戳和序列号等信息。雪花算法可以保证在同一毫秒内生成的ID全局唯一,且ID趋势递增,便于按时间排序。
- 数据库自增:单一的自增表,所有 id 全从这个表取。但性能没有 Redis 高
实现秒杀下单
下单时需要判断两点: 有效时间、库存
- 秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
- 库存是否充足,不足则无法下单
核心逻辑分析:
-
当用户开始进行下单,我们应当去查询优惠卷信息,查询到优惠卷信息,判断是否满足秒杀条件
-
比如时间是否充足,如果时间充足,则进一步判断库存是否足够,如果两者都满足,则扣减库存,创建订单,然后返回订单id,如果有一个条件不满足则直接结束。

超卖问题
解决方法:加锁。
悲观锁: 使用
synchronized或lock使得多个线程 串行化,同步执行。 性能差乐观锁: CAS、version版本号 用于数据修改
- 版本号:每次操作对 其version +1 ,通过版本号判断数据是否修改。
- CAS:比较替换:使用库存stock 判断 库存前后是否发生改变:
- 先查询库存 stock1;
- 在扣除库存时,再次判断库存 stock2 ; 看两者库存是否相等 (
stock1 == stock2)- 相等:期间未被其他线程扣除库存,执行扣除库存
- 否则,不扣除库存。
- 缺点:100个线程每次同时扣除同一库存,最后只有一个执行成功,其余执行失败。导致库存还有,但卖不完。
- 解决方法:在业务角度,没必要与自己查询,修改前后库存一定相等才能扣除,只有有库存即可扣除。 (
stock>0) - 分段锁: 将库存分为多份,100个库存分为10份,竞争10
- 解决方法:在业务角度,没必要与自己查询,修改前后库存一定相等才能扣除,只有有库存即可扣除。 (
一人一单
逻辑:同一个优惠券,一个用户只能下一单
- 此时需要先查询用户优惠券表中订单个数。若>1 不能再下单 否则 可下单。
// 5.一人一单逻辑 // 5.1.用户id Long userId = UserHolder.getUser().getId(); int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count(); // 5.2.判断是否存在 if (count > 0) { // 用户已经购买过了 return Result.fail("用户已经购买过一次!"); } //6,扣减库存 //7.创建订单- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
**问题:**多个线程同时查询一个用户,都发现没下单,随后都创建订单。故需要加锁限制。
- 此时数据不存在修改的情况,下单是新增操作,故不能使用乐观锁。
使用悲观锁:
@Transactional-
直接在方法上加锁:
synchronized:锁的粒度太粗,每个线程进来都会阻塞,而一人一单是一个用户多次使用优惠券导致并发问题,故需要对用户ID进行加锁,仅当多个线程同时访问同一用户时需要加锁。不同用户(线程)访问不用加锁 -
包装类
Long的toSting()方法是 new的不同对象。故使用intern()返回字符串常量池。保证userId.toString()锁的是同一用户。-
synchronized(userId.toString().intern()){ // 查询订单 }- 1
- 2
- 3
-
intern 方法的作用是,判断下字符串 引用指向的值在字符串常量里面是否存在,如果没有就在字符串常量池里面新建一个 aaabbb 对象,返回其引用,如果有则直接返回引用。
-
public static String toString(int i) { if (i == Integer.MIN_VALUE) return "-2147483648"; int size = (i < 0) ? stringSize(-i) + 1 : stringSize(i); char[] buf = new char[size]; getChars(i, size, buf); return new String(buf, true); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
-
-
synchronized与 事务 :目前锁住的是userId锁应该在 事务外面:锁 > 事务 事务提交后才能释放锁-
若 范围 锁 < 事务:当锁先执行完,但事务未提交,出现锁结束后,其他线程并发修改数据。
@Transactional public Result createVoucherOrder(Long voucherId) { Long userId = UserHolder.getUser().getId(); synchronized(userId.toString().intern()){ // 查询订单 } // 其他操作 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
so,
synchonized必须在使用@Transactional注解的方法外层使用 (锁>事务)如下:
-
-
调用事务方法时不能用 this 调用,因为
@Transactional注解实际上是调用 Spring 生成的代理对象的方法,如果调用 this 对象的方法会无法使用事务功能,所以要获取代理对象并调用。 -
并 在启动类标注注解来启用暴露代理类:
@EnableAspectJAutoProxy(exposeProxy = true)- 1

不成功是因为调用该方法的对象不是代理对象没有aop功能,需要使用代理对象调用该方法
Spring事务失效
拓展:Spring的事务失效场景
总结一下Spring中事务失效的八种场景-51CTO.COM
(70条消息) spring 事务失效的 12 种场景_duplicatekeyexception 会回滚吗_hanjq_code的博客-CSDN博客
在一个事务中开启另一个事务:
全局事务管理器
(70条消息) springboot项目事务配置 @Transactional注解及AOP实现全局事务管理_
(70条消息) SpringBoot AOP配置全局事务_springaop配置全局事务_X爪哇程序猿的博客-CSDN博客
/** * 全局事务管理器 * * @author yanglei * @date 2020/8/3 */ @Aspect @Configuration public class TransactionalAopConfig { /** * 配置方法过期时间,默认-1,永不超时 */ private final static int METHOD_TIME_OUT = 5000; /** * 配置切入点表达式 */ private static final String POINTCUT_EXPRESSION = "execution(* com.yang.demo.service..*.*(..))"; /** * 事务管理器 */ @Resource private PlatformTransactionManager transactionManager; @Bean public TransactionInterceptor txAdvice() { /*事务管理规则,声明具备事务管理的方法名**/ NameMatchTransactionAttributeSource source = new NameMatchTransactionAttributeSource(); /*只读事务,不做更新操作*/ RuleBasedTransactionAttribute readOnly = new RuleBasedTransactionAttribute(); readOnly.setReadOnly(true); readOnly.setPropagationBehavior(TransactionDefinition.PROPAGATION_NOT_SUPPORTED); /*当前存在事务就使用当前事务,当前不存在事务就创建一个新的事务*/ RuleBasedTransactionAttribute required = new RuleBasedTransactionAttribute(); /*抛出异常后执行切点回滚,这边你可以更换异常的类型*/ required.setRollbackRules(Collections.singletonList(new RollbackRuleAttribute(Exception.class))); /*PROPAGATION_REQUIRED:事务隔离性为1,若当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。这是默认值*/ required.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED); /*设置事务失效时间,如果超过5秒,则回滚事务*/ required.setTimeout(METHOD_TIME_OUT); Map<String, TransactionAttribute> attributesMap = new HashMap<>(30); //设置增删改上传等使用事务 attributesMap.put("save*", required); attributesMap.put("remove*", required); attributesMap.put("update*", required); attributesMap.put("batch*", required); attributesMap.put("clear*", required); attributesMap.put("add*", required); attributesMap.put("append*", required); attributesMap.put("modify*", required); attributesMap.put("edit*", required); attributesMap.put("insert*", required); attributesMap.put("delete*", required); attributesMap.put("do*", required); attributesMap.put("create*", required); attributesMap.put("import*", required); //查询开启只读 attributesMap.put("select*", readOnly); attributesMap.put("get*", readOnly); attributesMap.put("valid*", readOnly); attributesMap.put("list*", readOnly); attributesMap.put("count*", readOnly); attributesMap.put("find*", readOnly); attributesMap.put("load*", readOnly); attributesMap.put("search*", readOnly); source.setNameMap(attributesMap); return new TransactionInterceptor(transactionManager, source); } /** * 设置切面=切点pointcut+通知TxAdvice */ @Bean public Advisor txAdviceAdvisor() { /* 声明切点的面:切面就是通知和切入点的结合。通知和切入点共同定义了关于切面的全部内容——它的功能、在何时和何地完成其功能*/ AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut(); /*声明和设置需要拦截的方法,用切点语言描写*/ pointcut.setExpression(POINTCUT_EXPRESSION); /*设置切面=切点pointcut+通知TxAdvice*/ return new DefaultPointcutAdvisor(pointcut, txAdvice()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
分布式锁
redis 分布式锁的 5个坑,真是又大又深 - YoungDeng - 博客园
在不同的服务、线程共用一把锁,使得不同JVM下 串行执行。
满足条件:
- 可见性:不同JVM下进程 可以看到锁的状态。
- 互斥:程序串行
- 高可用:不能宕机
- 高性能:读写快,影响业务时间 小
- 安全:不会死锁。
实现分布式锁的方法有多种,下面列举几种常用的方式:
- 基于数据库:可以使用数据库的事务和唯一性约束来实现分布式锁。通过在数据库中创建一个锁表,使用事务来保证对锁表的操作的原子性,通过唯一性约束来确保同一时间只有一个节点能够获取到锁。
- 基于缓存:可以使用分布式缓存中的原子性操作来实现分布式锁。比如使用 Redis 的
SETNX命令来设置一个带有过期时间的缓存键,只有一个节点能够成功设置该键,成功设置的节点即获得了锁。 - 基于 ZooKeeper:ZooKeeper 是一个分布式协调服务,可以利用其临时顺序节点和 Watch 机制来实现分布式锁。每个节点在 ZooKeeper 上创建一个临时顺序节点,只有序号最小的节点获得锁,其他节点监听前一个节点的删除事件,一旦前一个节点删除,就轮到下一个节点获得锁。
无论使用哪种方式实现分布式锁,都需要注意锁的释放,避免死锁和长时间占用锁的情况发生。同时还需要考虑锁的粒度和性能等因素。

其中,MySQL 的实现成本相对最低、Redis 性能最高、Zookeeper 可以实现但不推荐使用(Zk 重点在于保证强一致性而不是性能和高可用性,CP 模型)
数据库实现
-
具体实现:在数据库中实现分布式锁可以使用数据库的事务和唯一性约束来确保同一时间只有一个节点能够获取到锁。以下是一个基于数据库的分布式锁示例:
- 创建一个锁表,包含一个唯一的锁名称字段,用于存储锁的状态。
CREATE TABLE distributed_lock ( lock_name VARCHAR(255) PRIMARY KEY );- 1
- 2
- 3
- 获取锁的操作,使用数据库的事务来保证对锁表的操作的原子性。
@Transactional public boolean acquireLock(String lockName) { try { // 尝试向锁表中插入一条锁记录 entityManager.createNativeQuery("INSERT INTO distributed_lock (lock_name) VALUES (:lockName)") .setParameter("lockName", lockName) .executeUpdate(); return true; // 获取锁成功 } catch (Exception e) { return false; // 获取锁失败 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 释放锁的操作,通过删除锁表中的对应记录来释放锁。
@Transactional public void releaseLock(String lockName) { entityManager.createNativeQuery("DELETE FROM distributed_lock WHERE lock_name = :lockName") .setParameter("lockName", lockName) .executeUpdate(); }- 1
- 2
- 3
- 4
- 5
- 6
请注意,以上示例仅展示了基本的分布式锁实现,并没有考虑到锁的超时和重入等复杂情况。在实际应用中,您可能还需要考虑这些因素,并根据实际需求进行相应的扩展和优化。
-
乐观锁控制
缓存实现
基于命令:
setnx// 加锁 SETNX redislock 1 //业务逻辑 ... // 释放锁 del redislock- 1
- 2
- 3
- 4
- 5
- 6
释放锁逻辑应在
finally中执行,确保锁一定释放锁应自动释放:
- 执行业务时超时,
- 获取锁超时,
两个问题:
- 为防止 redis宕机导致锁无法释放,应该为key设置过期时间 :
SETNX key ex nx(原子性) - 误删掉别人的锁:
- 原子性问题
- 加锁过期时间如何预估;
误删别人的锁:
-
场景1: 线程1 得到锁,处理业务时阻塞,锁超时后,redis 删除key(自动释放),此时 线程2得到锁并执行业务,此时线程1苏醒,开始执行释放锁操作,此时就会将线程2的锁删掉。
-
解决方法:获取锁后,缓存value 加入
UUID+线程ID删除锁之前判断锁是否是自己的; -
public void unlock() { // 获取线程标示 String threadId = ID_PREFIX + Thread.currentThread().getId(); // 获取锁中的标示 String id = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name); // 判断标示是否一致 if(threadId.equals(id)) { // 释放锁 stringRedisTemplate.delete(KEY_PREFIX + name); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
key为lock+业务+userId(eg:一人一单:就加上userId 确保一个用户只能用一次优惠券)value应该加上UUID+ThreadId标识。
-
-
原子性问题
-
解锁时,get 锁与delete锁 多条命令,不能保证原子性。
-
场景: 线程1 获取锁,处理业务,判断是自己的锁,在删除锁之前,JVM阻塞线程或 此时key过期导致 超时,锁被自动释放。 此时线程2 拿到锁,执行业务时,线程1苏醒,执行删除锁。导致线程2锁被删除。
- 判断条件没有起到作用。原因:get获取锁和del删除锁不是原子性操作。
-
解决方法:Redis事务行不行? Redis事务无法回滚,其实和lua脚本效果一样。
Lua脚本:-
将多个命令写入一个脚本。
-
释放锁的逻辑:
1、获取锁中的线程标示 2、判断是否与指定的标示(当前线程标示)一致 3、如果一致则释放锁(删除) 4、如果不一致则什么都不做- 1
- 2
- 3
- 4
如果用Lua脚本来表示则是这样的:
最终我们操作redis的拿锁比锁删锁的lua脚本就会变成这样
-- 这里的 KEYS[1] 就是锁的key,这里的ARGV[1] 就是当前线程标示 -- 获取锁中的标示,判断是否与当前线程标示一致 if (redis.call('GET', KEYS[1]) == ARGV[1]) then -- 一致,则删除锁 return redis.call('DEL', KEYS[1]) end -- 不一致,则直接返回 return 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
-
Lua语法:redis.call('命令名称', 'key', '其它参数', ...) # 先执行 set name jack redis.call('set', 'name', 'Rose') # 再执行 get name local name = redis.call('get', 'name') # 返回 return name # Redis 调用 脚本: EVAL "redis.call('SET', KEYS[1], ARGV[1]);" 1 name Hydra- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
EVAL script numkeys key [key ...] arg [arg ...]- 1
简单解释一下其中的参数:
script是一段lua脚本程序numkeys指定后续参数有几个key,如没有key则为0key [key …]表示脚本中用到的redis中的键,在lua脚本中通过KEYS[i]的形式获取arg [arg …]表示附加参数,在lua脚本中通过ARGV[i]获取

其他问题:
除了误删之外,现在的分布式锁实现还存在以下几个问题:
- 不可重入:同一个线程无法获取同一把锁(当递归调用或调用的子函数抢同一把锁时就会出现死锁)
- 自己调自己的锁会死锁。
- 不可重试:没抢到锁就失败了,无等待机制。
- 超时释放:业务未执行完,锁就超时释放了
- 主从一致性:主节点设置锁成功,还未及时同步到从节点,这时主节点宕机,从节点被选为主节点。但此时从节点还没有锁,仍可以抢锁成功。
Redisson
入门配置:详见 D:\baiduwangpan\下载\Redis-笔记资料\02-实战篇\讲义\Redis实战篇.md
可重入锁
原理与 ReentrantLock ReentrantLock、synchronized 类似。
- ReentrantLock: 使用计数器 volatile修饰的
state = 0记录重入锁的状态。- 没人持有此锁,state=0,
- 当每次重复进入同一个锁时,state++,每次解锁,state–。以避免死锁,。
Redisson:使用Hash结构存储 计数。

- 逻辑:
写操作需要使用lua脚本保证原子性。
获取锁:
local key = KEYS[1]; -- 锁的key local threadId = ARGV[1]; -- 线程唯一标识 local releaseTime = ARGV[2]; --锁自动释放时间 -- lockname不存在 if(redis.call('exists', key) == 0) then redis.call('hset', key, threadId, '1'); -- 获取锁,新建key redis.call('expire', key, releaseTime); -- 设置有效期 return nil; -- return 1; end; -- 当前线程已id存在,判断是否的自己的锁 if(redis.call('hexists', key, threadId) == 1) then -- 是自己的锁,重入+1,重置有效期 redis.call('hincrby', key, threadId, '1'); redis.call('expire', key, releaseTime); return nil; --return 1; end; -- 锁存在,但不是自己的,获取锁失败。 return 0;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
释放锁:
local key = KEYS[1]; -- 锁的key local threadId = ARGV[1]; -- 锁标识 local releaseTime = ARGV[2]; -- 锁的过期时间 -- lockname、threadId不存在 if (redis.call('hexists', key, threadId) == 0) then return nil; -- 不是自己的锁,直接返回。 end; -- 计数器-1 local count = redis.call('hincrby', key, threadId, -1); if(count > 0) then -- >0 重置有效期 redis.call('pexpire',key,releaseTime); return nil; -- 删除lock else redis.call('del', key); redis.call('publish', KEYS[2], ARGV[1]); return nil; end; -- redisson -- 不存在key if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then return nil; end; -- 计数器 -1 local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); if (counter > 0) then -- 过期时间重设 redis.call('pexpire', KEYS[1], ARGV[2]); return 0; else -- 删除并发布解锁消息 redis.call('del', KEYS[1]); redis.call('publish', KEYS[2], ARGV[1]); return 1; end; return nil;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40

重试获取锁
waitTime: // 其他线程等待锁释放的时间 (其他线程等待时间) 锁等待时间 leaseTime // 持有锁的时间 (锁的有效时间) 超时时间- 1
- 2
一般是 当前A线程已经拿到锁,其余线程开始重新获取锁。
- 在Redisson 获取锁后 lua脚本
- 返回
null表示 获取锁成功, - 返回
ttl表示 持有锁的剩余时间。
- 返回
已获取锁的A线程在释放锁时,会向争取锁的B线程 发送解锁 消息
LockPubSub.UNLOCK_MESSAGE。所以,B线程需要订阅消息:time -= System.currentTimeMillis() - current; // 订阅消息 RFuture<RedissonLockEntry> subscribeFuture = subscribe(threadId); if (!subscribeFuture.await(time, TimeUnit.MILLISECONDS)) { // time 时间内仍未收到 A解锁的消息:则 // 取消订阅,重试锁失败。 if (!subscribeFuture.cancel(false)) { subscribeFuture.onComplete((res, e) -> { if (e == null) { unsubscribe(subscribeFuture, threadId); } }); } acquireFailed(waitTime, unit, threadId); return false; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 如果订阅结束,还可以等待,则开始获取锁。(开始获取锁)
while (true) {}循环。直到 锁过期 或 超过等待时间。
总结:
基于 Redis Pub / Sub 发布订阅机制。如果获取锁失败,则开始订阅释放锁的消息;当锁被释放时,会触发推送(告诉其他线程我释放锁啦),然后其他线程再重试获取;如此往复,直到超时。
锁超时续期
背景:业务还没有执行完,但锁的时间已经到了,或超时,导致锁释放。
Redisson采用 看门狗机制,续约 key的有效期。直到锁超时或业务结束。
当
leaseTime超时时间 = -1,默认设置为30s
tryLockInnerAsync异步调用lua脚本 获取锁。生成异步结果ttlRemainingFuture。当异步执行lua 后开始执行onComplete回调函数。
ttlRemaining:接收异步结果,e为异常。锁获取成功 后 开始执行
scheduleExpirationRenewal()定期更新锁过期时间// 异步执行 获取锁的lua脚本 返回值为 null | 锁的 ttl RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(waitTime, commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(), TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG); ttlRemainingFuture.onComplete((ttlRemaining, e) -> { if (e != null) { return; } // lock acquired 锁获取成功: if (ttlRemaining == null) { scheduleExpirationRenewal(threadId); } });- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
使用全局
ConcurrentHashMap为每个锁记录 其对应的线程id 列表。- 使用
putIfAbsent方法 持续为当前锁 添加 线程id列表 - 并为每个锁创建唯一任务
renewExpiration
private void scheduleExpirationRenewal(long threadId) { ExpirationEntry entry = new ExpirationEntry(); ExpirationEntry oldEntry = EXPIRATION_RENEWAL_MAP.putIfAbsent(getEntryName(), entry); if (oldEntry != null) { oldEntry.addThreadId(threadId); } else { entry.addThreadId(threadId); renewExpiration(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
看门狗定期更新锁的过期时间 :
添加一个netty的Timeout回调任务,每(
internalLockLeaseTime / 3)毫秒执行一次,执行方法renewExpirationAsyncrenewExpirationAsync重置锁超时时间,又注册一个监听器,监听回调又执行了renewExpiration- 什么时候结束?宕机或业务结束。
- 当某个锁释放时,从全局
ConcurrentHashMap中取出定时任务并取消掉,- 当该锁不存在线程id后,把锁的信息从 Map 中删掉。
- 当某个锁释放时,从全局
private void renewExpiration() { Timeout task = commandExecutor.getConnectionManager().newTimeout( new TimerTask() { @Override public void run(Timeout timeout) throws Exception { ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName()); if (ent == null) { return; } Long threadId = ent.getFirstThreadId(); if (threadId == null) { return; } RFuture<Boolean> future = renewExpirationAsync(threadId); future.onComplete((res, e) -> { if (e != null) { log.error("Can't update lock " + getName() + " expiration", e); return; } if (res) { // reschedule itself renewExpiration(); } }); } }, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS); ee.setTimeout(task); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
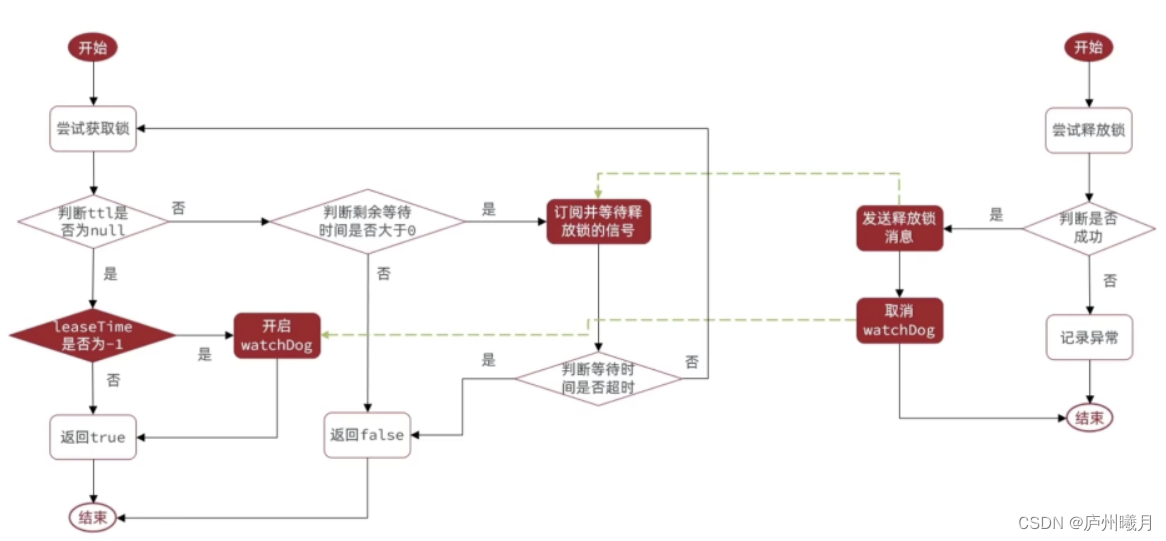
看门狗机制:
如果不手动设置锁释放时间(leaseTime),默认设置 30 秒过期,并且给当前锁注册一个定时任务,该定时任务每隔 1 / 3 的锁释放时间(一般是 10 秒)会重置锁的过期时间 。业务结束后释放。
主从一致性
背景: Redis主从
- 此时我们去写命令,写在主机上, 主机会将数据同步给从机,但是假设在主机还没有来得及把数据写入到从机去的时候,此时主机宕机,哨兵会发现主机宕机,并且选举一个slave变成master,而此时新的master中实际上并没有锁信息,此时锁信息就已经丢掉了。
使用 Redisson 的
MultiLock(联锁)来解决,核心思想是开启多个独立的 Redis 主节点,设置锁时必须在所有主节点都写入成功,才算设置成功。这样做之后,哪怕有部分节点挂掉,其他线程也无法 setnx 全部成功,就不会出现重复执行业务的情况。
实现
MultiLock的几个关键:-
遍历所有节点,依次设置锁,并使用列表来记录所有主节点的锁是否设置成功。
-
只要有一个节点设置不成功,就要释放所有的锁,从头来过。
-
因为不同节点设置锁成功的时间不同,所以在所有锁设置成功后,要统一设置过期时间(但如果 leaseTime = -1 就不用了,因为开启了看门狗机制会自动续期)
-
锁释放时间(leaseTime)必须要大于抢锁最大等待时间(waitTime),否则可能出现第一个节点抢到锁,最后一个节点还没抢到锁,之前的锁就已经超时释放了。所以如果指定了 waitTime 和 leaseTime,默认
leaseTime = waitTime * 2。
缺点:MultiLock 最安全,但同样会带来很大的运维成本。
秒杀业务优化
下单流程:
1. 查询优惠券 2. 优惠券库存是否足够 3.查询订单 4.验证一人一单 5.扣减库存 6.创建订单- 1
- 2
- 3
- 4
- 5
- 6
其中,查询库存、校验一人一单 为查询, 扣减库存、创建订单为耗时的写操作。为提高性能,可改变单线程串行 分成多个线程并行执行。
- 将 2、4 放入Redis 查询,当满足购买资格,直接为用户返回下单成功。通过消息队列
queue异步执行 5、6.
使用Redis 判断 库存和一人一单:
-
Redis存储库存数量
String; 使用set存放 已使用优惠券的用户id。 -
每查询Redis库存后,
value减一 ; 如果用户未使用优惠券,将其加入set
1.
-
为保证原子性,使用
lua脚本
执行完后,若 lua return 0 表示可以下单,将
优惠券id、用户id,生成订单id存入到queue中去,前端给返回,然后再来个线程异步的下单,前端可以通过返回的订单id来判断是否下单成功。
阻塞队列可以用 JDK 原生的 BlockingQueue 实现,记得指定队列容量。
private BlockingQueue<VoucherOrder> orderTasks =new ArrayBlockingQueue<>(1024 * 1024);- 1
Redis消息队列
List
双向链表,可使用
Lpush和Rpop左进右出模拟队列。优点:
- 可持久化
- 不受JVM内存限制
- 消息保证有序性。
缺点:
-
消息只能被一个人消费;无法实现广播消息。
-
如果消息丢失无确认机制:消息出队后即删除。消息易丢失。
-
当队列为空返回
null,不能像JVM 阻塞队列,- 解决方法:使用
LPUSH、BRPOP命令。-
BRPOP用于阻塞式地从一个或多个列表中弹出最后一个元素。BRPOP key [key ...] timeout- 1
key [key ...]:一个或多个列表的键。timeout:阻塞超时时间,单位为秒。如果列表中没有元素,则会阻塞等待,直到超时时间到达或有元素可弹出。
-
- 解决方法:使用
Pub/Sub
Pub/Sub机制: Redis发布订阅模型。消费者可以订阅多个
channel以接收生产者的消息。 (可以广播)- SUBSCRIBE channel [channel] :订阅一个或多个频道
- PUBLISH channel msg :向一个频道发送消息
- PSUBSCRIBE pattern[pattern] :订阅与pattern格式匹配的所有频道
*: it* 匹配所有以 it 开头的频道
优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息无顺序性
- 消息堆积有上限,超出时数据丢失
stream
Redis Stream 主要用于消息队列,
Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
XADD: 为 stream添加 队列。
-
XADD key ID field string [field string ...]key队列名;ID消息唯一标识。*由Redis生成时间戳-递增数字- 多个
key-value结构
-
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] -
COUNT每次读取的最大树 -
BLOCK当队列为空时,阻塞等待的时间。0一直阻塞 -
key队列名; -
ID消息id
-0从第一个消息开始
-$最新的消息开始
缺点:
- 使用
$获取最新消息。在处理消息时,期间队列又收到多个消息,再次XREAD获取只能得到最新的一条,其余无法获取,出现漏读。
优点:
- 消息可重复消费
stream 消费者组
(71条消息) Redis Stream最全用法详解一_光阴不负卿的博客-CSDN博客
-
使用消费组:同一组内的消费者之间竞争消费消息。 不同组间可广播消费。
-
记录消费的进度,若出现异常,宕机,则会从上次消费的下标开始消费
-
消息确认机制: 消费者收到消息后,处于
pending状态,已接收未消费的消息 会存入pending-list中,待消息消费后,返回XACK,确认消息被消费。 则在pending-list删除消息。
消费组:CREATE 创建消费者组 、 SETID 设置消费者组 标识位置 、 DESTORY 删除消费者组、
DELCONSUMER 删除消费者组中的一个消费者
XGROUP [CREATE key groupname id-or-$] [SETID key id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]创建:
XGROUP CREATE key groupname id-or-$ [MKSTREAM]key队列名、groupname:消费组名、MKSTREAM当不存在队列时,自动创建id-or-$- $ : 表示从最后开始消费,只接受新消息,当前 Stream 消息会全部忽略。
id:0代表从0开始消费;
从消费者组读取消息:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]group消费组名称;consumer消费者count消费消息个数key队列名称、ID起始id- id:
>获取下一个未消费的消息 - id:
0获取pending-list中 已消费但未接收的第1个消息。 拿到未确认的消息记得确认XACK
- id:
获取
pending-list的消息:XPENDING key group [start end count] [consumer]-
xpending 命令 – Redis中国用户组(CRUG)
删除指定的消费者组
XGROUP DESTORY key groupName- 1
给指定的消费者组添加消费者
XGROUP CREATECONSUMER key groupname consumername- 1
删除消费者组中的指定消费者
XGROUP DELCONSUMER key groupname consumername- 1
大致思路:
监听队列是否存在未消费的消息:
-
若不存在,重新循环监听队列;
-
若存在,处理消息并ACK;
- 如果出现意外,没ACK 从
pending-list中获取消息- 重新处理
- 若
pending-list不存在 未确认的消息后 返回外层继续监听队列;- 存在未确认消息,重新处理。
- 若处理未确认的消息出现异常: 写日志,重新循环处理消息。
- 如果出现意外,没ACK 从
while(true){ // 监听队列,阻塞2s 获取消息 Object msg = redis.call("XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS queue1"); if(msg == null){ // 没有消息,持续监听 contiune; } try{ handleMessage(msg); // 处理消息msg并ACK确认 }catch(Exception e){ while(true){ // 异常则 msg未确认,重新在pending-list消费 Object msg = redis.call("XREADGROUP GROUP g1 c1 COUNT 1 STREAMS queue1 0"); if(msg == null){ // 所有消息都已确认,返回上层监听队列 break; } try{ // 处理pending-list中的消息,ACK handleMessage(msg); }catch(Exception e){ // 再次异常,记录日志,重新处理 // 若循环多次,说明消息无法被消费。人工介入。 continue; } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
特点:
- 不同消费者组的消息可重复消费,广播;
- 同一组的消息,由多个消费者竞争消费
- 可阻塞获取消息
- 记录消费的进度,确保消息都会消费。不存在漏读。
- 有消息确认机制,确保消息一定被消费。

点赞
一般业务 判断是否点赞和 操作数据库 都在数据库层面,对数据库压力大; 将判断是否点赞 放在Redis,数据库只更新点赞数即可。
- 使用Redis
set结构key为 文章id,value为已点赞用户id。 - 用户点赞,判断 set 是否存在该用户
- 存在,为取消点赞,set移除用户id,点赞数-1
- 不存在,set 添加用户id,点赞数+1
在高并发情况下, 容易出现多个用户同时对同一篇文章进行点赞的情况 出现点赞数据不一致的情况,
- 可以考虑 分布式锁、lua脚本实现。操作数据库可另开线程异步执行,参考 秒杀业务优化
点赞排行榜
使用
SortedSet结构ZADD key score1 member1 score2 member2 ...向指定有序集合添加一个或多个元素score: 元素的权重参数,可对元素排序memberset 中的元素
- 为点赞的用户id添加 权重 时间戳,根据时间戳排序
stringRedisTemplate.opsForZSet().add(key, userId.toString(), System.currentTimeMillis());- 1
- 使用
ZRANGE key start end获取 topN 前几名的id。
共同关注
两个用户关注列表中的交集
set:
intersect取交集String key = "follows:" + userId; // 2.求交集 String key2 = "follows:" + id; Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);- 1
- 2
- 3
- 4
Feed 流关注推送
feed:系统分析用户到底想要什么,然后直接把内容推送给用户,从而使用户能够更加的节约时间,不用主动去寻找。
场景:UP 主发布新内容时,系统会给所有关注的粉丝发送一个消息
两种模式:
Timeline将用户的好友、关注 的内容按照时间排序。eg:朋友圈- 优点: 信息全,
- 缺点: 用户不一定都感兴趣
智能排序屏蔽违规、用户不感兴趣的内容。推送用户感兴趣的内容- 优点:根据推荐算法为用户推送感兴趣的内容
- 缺点:若算法不精准,则起到反作用。
Timeline 实现方式
拉模式:读扩散:
用户关注的up 将动态发在各自的 信箱中;待用户上线后,将所有的up动态读取,进行整理排序。(用户主动拉,可能比较耗时)
缺点:比较延迟。
- 若用户关注的up过多,导致拉取up们的动态很大,对服务器压力高。

推模式 写扩散
up没有自己的信箱;up发布的动态会直接写入到粉丝的信箱中。
- 优点:用户不用再临时拉取。速度快
- 缺点:内存压力大,若是大V,则需要发送给大量的粉丝。 写入时可能会很耗时、占用资源)

推拉结合
读写混合。- 1
推模式应用于:粉丝少的 UP、推送给活跃用户
拉模式应用于:粉丝多的 UP && 推送给非活跃用户对于大V:动态写入自己信箱。
- 头号粉丝:人数少,采取 推模式。写入 头号粉丝的信箱。
- 普通粉丝:人数多。采取拉模式。 上线时,将信息读取发给普通粉丝。
普通up:
- 粉丝少,采取推模式。


分页问题
但是要注意,由于消息是不断增加的,如果需要分页查询,每条消息的下标都会动态变化,导致数据重复查询,如下图:
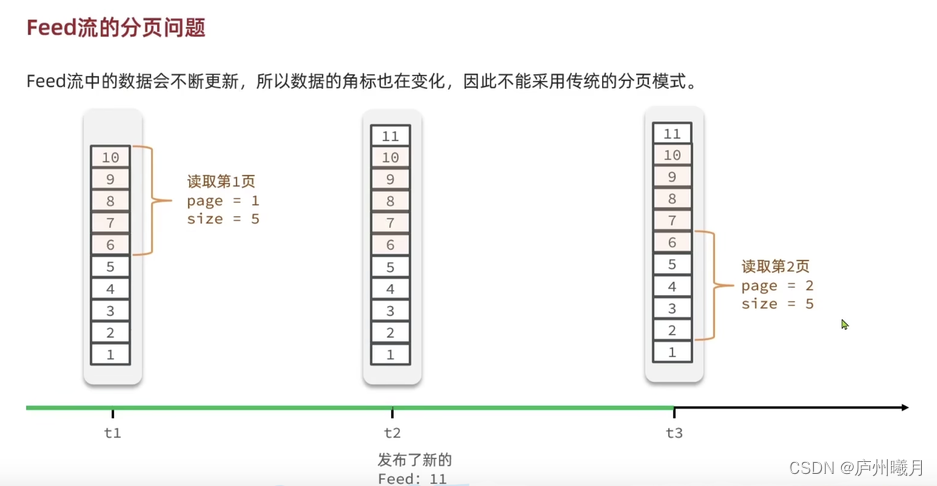
可以使用滚动分页,记录每次当前页查询到的最后一条数据的时间戳(类似游标)。查询下一页时,从当前时间戳的下一条开始查询即可,如图:

可以使用
SortedSet的ZRevRangeByScore命令实现,每次查询指定时间戳范围(0,当前最大时间戳)的指定条数的数据。示例命令:ZRevRangeByScore key 0 maxTimeStamp offset limitZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]- 1
max上一次查询的最小时间戳 。第一次取当前时间戳,min0offset0 从0开始。 在上次查询结果中 时间戳最小值相同数量。count查询个数
- 出现相同时间戳
第一次查询时 offset 为 0(从第一条开始查),之后每次查询,offset 为上一页中时间戳最小值的数量,保证不查出重复数据。
比如 score 列表为:5, 4, 4, 3, 2, 1。每页 3 条。
第一次查询
ZRevRangeByScore key 9999999 0 0 3查出 5、4、4,最小值 4 重复 2 次,下一次的最大值为 4 即 max=4,offset 为 2。 所以第二次查询为
ZRevRangeByScore key 4 0 2 3查出 3、2、1GEO 地理坐标
用于存储 多个地理坐标,计算坐标间的距离。 坐标 半径范围内与其他坐标间的距离 (附件的人)
底层是
SortedSet常见的命令:
- GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
- GEODIST:计算指定的两个点之间的距离并返回
- GEOHASH:将指定member的坐标转为hash字符串形式并返回
- GEOPOS:返回指定member的坐标
- GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.以后已废弃
- GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
- GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能
附近的人
查询你附近所有的小姐姐,以及每个小姐姐和你的距离,并且按照距离由近到远排序
实现:- 使用 GEOADD 添加所有小姐姐的 id 和位置到一个 key 中
- 使用 GEOSEARCH 查询以你当前坐标为中心、指定距离内的所有小姐姐,默认返回的就是由近及远的 SortedSet(value 为 id、score 为和你的距离)
业务场景:
附件的商户:
-
要根据分类来计算同组内的距离及排名,可以每个类别一个独立的 key,如图:
-
根据key区分不同的商户。

stringRedisTemplate频繁插入影响性能。 使用locations批量添加。List<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>(value.size()); // 3.3.写入redis GEOADD key 经度 纬度 member for (Shop shop : value) { // stringRedisTemplate.opsForGeo().add(key, new Point(shop.getX(), shop.getY()), shop.getId().toString()); // 批量插入 locations.add(new RedisGeoCommands.GeoLocation<>( shop.getId().toString(), new Point(shop.getX(), shop.getY()) )); } stringRedisTemplate.opsForGeo().add(key, locations);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
BitMap
string类型实现。
一行bit记录一个月的签到状态。一个bit记录每月的一天。
- SETBIT:向指定位置(offset)存入一个0或1
- GETBIT :获取指定位置(offset)的bit值
- BITCOUNT :统计BitMap中值为1的bit位的数量
- BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
- BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
- BITOP :将多个BitMap的结果做位运算(与 、或、异或)
- BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
BITFIELD命令的语法如下:BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL]- 1
这个命令支持多个子命令和参数,可以根据需要组合使用。下面是每个子命令和参数的解释:
-
GET type offset: 获取字符串值中指定位域的值。type表示位域类型,可以是无符号整数(u)、有符号整数(i)或浮点数(f),. offset表示位域的偏移量。type“u”:无符号整数类型。 “i”:有符号整数类型。 “f”:浮点数类型。
-
SET type offset value: 设置字符串值中指定位域的值。type和offset的含义与上述相同,value表示要设置的值。 -
INCRBY type offset increment: 对字符串值中指定位域的值进行增加或减少。type和offset的含义与上述相同,increment表示要增加或减少的值。 -
OVERFLOW WRAP|SAT|FAIL: 指定在执行SET或INCRBY操作时发生溢出的处理方式。WRAP表示溢出时循环回到最小值,SAT表示溢出时将最小值或最大值设为边界值,FAIL表示溢出时操作失败。
一个示例,假设有一个名为
user:1:flags的字符串键,它的值是一个无符号整数类型的位域。 以下命令将偏移量为0的位域的值增加10:
BITFIELD user:1:flags INCRBY u8 0 10 --从`user:1:flags`键中获取一个8位无符号整数,它的偏移量为0,并将其增加10。执行这个命令后,你将获得更新后的位域值。 BITFIELD mykey GET u8 0 --mykey的字符串值中从0开始 的8位无符号整数位域的十进制值。- 1
- 2
- 3
- 4
签到:
SETBIT key 第几天-1 1public Result sign() { // 1.获取当前登录用户 Long userId = UserHolder.getUser().getId(); // 2.获取日期 LocalDateTime now = LocalDateTime.now(); // 3.拼接key String keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM")); String key = USER_SIGN_KEY + userId + keySuffix; // 4.获取今天是本月的第几天 int dayOfMonth = now.getDayOfMonth(); // 5.写入Redis SETBIT key offset 1 stringRedisTemplate.opsForValue().setBit(key, dayOfMonth - 1, true); return Result.ok(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
签到统计:
当天 从后向前与运算直到 结果为0,统计连续签到天数 。

-
得到本月的今天为止所有bit数据:
BITFIELD key GET u[dayOfMonth] 0 -- 从0开始取dayOfMonth天- 1
-
从后向前 与运算:
十进制结果
num与1 做与运算。随后num 右移1位int count = 0; while (true) { // 6.1.让这个数字与1做与运算,得到数字的最后一个bit位 // 判断这个bit位是否为0 if ((num & 1) == 0) { // 如果为0,说明未签到,结束 break; }else { // 如果不为0,说明已签到,计数器+1 count++; } // 把数字右移一位,抛弃最后一个bit位,继续下一个bit位 num >>>= 1; } return Result.ok(count);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
循环右移一定要用 >>>(无符号右移,高位补 0),否则可能会死循环。
HyperLogLog
概率性数据结构。 以低内存 实现 一个集合中不重复元素个数统计。但不存储集合实际元素。解决大数据集合的基数计数问题。
PFADD key element [element ...]:将一个或多个元素添加到HyperLogLog中。PFCOUNT key [key ...]:返回给定HyperLogLog的基数估计值。- 概率性数据结构,其估计值可能会有一定的误差。
PFMERGE destkey sourcekey [sourcekey ...]:将多个HyperLogLog合并,并将结果存储在目标HyperLogLog中。
优点:占用内存极低,不会超过 16 Kb
缺点:基于概率统计,存在 < 0.81% 的误差
因此,它很适合用于 UV、PV 等数据量大、精度要求不高的统计。UV PV
- UV:全称
Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。 - PV:全称
Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
通常来说PV会比UV大很多,所以衡量同一个网站的访问量,我们需要综合考虑很多因素,所以我们只是单纯的把这两个值作为一个参考值
多级缓存
- 当用户访问时,浏览器优先读取客户端缓存(静态资源);
- 非静态资源 请求Nginx。先读取Nginx本地缓存
- 未命中则访问Redis
- 未命中,则访问Tomcat进程缓存
- 最后仍未命中 则访问数据库
最后搞成集群:

多级缓存的关键有两个:
-
一个是在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询
-
另一个就是在Tomcat中实现JVM进程缓存
其中Nginx编程则会用到
OpenResty框架结合Lua这样的语言。JVM缓存
当Redis 缓存未命中,再查找是否命中JVM进程缓存。
缓存同步策略
三种方式:
-
缓存设置有效期。到期自动删除。再次查询时更新。
- 缺点:时效性弱。缓存与数据库弱一致。 缓存更新之前 可能不一致
- 更新频率低
- 缺点:时效性弱。缓存与数据库弱一致。 缓存更新之前 可能不一致
-
同步双写:修改数据库时,直接更新缓存
- 优点: 时效性强,缓存与数据库强一致。
- 缺点:耦合度高;存在代码侵入
-
异步通知:修改数据库时,发送事件通知,相关服务监听到通知后,修改缓存。
- 优点:低耦合。可通知多个缓存服务。
- 缺点:时效性一般,中间存在数据不一致状态。
- 场景:不要求强一致。基于MQ或者 Canal来实现
-
MQ异步通知:
- 当数据库数据修改后,发送一条数据消息 至MQ
- 缓存服务监听MQ,随后更新缓存。
存在代码侵入

Canal
Canal通知:
- Canal 监听MySQL变化,若MySQL发生变化,则通知缓存服务。
- 缓存服务收到Canal 消息后,更新缓存。
- 无代码侵入
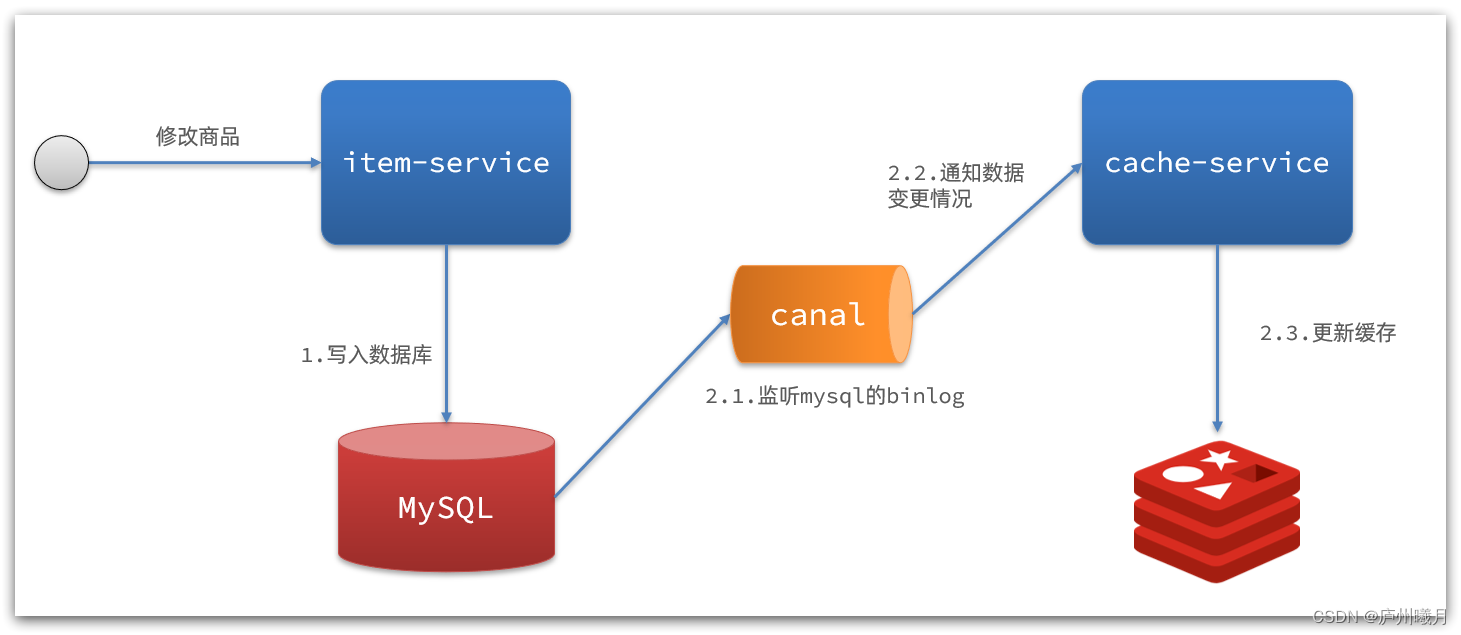
Canal 基于数据库增量日志解析,提供增量数据订阅&消费
配置MySQL主从:
(101条消息) windows mysql配置主从_不吃糯玉米的博客-CSDN博客
server-id=1 #必须唯一 log-bin=mysql-bin #开启2进制文件 随后生成日志文件:mysql-bin00000X # 如果需要指定同步的库添加 非必要 binlog-do-db=community_platform- 1
- 2
- 3
- 4
配置解读:
log-bin=/var/lib/mysql/mysql-bin:设置binary log文件的存放地址和文件名,叫做mysql-binbinlog-do-db=heima:指定对哪个database记录binary log events,这里记录heima这个库

-
相关阅读:
10个前端开发常用的速查网站
容器安全 - 利用容器的特权配置实现对Kubernetes攻击
LeetCode - 解题笔记 - 189 - Rotate Array
C++模板介绍
运输层课后作业
Pico neo3+Unity开发记录
SQLAlchemy使用教程
【将图片链接中的图片合并成PDF】
Spring Security——基于前后端分离项目的使用(安全框架)
Integration by parts
- 原文地址:https://blog.csdn.net/qq_45888242/article/details/133587373
