-
【错误记录】Python 中使用 PySpark 数据计算报错 ( SparkException: Python worker failed to connect back. )
错误原因 : 没有为 PySpark 配置 Python 解释器 , 将下面的代码卸载 Python 数据分析代码的最前面即可 ;
# 为 PySpark 配置 Python 解释器 import os os.environ['PYSPARK_PYTHON'] = "Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe"- 1
- 2
- 3
os.environ['PYSPARK_PYTHON']的值设置为 你自己电脑上的 python.exe 绝对路径即可 , 不要按照我电脑上的 Python 解释器路径设置 ;
一、报错信息
Python 中使用 PySpark 数据计算 ,
# 创建一个包含整数的 RDD rdd = sparkContext.parallelize([1, 2, 3, 4, 5]) # 为每个元素执行的函数 def func(element): return element * 10 # 应用 map 操作,将每个元素乘以 10 rdd2 = rdd.map(func)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
执行时 , 报如下错误 :
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py 23/07/30 21:24:54 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/07/30 21:24:54 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable PySpark 版本号 : 3.4.1 23/07/30 21:25:07 ERROR Executor: Exception in task 9.0 in stage 0.0 (TID 9) org.apache.spark.SparkException: Python worker failed to connect back. at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:192) at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109) at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124) at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:166) at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:364) at org.apache.spark.rdd.RDD.iterator(RDD.scala:328) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:92) at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:161) at org.apache.spark.scheduler.Task.run(Task.scala:139) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:554) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1529) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:557) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.net.SocketTimeoutException: Accept timed out at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method) at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:135) at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409) at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:199) at java.net.ServerSocket.implAccept(ServerSocket.java:545) at java.net.ServerSocket.accept(ServerSocket.java:513) at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:179) ... 15 more 23/07/30 21:25:07 WARN TaskSetManager: Lost task 9.0 in stage 0.0 (TID 9) (windows10.microdone.cn executor driver): org.apache.spark.SparkException: Python worker failed to connect back. at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:192) at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109) at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124) at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:166) at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:364) at org.apache.spark.rdd.RDD.iterator(RDD.scala:328) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:92) at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:161) at org.apache.spark.scheduler.Task.run(Task.scala:139) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:554) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1529) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:557) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.net.SocketTimeoutException: Accept timed out at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method) at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:135) at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409) at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:199) at java.net.ServerSocket.implAccept(ServerSocket.java:545) at java.net.ServerSocket.accept(ServerSocket.java:513) at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:179) ... 15 more 23/07/30 21:25:07 ERROR TaskSetManager: Task 9 in stage 0.0 failed 1 times; aborting job Traceback (most recent call last): File "Y:\002_WorkSpace\PycharmProjects\HelloPython\hello.py", line 33, in <module> print(rdd2.collect()) File "Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\lib\site-packages\pyspark\rdd.py", line 1814, in collect sock_info = self.ctx._jvm.PythonRDD.collectAndServe(self._jrdd.rdd()) File "Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\lib\site-packages\py4j\java_gateway.py", line 1322, in __call__ return_value = get_return_value( File "Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\lib\site-packages\py4j\protocol.py", line 326, in get_return_value raise Py4JJavaError( py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe. : org.apache.spark.SparkException: Job aborted due to stage failure: Task 9 in stage 0.0 failed 1 times, most recent failure: Lost task 9.0 in stage 0.0 (TID 9) (windows10.microdone.cn executor driver): org.apache.spark.SparkException: Python worker failed to connect back. at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:192) at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109) at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124) at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:166) at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:364) at org.apache.spark.rdd.RDD.iterator(RDD.scala:328) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:92) at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:161) at org.apache.spark.scheduler.Task.run(Task.scala:139) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:554) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1529) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:557) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.net.SocketTimeoutException: Accept timed out at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method) at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:135) at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409) at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:199) at java.net.ServerSocket.implAccept(ServerSocket.java:545) at java.net.ServerSocket.accept(ServerSocket.java:513) at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:179) ... 15 more Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2785) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2721) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2720) at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2720) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1206) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1206) at scala.Option.foreach(Option.scala:407) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1206) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2984) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2923) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2912) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:971) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2263) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2284) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2303) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2328) at org.apache.spark.rdd.RDD.$anonfun$collect$1(RDD.scala:1019) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) at org.apache.spark.rdd.RDD.withScope(RDD.scala:405) at org.apache.spark.rdd.RDD.collect(RDD.scala:1018) at org.apache.spark.api.python.PythonRDD$.collectAndServe(PythonRDD.scala:193) at org.apache.spark.api.python.PythonRDD.collectAndServe(PythonRDD.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:374) at py4j.Gateway.invoke(Gateway.java:282) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182) at py4j.ClientServerConnection.run(ClientServerConnection.java:106) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.spark.SparkException: Python worker failed to connect back. at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:192) at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109) at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124) at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:166) at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:364) at org.apache.spark.rdd.RDD.iterator(RDD.scala:328) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:92) at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:161) at org.apache.spark.scheduler.Task.run(Task.scala:139) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:554) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1529) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:557) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ... 1 more Caused by: java.net.SocketTimeoutException: Accept timed out at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method) at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:135) at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409) at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:199) at java.net.ServerSocket.implAccept(ServerSocket.java:545) at java.net.ServerSocket.accept(ServerSocket.java:513) at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:179) ... 15 more [Stage 0:> (0 + 11) / 12] Process finished with exit code 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168


核心报错信息如下 :
org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:192)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124)
二、问题分析
执行的代码如下 :
""" PySpark 数据处理 """ # 导入 PySpark 相关包 from pyspark import SparkConf, SparkContext # 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务 # setMaster("local[*]") 表示在单机模式下 本机运行 # setAppName("hello_spark") 是给 Spark 程序起一个名字 sparkConf = SparkConf() \ .setMaster("local[*]") \ .setAppName("hello_spark") # 创建 PySpark 执行环境 入口对象 sparkContext = SparkContext(conf=sparkConf) # 打印 PySpark 版本号 print("PySpark 版本号 : ", sparkContext.version) # 创建一个包含整数的 RDD rdd = sparkContext.parallelize([1, 2, 3, 4, 5]) # 为每个元素执行的函数 def func(element): return element * 10 # 应用 map 操作,将每个元素乘以 10 rdd2 = rdd.map(func) # 打印新的 RDD 中的内容 print(rdd2.collect()) # 停止 PySpark 程序 sparkContext.stop()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
执行的代码 , 没有任何错误 ;
报错原因是 Python 代码没有准确地找到 Python 解释器 ;
在 PyCharm 中 , 已经配置了 Python 3.10 版本的解释器 , 该解释器可以被 Python 程序识别到 , 但是不能被 PySpark 识别到 ;

因此 , 这里需要手动为 PySpark 设置 Python 解释器 ;
设置 PySpark 的 Python 解释器环境变量 ;
三、解决方案
在 PyCharm 中 , 选择 " 菜单栏 / File / Settings " 选项 ,

在 Settings 窗口中 , 选择 Python 解释器面板 , 查看 配置的 Python 解释器安装在哪个路径中 ;

记录 Python 解释器位置 :
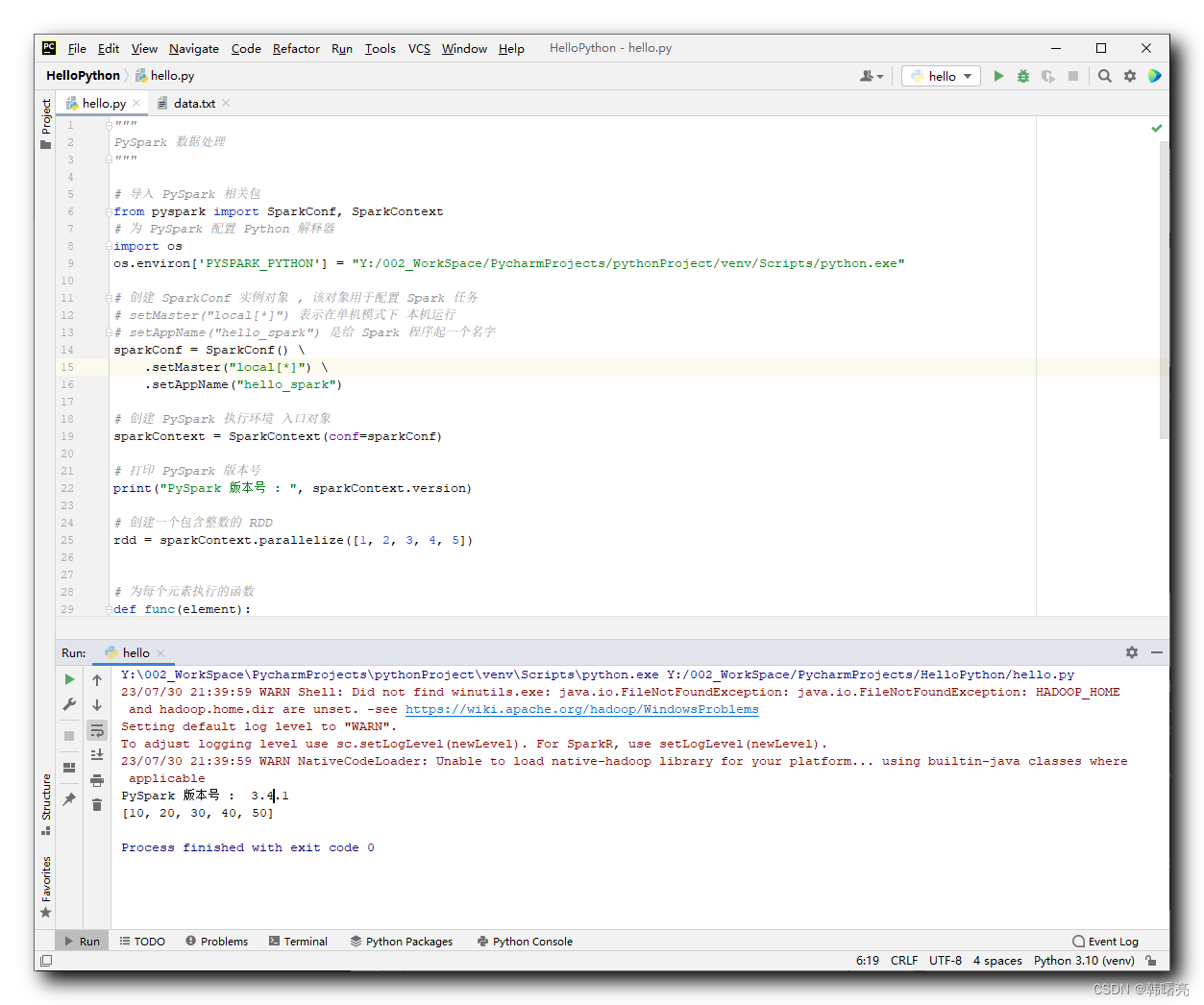
Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe

在 代码 的开始位置 , 添加如下代码 :
import os os.environ['PYSPARK_PYTHON'] = "Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe"- 1
- 2
将
os.environ['PYSPARK_PYTHON'] =后的 Python.exe 路径换成你自己电脑上的路径即可 ;
修改后的完整代码如下 :
""" PySpark 数据处理 """ # 导入 PySpark 相关包 from pyspark import SparkConf, SparkContext # 为 PySpark 配置 Python 解释器 import os os.environ['PYSPARK_PYTHON'] = "Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe" # 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务 # setMaster("local[*]") 表示在单机模式下 本机运行 # setAppName("hello_spark") 是给 Spark 程序起一个名字 sparkConf = SparkConf() \ .setMaster("local[*]") \ .setAppName("hello_spark") # 创建 PySpark 执行环境 入口对象 sparkContext = SparkContext(conf=sparkConf) # 打印 PySpark 版本号 print("PySpark 版本号 : ", sparkContext.version) # 创建一个包含整数的 RDD rdd = sparkContext.parallelize([1, 2, 3, 4, 5]) # 为每个元素执行的函数 def func(element): return element * 10 # 应用 map 操作,将每个元素乘以 10 rdd2 = rdd.map(func) # 打印新的 RDD 中的内容 print(rdd2.collect()) # 停止 PySpark 程序 sparkContext.stop()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
执行结果 :
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py 23/07/30 21:39:59 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 23/07/30 21:39:59 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable PySpark 版本号 : 3.4.1 [10, 20, 30, 40, 50] Process finished with exit code 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
相关阅读:
Rust错误处理和Result枚举类异常错误传递
ESP32-添加多目录的自定义组件
在使用ubuntu18.04的时候使用阿里源或者清华源后安装mysql5.7时出现dpkg提示的错误信息
React(react18)中组件通信03——简单使用 Context 深层传递参数
Jenkins(3)Jenkins自动化发布到 测试服务器 并 自动运行
在自己电脑运行Stable Diffusion和完整项目下载
百分点应急管理大数据平台案例入围《北京产业互联网创新应用场景案例》
英国Top20名校更偏爱IB申请党?
如何从0到1搭建一个个人网站
OpenCV数字图像处理基于C++:图像形态学处理
- 原文地址:https://blog.csdn.net/han1202012/article/details/132011806
