-
SegGPT: Segmenting Everything In Context论文笔记
1. 背景
在Painter中,将各种密集预测任务视为一种着色问题。
- 在训练过程中将同一数据集的两张图片的原图和GT图分别拼接起来,然后,随机将GT图的某些块mask掉,通过预测这些被mask掉的区域的颜色,并和GT进行loss监督。
- 那么,在推理阶段,给定一张图片和它对应的GT图作为prompt,再给定一张要与prompt执行相同任务的图片,那么这张图片的GT相当于被全部mask掉,模型输出就会将mask掉的区域也就是整张图的颜色预测出来。

2. Motivation
- 在Painter中,以语义分割任务为例,类别的颜色是事先给定的,使得模型学习到的是一种任务特定的颜色预测任务;
- 在SegGPT中,目标是根据上下文完成不同的任务,而不是依赖于特定的颜色。
3. Method
3.1 In-Context Coloring
在Painter中,每个类别的颜色是事先定义的,这导致模型学习到了任务特定的信息,而不是依据给定的prompt,按照其中的上下文含义进行分割。
因此:
- SegGPT将之前的预定义的颜色着色改成了随机着色;
- 此外,为了应对上下文的问题,对于当前训练图片,从数据集中随机挑选出与当前图片上下文相同的图片,如类别一致或者属于同一instance,以这样的方式来构造pairs;
- 注意,同一pairs要使用相同的颜色映射,这样模型才能知道着色相同的区域上下文是一致的;
3.2 Context Ensemble
在推理阶段,可以给定一张图片和对应的标签作为prompt,将要推理的图片和prompt进行拼接。
为了使得结果更加准确,可以使用多个prompt,这些prompt就需要进行集成ensemble,本文提出了两种集成方式:
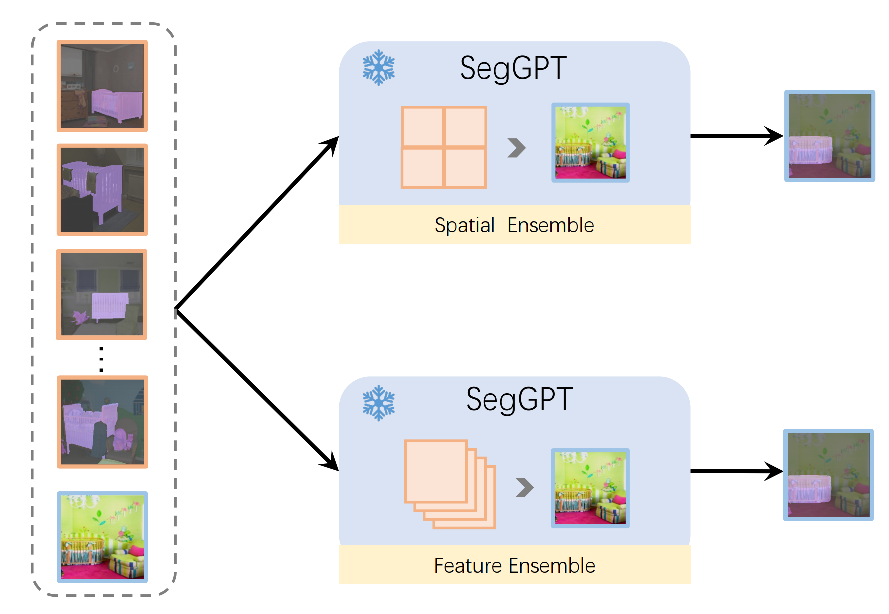
- the spatial ensemble (top) and the feature ensemble (bottom). The spatial ensemble strategy involves stitching multiple example images together and resizing them to the input resolution.
- The feature ensemble strategy averages features of the query image after each attention layer so that the query image aggregates all the reference examples.
3.3 In-Context Tuning
简而言之,就是对于特定任务,你如果认为随便找一张图片和对应的标签不具有代表性,可以将模型参数固定,初始化一个可学习的prompt图片,然后用同样的loss去更新prompt,这样,在推理阶段,可以直接使用这个迭代更新得到的prompt作为提示。
这个过程类似数据集蒸馏的过程,也就是说合成一张能够代表整个数据集的图片。

-
相关阅读:
基础课11——数据来源
使用tftpd更新开发板内核
pat乙级自我回顾:一般错误出现原因
使用Docker搭建分布式文件存储系统MinIO
华纳云:WordPress如何制作CMS栏目块
浅谈HTTP缓存与CDN缓存的那点事
vue 本地上传Excel文件并读取内容
命令执行(rce)
基于stm32移植使用u8g2 库
玩转地下管网三维建模:MagicPipe3D系统
- 原文地址:https://blog.csdn.net/xijuezhu8128/article/details/132841095