-
【数据分析】Python:处理缺失值的常见方法
在数据分析和机器学习中,缺失值是一种常见的现象。在实际数据集中,某些变量的某些条目可能没有可用的值。处理缺失值是一个重要的数据预处理步骤。在本文中,我们将介绍如何在 Pandas 中处理缺失值。
我们将探讨以下内容:
-
什么是缺失值;
-
如何在 Pandas 中识别缺失值;
-
处理缺失值的常见方法;
-
Pandas 中处理缺失值的代码示例;
- 我们还提供了一个随机生成的包含缺失值的较大数据集,可以使用这个数据集来练习和尝试这些方法。
===

01.什么是缺失值
缺失值是指数据集中某些变量的某些条目缺少值。这些条目可以是空值、NaN(不是数字)或其他标记。缺失值可能是由于数据输入错误、数据丢失或其他原因导致的。在分析数据集时,缺失值可能会影响结果,因此需要对其进行处理。在 Pandas 中,缺失数据由两个值表示:None:None 通常用于 Python 代码中的缺失数据,NaN :NaN(Not a Number 的首字母缩写词)。

02.如何在 Pandas 中识别缺失值
在 Pandas 中,我们可以使用 isnull() 或 notnull() 函数来识别缺失值。不同之处在于,isnull()函数发现数据中有空值或缺失值的时候返回True,notnull()返回的是False。 这些函数返回一个布尔数组,该数组指示每个元素是否为空值。例如,假设我们有一个数据框 df,我们可以使用以下代码检查缺失值。
import pandas as pd # 创建一个包含缺失值的数据框 df = pd.DataFrame({‘A’: [1, 2, None, 4, None], ‘B’: [5, None, 7, 8, None]}) # 检查数据框中的缺失值 print(df.isnull()) df
输出结果为,如下在第3行第1列和第2行第2列存在缺失值。
A B 0 False False 1 False True 2 True False 3 False False 4 True True Out\[2\]: A B 0 1.0 5.0 1 2.0 NaN 2 NaN 7.0 3 4.0 8.0- 1
上述代码将检查 df 数据框中的缺失值,并返回一个布尔数组,该数组指示每个元素是否为空值。True 表示该元素是一个缺失值。


03.处理缺失值的常见方法
在处理缺失值时,我们有许多方法可供选择。下面是一些常见的方法,函数形式:dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
3.1
删除缺失值
删除缺失值是处理缺失值的最简单方法之一。我们可以使用 dropna() 函数从数据框中删除包含缺失值的行或列。例如,如果我们希望删除包含任何缺失值的行,我们可以使用以下代码,其中how默认参数为’any’。
# 删除包含任何缺失值的行 df.dropna()
删除时,有一个how参数介绍如下:
**how:**筛选方式。'any’,表示该行/列只要有一个以上的空值,就删除该行/列;'all’,表示该行/列全部都为空值,就删除该行/列。
我们可以使用以下代码,其中参数all表示该行/列全部都为空值,就删除该行/列。
# 删除的行和列必须都为空值 df.dropna(how=‘all’)
如下所示,第一行代码将所有存在空值的行删除,而第二行代码只是将最后一行全空的值删除。

如果我们希望只要出现缺失值,就删除所在的行,我们可以使用以下代码,设置参数为’any’。
# 只要出现缺失值,就删除 df.dropna(how=‘any’)
如果我们希望删除包含缺失值的列,我们可以使用以下代码:
# 删除包含缺失值的列 df.dropna(axis=1)- 1
如下所示,其中df是原始的值,运行结果如下可对照结果进行分析。

3.2
替换缺失值
替换缺失值是处理缺失值的另一种常见方法。我们可以使用 fillna() 函数将缺失值替换为其他值。例如,如果我们希望将缺失值替换为 0,我们可以使用以下代码:
# 将缺失值替换为 0 df.fillna(0)
我们还可以使用其他值来替换缺失值。例如,我们可以使用以下代码将缺失值替换为每列的平均值:
# 将缺失值替换为每列的平均值 df.fillna(df.mean())- 1
- 2
- 3
- 4
- 5
两处代码的运行结果如下所示,分别对应原始值、缺失值替换。

3.3
插值缺失值
插值是一种更高级的缺失值处理方法。它可以使用现有数据来推断缺失值。我们可以使用 interpolate() 函数在 Pandas 中进行插值。例如,我们可以使用以下代码在每列上进行线性插值:
# 线性插值 df.fillna(df.interpolate())


04.Pandas 中处理缺失值的完整代码示例
下面是完整的在 Pandas 中处理缺失值的代码示例:
import pandas as pd # 创建一个包含缺失值的数据框 df = pd.DataFrame({'A': \[1, 2, None, 4\], 'B': \[5, None, 7, 8\]}) # 检查数据框中的缺失值 print(df.isnull()) # 删除包含任何缺失值的行 print(df.dropna()) # 删除整行都是缺失值的行 print(df.dropna(how='all')) # 删除包含任何缺失值的行 df.dropna(how='any') # 删除包含缺失值的列 print(df.dropna(axis=1)) # 将缺失值替换为 0 print(df.fillna(0)) # 将缺失值替换为每列的平均值 print(df.fillna(df.mean())) # 线性插值 print(df.interpolate()) print(df.fillna(df.interpolate()))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如上所示,我们先介绍了如何在 Pandas 中处理缺失值。我们讨论了如何识别缺失值,并介绍了处理缺失值的常见方法。我们还提供了一些代码示例,以便您可以在自己的项目中使用。处理缺失值是数据预处理的重要步骤,等下我们再介绍一些高级的缺失值处理方法。

05.高级缺失值处理方法
除了前面提到的基本缺失值处理方法,还有一些高级缺失值处理方法,可以进一步提高数据处理的精度。
5.1
多重插补
多重插补是一种使用现有数据集中其他相关变量的信息来推断缺失值的方法。在 Pandas 中,我们可以使用 fancyimpute 库来执行多重插补。以下是一个示例,结果也如下所示。
from fancyimpute import IterativeImputer # 创建一个包含缺失值的数据框 df = pd.DataFrame({‘A’: [1, 2, None, 4,None], ‘B’: [5, None, 7, 8, None]}) # 使用多重插补 imputer = IterativeImputer() imputed_df = imputer.fit_transform(df) imputed_df

5.2
高级回归模型
对于更复杂的数据集,使用高级回归模型可以进一步提高缺失值处理的精度。例如,可以使用 XGBoost 或 LightGBM 等模型来处理缺失值。以下是一个使用 LightGBM 处理缺失值的示例:
import lightgbm as lgb # 创建一个包含缺失值的数据框 df = pd.DataFrame({'A': \[1, 2, None, 4,None\], 'B': \[5, None, 7, 8, None\]}) # 定义 LightGBM 模型 params = { 'objective': 'regression', 'metric': 'mse', 'num\_leaves': 5, 'learning\_rate': 0.05, 'feature\_fraction': 0.5 } # 使用 LightGBM 处理缺失值 dtrain = lgb.Dataset(df.drop('A', axis=1), label=df\['A'\].dropna()) gbm = lgb.train(params, dtrain) df\['A'\] = gbm.predict(df.drop('A', axis=1))- 1
- 2
- 3
- 4
- 5
当然这个代码我们还在调试中呀,可以自己复制运行下~只有自己写了才会更加熟悉代码呀。


结论

在数据处理中,处理缺失值是非常重要的。在 Pandas 中,我们可以使用多种方法来处理缺失值,包括删除包含缺失值的行或列、替换缺失值和插值缺失值等基本方法。此外,我们还可以使用多重插补和高级回归模型等高级方法来提高缺失值处理的精度。希望本文能够帮助更好地处理缺失值,提高数据处理的效率和精度。
---------------------------END--------------------------- 题外话
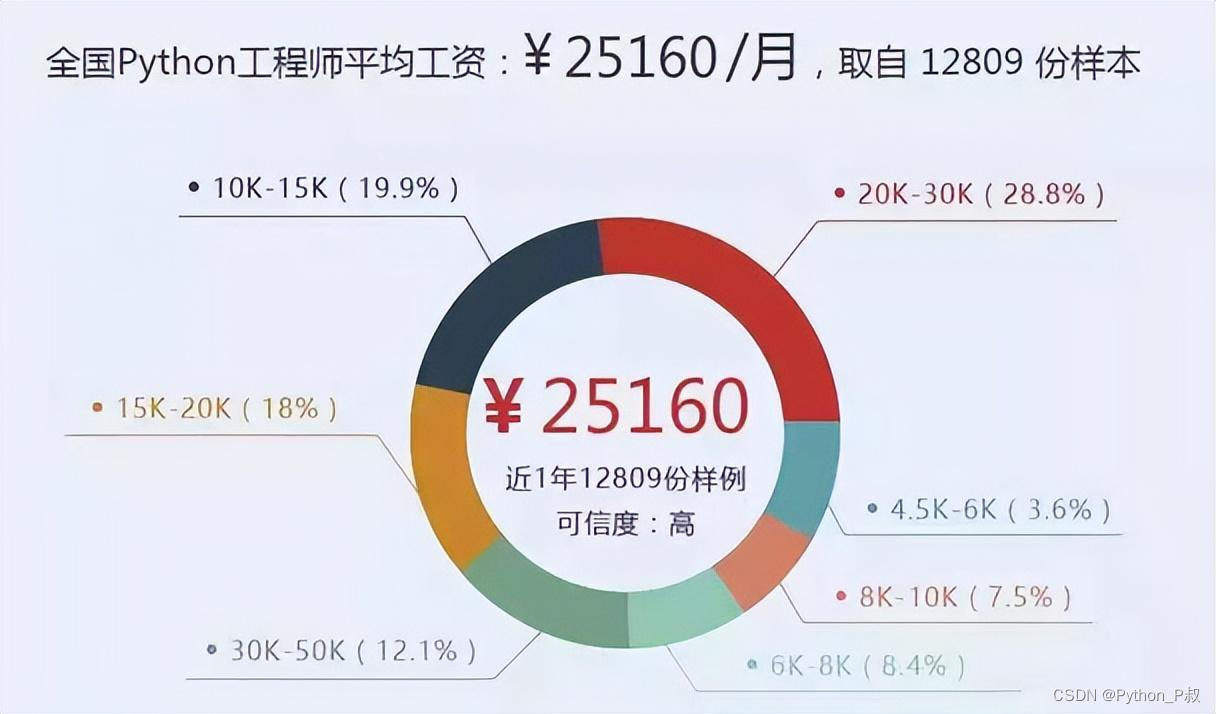
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!

三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典
简历模板

👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
若有侵权,请联系删除
-
-
相关阅读:
OpenHarmony NXP S32K148移植日记
VPN创建连接 提示错误 628: 在连接完成前,连接被远程计算机终止。
NX二次开发-通过点击按钮来控制显示工具条
html好看的文字特效
【Rust日报】2023-11-20 伪共享也可能发生在你身上
【从0到1进阶Redis】主从复制 — 主从机宕机测试
岛屿的周长
*算法训练(leetcode)第二十五天 | 134. 加油站、135. 分发糖果、860. 柠檬水找零、406. 根据身高重建队列
tinyxml
Jmeter测试关联接口
- 原文地址:https://blog.csdn.net/aobulaien001/article/details/132773453