-
pytorch异常——loss异常,不断增大,并且loss出现inf
异常报错
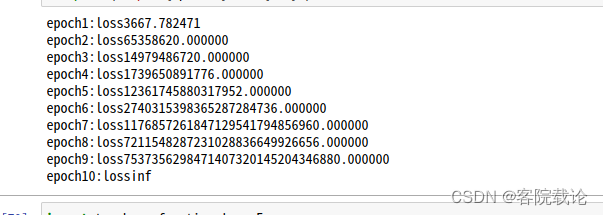
epoch1:loss3667.782471 epoch2:loss65358620.000000 epoch3:loss14979486720.000000 epoch4:loss1739650891776.000000 epoch5:loss12361745880317952.000000 epoch6:loss2740315398365287284736.000000 epoch7:loss1176857261847129541794856960.000000 epoch8:loss7211548287231028836649926656.000000 epoch9:loss7537356298471407320145204346880.000000 epoch10:lossinf- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
异常截图
异常代码
# 初始化模型的参数,使用正态分布来初始化权重参数,将偏置设置为0 net[0].weight.data.normal_(0,0.01) net[0].bias.data.fill_(0) # 定义损失函数 loss = nn.MSELoss() # 定义优化算法 trainer = torch.optim.SGD(net.parameters(),lr = 0.03) # 训练 # 训练过程:遍历完整的数据集,每一次都是抽取一个batch_size,然后在进行前向传播计算对应的loss,然后将loss反向传播,计算梯度,然后根据梯度优化参数 num_epochs = 10 for epoch in range(num_epochs): for X,y in data_iter: l = loss(net(X),y) l.backward() trainer.step() l = loss(net(features),labels) print(f'epoch{epoch+1}:loss{l:f}')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
原因解释
-
每一个batch_size之后,都没有进行梯度清零,模型参数更新是基于之前所有的mini_batch,并不是基于当前的mini_batch
-
导致如下问题
- 梯度爆炸:如果梯度值在每次迭代中都相对较大,那么累积梯度可能会迅速变得非常大,导致权重更新太过极端。这通常会导致损失值变成 NaN 或 Inf
- 训练不稳定:如果梯度值在每次迭代中都相对较大,那么累积梯度可能会迅速变得非常大,导致权重更新太过极端。这通常会导致损失值变成 NaN 或 Inf
-
梯度下降的基本假设:
- 每次更新都是基于最近一次计算出的梯度,
修正代码
# 初始化模型的参数,使用正态分布来初始化权重参数,将偏置设置为0 net[0].weight.data.normal_(0,0.01) net[0].bias.data.fill_(0) # 定义损失函数 loss = nn.MSELoss() # 定义优化算法 trainer = torch.optim.SGD(net.parameters(),lr = 0.03) # 训练 # 训练过程:遍历完整的数据集,每一次都是抽取一个batch_size,然后在进行前向传播计算对应的loss,然后将loss反向传播,计算梯度,然后根据梯度优化参数 num_epochs = 10 for epoch in range(num_epochs): for X,y in data_iter: l = loss(net(X),y) trainer.zero_grad() l.backward() trainer.step() l = loss(net(features),labels) print(f'epoch{epoch+1}:loss{l:f}')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
执行结果

-
相关阅读:
21.ref属性
微擎模块 抽奖天天乐1.3.3小程序开源未加密版 前端+后端
KQL和Lucene的区别
SpingBoot快速入门下
NoSQL数据库之MongoDB
Day4:Linux系统编程1-60P
MySQL数据库干货_20——MySQL中的索引【附有详细代码】
C++day07(auto、lambda、类型转换、STL、文件操作)
Android Framework——进程间通讯学习,从Binder使用看起
Cache系列直播,这次真的来了!
- 原文地址:https://blog.csdn.net/Blackoutdragon/article/details/132591256
