-
逻辑回归Logistic
回归 概念
假设现在有一些数据点,我们用一条直线对这些点进行拟合(这条直线称为最佳拟合直线),这个拟合的过程就叫做回归。进而可以得到对这些点的拟合直线方程。
最后结果用sigmoid函数输出
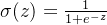
因此,为了实现 Logistic 回归分类器,我们可以在每个特征上都乘以一个回归系数(如下公式所示),然后把所有结果值相加,将这个总和代入 Sigmoid 函数中,进而得到一个范围在 0~1 之间的数值。任何大于 0.5 的数据被分入 1 类,小于 0.5 即被归入 0 类。所以,Logistic 回归也是一种概率估计,比如这里Sigmoid 函数得出的值为0.5,可以理解为给定数据和参数,数据被分入 1 类的概率为0.5
逻辑回归实际上就是一层神经网络
sigmoid函数的输入

梯度上升
梯度=梯度值+梯度方向
要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为 ▽ ,则函数 f(x, y) 的梯度由下式表示:

上式表示要沿x的方向移动
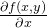 ,沿y方向移动
,沿y方向移动 。其中,函数f(x,y)必须要在待计算的点上有定义并且可微。
。其中,函数f(x,y)必须要在待计算的点上有定义并且可微。
梯度下降和梯度上升:
其实这个两个方法在此情况下本质上是相同的。关键在于代价函数(cost function)或者叫目标函数(objective function)。如果目标函数是损失函数,那就是最小化损失函数来求函数的最小值,就用梯度下降。 如果目标函数是似然函数(Likelihood function),就是要最大化似然函数来求函数的最大值,那就用梯度上升。在逻辑回归中, 损失函数和似然函数无非就是互为正负关系。
只需要在迭代公式中的加法变成减法。因此,对应的公式可以写成

- from __future__ import print_function
- from numpy import *
- import matplotlib.pyplot as plt
- # ---------------------------------------------------------------------------
- # 使用 Logistic 回归在简单数据集上的分类
- # 解析数据
- def loadDataSet(file_name):
- '''
- Desc:
- 加载并解析数据
- Args:
- file_name -- 文件名称,要解析的文件所在磁盘位置
- Returns:
- dataMat -- 原始数据的特征
- labelMat -- 原始数据的标签,也就是每条样本对应的类别
- '''
- # dataMat为原始数据, labelMat为原始数据的标签
- dataMat = []
- labelMat = []
- fr = open(file_name)
- for line in fr.readlines():
- lineArr = line.strip().split()
- if len(lineArr) == 1:
- continue # 这里如果就一个空的元素,则跳过本次循环
- # 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0
- dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
- labelMat.append(int(lineArr[2]))
- return dataMat, labelMat
- # sigmoid跳跃函数
- def sigmoid(inX):
- # return 1.0 / (1 + exp(-inX))
- # Tanh是Sigmoid的变形,与 sigmoid 不同的是,tanh 是0均值的。因此,实际应用中,tanh 会比 sigmoid 更好。
- return 2 * 1.0/(1+exp(-2*inX)) - 1
- # 正常的处理方案
- # 两个参数: 第一个参数==> dataMatIn 是一个2维NumPy数组,每列分别代表每个不同的特征,每行则代表每个训练样本。
- # 第二个参数==> classLabels 是类别标签,它是一个 1*100 的行向量。为了便于矩阵计算,需要将该行向量转换为列向量,做法是将原向量转置,再将它赋值给labelMat。
- def gradAscent(dataMatIn, classLabels):
- '''
- Desc:
- 正常的梯度上升法
- Args:
- dataMatIn -- 输入的 数据的特征 List
- classLabels -- 输入的数据的类别标签
- Returns:
- array(weights) -- 得到的最佳回归系数
- '''
- # 转化为矩阵[[1,1,2],[1,1,2]....]
- dataMatrix = mat(dataMatIn) # 转换为 NumPy 矩阵
- # 转化为矩阵[[0,1,0,1,0,1.....]],并转制[[0],[1],[0].....]
- # transpose() 行列转置函数
- # 将行向量转化为列向量 => 矩阵的转置
- labelMat = mat(classLabels).transpose() # 首先将数组转换为 NumPy 矩阵,然后再将行向量转置为列向量
- # m->数据量,样本数 n->特征数
- m, n = shape(dataMatrix)
- # print m, n, '__'*10, shape(dataMatrix.transpose()), '__'*100
- # alpha代表向目标移动的步长
- alpha = 0.001
- # 迭代次数
- maxCycles = 500
- # 生成一个长度和特征数相同的矩阵,此处n为3 -> [[1],[1],[1]]
- # weights 代表回归系数, 此处的 ones((n,1)) 创建一个长度和特征数相同的矩阵,其中的数全部都是 1
- weights = ones((n, 1))
- for k in range(maxCycles): # heavy on matrix operations
- # m*3 的矩阵 * 3*1 的单位矩阵 = m*1的矩阵
- # 那么乘上单位矩阵的意义,就代表: 通过公式得到的理论值
- # 参考地址: 矩阵乘法的本质是什么? https://www.zhihu.com/question/21351965/answer/31050145
- # print 'dataMatrix====', dataMatrix
- # print 'weights====', weights
- # n*3 * 3*1 = n*1
- h = sigmoid(dataMatrix * weights) # 矩阵乘法
- # print 'hhhhhhh====', h
- # labelMat是实际值
- error = (labelMat - h) # 向量相减
- # 0.001* (3*m)*(m*1) 表示在每一个列上的一个误差情况,最后得出 x1,x2,xn的系数的偏移量
- weights = weights + alpha * dataMatrix.transpose() * error # 矩阵乘法,最后得到回归系数
- return array(weights)
- # 随机梯度下降
- # 梯度下降优化算法在每次更新数据集时都需要遍历整个数据集,计算复杂都较高
- # 随机梯度下降一次只用一个样本点来更新回归系数
- def stocGradAscent0(dataMatrix, classLabels):
- '''
- Desc:
- 随机梯度下降,只使用一个样本点来更新回归系数
- Args:
- dataMatrix -- 输入数据的数据特征(除去最后一列)
- classLabels -- 输入数据的类别标签(最后一列数据)
- Returns:
- weights -- 得到的最佳回归系数
- '''
- m, n = shape(dataMatrix)
- alpha = 0.01
- # n*1的矩阵
- # 函数ones创建一个全1的数组
- weights = ones(n) # 初始化长度为n的数组,元素全部为 1
- for i in range(m):
- # sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn,此处求出的 h 是一个具体的数值,而不是一个矩阵
- h = sigmoid(sum(dataMatrix[i] * weights))
- # print 'dataMatrix[i]===', dataMatrix[i]
- # 计算真实类别与预测类别之间的差值,然后按照该差值调整回归系数
- error = classLabels[i] - h
- # 0.01*(1*1)*(1*n)
- # print weights, "*" * 10, dataMatrix[i], "*" * 10, error
- weights = weights + alpha * error * dataMatrix[i]
- return weights
- # 随机梯度下降算法(随机化)
- def stocGradAscent1(dataMatrix, classLabels, numIter=150):
- '''
- Desc:
- 改进版的随机梯度下降,使用随机的一个样本来更新回归系数
- Args:
- dataMatrix -- 输入数据的数据特征(除去最后一列数据)
- classLabels -- 输入数据的类别标签(最后一列数据)
- numIter=150 -- 迭代次数
- Returns:
- weights -- 得到的最佳回归系数
- '''
- m, n = shape(dataMatrix)
- weights = ones(n) # 创建与列数相同的矩阵的系数矩阵,所有的元素都是1
- # 随机梯度, 循环150,观察是否收敛
- for j in range(numIter):
- # [0, 1, 2 .. m-1]
- dataIndex = range(m)
- for i in range(m):
- # i和j的不断增大,导致alpha的值不断减少,但是不为0
- alpha = 4 / (
- 1.0 + j + i
- ) + 0.0001 # alpha 会随着迭代不断减小,但永远不会减小到0,因为后边还有一个常数项0.0001
- # 随机产生一个 0~len()之间的一个值
- # random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。
- randIndex = int(random.uniform(0, len(dataIndex)))
- # sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn
- h = sigmoid(sum(dataMatrix[dataIndex[randIndex]] * weights))
- error = classLabels[dataIndex[randIndex]] - h
- # print weights, '__h=%s' % h, '__'*20, alpha, '__'*20, error, '__'*20, dataMatrix[randIndex]
- weights = weights + alpha * error * dataMatrix[dataIndex[randIndex]]
- del (dataIndex[randIndex])
- return weights
- # 可视化展示
- def plotBestFit(dataArr, labelMat, weights):
- '''
- Desc:
- 将我们得到的数据可视化展示出来
- Args:
- dataArr:样本数据的特征
- labelMat:样本数据的类别标签,即目标变量
- weights:回归系数
- Returns:
- None
- '''
- n = shape(dataArr)[0]
- xcord1 = []
- ycord1 = []
- xcord2 = []
- ycord2 = []
- for i in range(n):
- if int(labelMat[i]) == 1:
- xcord1.append(dataArr[i, 1])
- ycord1.append(dataArr[i, 2])
- else:
- xcord2.append(dataArr[i, 1])
- ycord2.append(dataArr[i, 2])
- fig = plt.figure()
- ax = fig.add_subplot(111)
- ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
- ax.scatter(xcord2, ycord2, s=30, c='green')
- x = arange(-3.0, 3.0, 0.1)
- """
- y的由来,卧槽,是不是没看懂?
- 首先理论上是这个样子的。
- dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
- w0*x0+w1*x1+w2*x2=f(x)
- x0最开始就设置为1叻, x2就是我们画图的y值,而f(x)被我们磨合误差给算到w0,w1,w2身上去了
- 所以: w0+w1*x+w2*y=0 => y = (-w0-w1*x)/w2
- """
- y = (-weights[0] - weights[1] * x) / weights[2]
- ax.plot(x, y)
- plt.xlabel('X')
- plt.ylabel('Y')
- plt.show()
- def simpleTest():
- # 1.收集并准备数据
- dataMat, labelMat = loadDataSet("data/5.Logistic/TestSet.txt")
- # print dataMat, '---\n', labelMat
- # 2.训练模型, f(x)=a1*x1+b2*x2+..+nn*xn中 (a1,b2, .., nn).T的矩阵值
- # 因为数组没有是复制n份, array的乘法就是乘法
- dataArr = array(dataMat)
- # print dataArr
- # weights = gradAscent(dataArr, labelMat)
- # weights = stocGradAscent0(dataArr, labelMat)
- weights = stocGradAscent1(dataArr, labelMat)
- # print '*'*30, weights
- # 数据可视化
- plotBestFit(dataArr, labelMat, weights)
- # --------------------------------------------------------------------------------
- # 从疝气病症预测病马的死亡率
- # 分类函数,根据回归系数和特征向量来计算 Sigmoid的值
- def classifyVector(inX, weights):
- '''
- Desc:
- 最终的分类函数,根据回归系数和特征向量来计算 Sigmoid 的值,大于0.5函数返回1,否则返回0
- Args:
- inX -- 特征向量,features
- weights -- 根据梯度下降/随机梯度下降 计算得到的回归系数
- Returns:
- 如果 prob 计算大于 0.5 函数返回 1
- 否则返回 0
- '''
- prob = sigmoid(sum(inX * weights))
- if prob > 0.5: return 1.0
- else: return 0.0
- # 打开测试集和训练集,并对数据进行格式化处理
- def colicTest():
- '''
- Desc:
- 打开测试集和训练集,并对数据进行格式化处理
- Args:
- None
- Returns:
- errorRate -- 分类错误率
- '''
- frTrain = open('data/5.Logistic/horseColicTraining.txt')
- frTest = open('data/5.Logistic/horseColicTest.txt')
- trainingSet = []
- trainingLabels = []
- # 解析训练数据集中的数据特征和Labels
- # trainingSet 中存储训练数据集的特征,trainingLabels 存储训练数据集的样本对应的分类标签
- for line in frTrain.readlines():
- currLine = line.strip().split('\t')
- lineArr = []
- for i in range(21):
- lineArr.append(float(currLine[i]))
- trainingSet.append(lineArr)
- trainingLabels.append(float(currLine[21]))
- # 使用 改进后的 随机梯度下降算法 求得在此数据集上的最佳回归系数 trainWeights
- trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 500)
- # trainWeights = stocGradAscent0(array(trainingSet), trainingLabels)
- errorCount = 0
- numTestVec = 0.0
- # 读取 测试数据集 进行测试,计算分类错误的样本条数和最终的错误率
- for line in frTest.readlines():
- numTestVec += 1.0
- currLine = line.strip().split('\t')
- lineArr = []
- for i in range(21):
- lineArr.append(float(currLine[i]))
- if int(classifyVector(array(lineArr), trainWeights)) != int(
- currLine[21]):
- errorCount += 1
- errorRate = (float(errorCount) / numTestVec)
- print("the error rate of this test is: %f" % errorRate)
- return errorRate
- # 调用 colicTest() 10次并求结果的平均值
- def multiTest():
- numTests = 10
- errorSum = 0.0
- for k in range(numTests):
- errorSum += colicTest()
- print("after %d iterations the average error rate is: %f" % (numTests, errorSum / float(numTests)))
- simpleTest()
- # multiTest()
- # 逻辑回归中的 L1 惩罚和稀缺性 L1 Penalty and Sparsity in Logistic Regression
- print(__doc__)
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.linear_model import LogisticRegression
- from sklearn import datasets
- from sklearn.preprocessing import StandardScaler
- digits = datasets.load_digits()
- X, y = digits.data, digits.target
- X = StandardScaler().fit_transform(X)
- # 将大小数字分类为小
- y = (y > 4).astype(np.int)
- # 设置正则化参数
- for i, C in enumerate((100, 1, 0.01)):
- # 减少训练时间短的容忍度
- clf_l1_LR = LogisticRegression(C=C, penalty='l1', tol=0.01)
- clf_l2_LR = LogisticRegression(C=C, penalty='l2', tol=0.01)
- clf_l1_LR.fit(X, y)
- clf_l2_LR.fit(X, y)
- coef_l1_LR = clf_l1_LR.coef_.ravel()
- coef_l2_LR = clf_l2_LR.coef_.ravel()
- # coef_l1_LR contains zeros due to the
- # L1 sparsity inducing norm
- # 由于 L1 稀疏诱导规范,coef_l1_LR 包含零
- sparsity_l1_LR = np.mean(coef_l1_LR == 0) * 100
- sparsity_l2_LR = np.mean(coef_l2_LR == 0) * 100
- print("C=%.2f" % C)
- print("Sparsity with L1 penalty: %.2f%%" % sparsity_l1_LR)
- print("score with L1 penalty: %.4f" % clf_l1_LR.score(X, y))
- print("Sparsity with L2 penalty: %.2f%%" % sparsity_l2_LR)
- print("score with L2 penalty: %.4f" % clf_l2_LR.score(X, y))
- l1_plot = plt.subplot(3, 2, 2 * i + 1)
- l2_plot = plt.subplot(3, 2, 2 * (i + 1))
- if i == 0:
- l1_plot.set_title("L1 penalty")
- l2_plot.set_title("L2 penalty")
- l1_plot.imshow(np.abs(coef_l1_LR.reshape(8, 8)), interpolation='nearest',
- cmap='binary', vmax=1, vmin=0)
- l2_plot.imshow(np.abs(coef_l2_LR.reshape(8, 8)), interpolation='nearest',
- cmap='binary', vmax=1, vmin=0)
- plt.text(-8, 3, "C = %.2f" % C)
- l1_plot.set_xticks(())
- l1_plot.set_yticks(())
- l2_plot.set_xticks(())
- l2_plot.set_yticks(())
- plt.show()
- # 具有 L1-逻辑回归的路径
- from datetime import datetime
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn import linear_model
- from sklearn import datasets
- from sklearn.svm import l1_min_c
- iris = datasets.load_iris()
- X = iris.data
- y = iris.target
- X = X[y != 2]
- y = y[y != 2]
- X -= np.mean(X, 0)
- cs = l1_min_c(X, y, loss='log') * np.logspace(0, 3)
- print("Computing regularization path ...")
- start = datetime.now()
- clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
- coefs_ = []
- for c in cs:
- clf.set_params(C=c)
- clf.fit(X, y)
- coefs_.append(clf.coef_.ravel().copy())
- print("This took ", datetime.now() - start)
- coefs_ = np.array(coefs_)
- plt.plot(np.log10(cs), coefs_)
- ymin, ymax = plt.ylim()
- plt.xlabel('log(C)')
- plt.ylabel('Coefficients')
- plt.title('Logistic Regression Path')
- plt.axis('tight')
- plt.show()
- # 绘制多项式和一对二的逻辑回归 Plot multinomial and One-vs-Rest Logistic Regression
- print(__doc__)
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn.datasets import make_blobs
- from sklearn.linear_model import LogisticRegression
- # 制作 3 类数据集进行分类
- centers = [[-5, 0], [0, 1.5], [5, -1]]
- X, y = make_blobs(n_samples=1000, centers=centers, random_state=40)
- transformation = [[0.4, 0.2], [-0.4, 1.2]]
- X = np.dot(X, transformation)
- for multi_class in ('multinomial', 'ovr'):
- clf = LogisticRegression(solver='sag', max_iter=100, random_state=42,
- multi_class=multi_class).fit(X, y)
- # 打印训练分数
- print("training score : %.3f (%s)" % (clf.score(X, y), multi_class))
- # 创建一个网格来绘制
- h = .02 # 网格中的步长
- x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
- y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
- xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
- np.arange(y_min, y_max, h))
- # 绘制决策边界。为此,我们将为网格 [x_min, x_max]x[y_min, y_max]中的每个点分配一个颜色。
- Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
- # 将结果放入彩色图
- Z = Z.reshape(xx.shape)
- plt.figure()
- plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
- plt.title("Decision surface of LogisticRegression (%s)" % multi_class)
- plt.axis('tight')
- # 将训练点也绘制进入
- colors = "bry"
- for i, color in zip(clf.classes_, colors):
- idx = np.where(y == i)
- plt.scatter(X[idx, 0], X[idx, 1], c=color, cmap=plt.cm.Paired)
- # 绘制三个一对数分类器
- xmin, xmax = plt.xlim()
- ymin, ymax = plt.ylim()
- coef = clf.coef_
- intercept = clf.intercept_
- def plot_hyperplane(c, color):
- def line(x0):
- return (-(x0 * coef[c, 0]) - intercept[c]) / coef[c, 1]
- plt.plot([xmin, xmax], [line(xmin), line(xmax)],
- ls="--", color=color)
- for i, color in zip(clf.classes_, colors):
- plot_hyperplane(i, color)
- plt.show()
- from __future__ import print_function
- # Logistic Regression 3-class Classifier 逻辑回归 3-类 分类器
- print(__doc__)
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn import linear_model, datasets
- # 引入一些数据来玩
- iris = datasets.load_iris()
- # 我们只采用样本数据的前两个feature
- X = iris.data[:, :2]
- Y = iris.target
- h = .02 # 网格中的步长
- logreg = linear_model.LogisticRegression(C=1e5)
- # 我们创建了一个 Neighbours Classifier 的实例,并拟合数据。
- logreg.fit(X, Y)
- # 绘制决策边界。为此我们将为网格 [x_min, x_max]x[y_min, y_max] 中的每个点分配一个颜色。
- x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
- y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
- xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
- Z = logreg.predict(np.c_[xx.ravel(), yy.ravel()])
- # 将结果放入彩色图中
- Z = Z.reshape(xx.shape)
- plt.figure(1, figsize=(4, 3))
- plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
- # 将训练点也同样放入彩色图中
- plt.scatter(X[:, 0], X[:, 1], c=Y, edgecolors='k', cmap=plt.cm.Paired)
- plt.xlabel('Sepal length')
- plt.ylabel('Sepal width')
- plt.xlim(xx.min(), xx.max())
- plt.ylim(yy.min(), yy.max())
- plt.xticks(())
- plt.yticks(())
- plt.show()
- # Logistic function 逻辑回归函数
- # 这个类似于咱们之前讲解 logistic 回归的 Sigmoid 函数,模拟的阶跃函数
- print(__doc__)
- import numpy as np
- import matplotlib.pyplot as plt
- from sklearn import linear_model
- # 这是我们的测试集,它只是一条直线,带有一些高斯噪声。
- xmin, xmax = -5, 5
- n_samples = 100
- np.random.seed(0)
- X = np.random.normal(size=n_samples)
- y = (X > 0).astype(np.float)
- X[X > 0] *= 4
- X += .3 * np.random.normal(size=n_samples)
- X = X[:, np.newaxis]
- # 运行分类器
- clf = linear_model.LogisticRegression(C=1e5)
- clf.fit(X, y)
- # 并且画出我们的结果
- plt.figure(1, figsize=(4, 3))
- plt.clf()
- plt.scatter(X.ravel(), y, color='black', zorder=20)
- X_test = np.linspace(-5, 10, 300)
- def model(x):
- return 1 / (1 + np.exp(-x))
- loss = model(X_test * clf.coef_ + clf.intercept_).ravel()
- plt.plot(X_test, loss, color='red', linewidth=3)
- ols = linear_model.LinearRegression()
- ols.fit(X, y)
- plt.plot(X_test, ols.coef_ * X_test + ols.intercept_, linewidth=1)
- plt.axhline(.5, color='.5')
- plt.ylabel('y')
- plt.xlabel('X')
- plt.xticks(range(-5, 10))
- plt.yticks([0, 0.5, 1])
- plt.ylim(-.25, 1.25)
- plt.xlim(-4, 10)
- plt.legend(('Logistic Regression Model', 'Linear Regression Model'),
- loc="lower right", fontsize='small')
- plt.show()
-
相关阅读:
悲观模式下分库分表合并迁移
网络工程师的关键任务:构建可靠的出海网络架构
nginx几个常见的配置项
【Oracle】Oracle系列之八--SQL查询
CEC2018:动态多目标测试函数DF6~DF9的PS及PF
【SSM框架 三】SpringMVC
Windows11安装SQL Server2019操作手册
Python编程 列表的操作(上)
【无标题】
ES6-解构赋值
- 原文地址:https://blog.csdn.net/qq_36973725/article/details/132627315
