-
【第八章 索引,索引结构,B-Tree,B+Tree,Hash,索引分类,聚集索引&二级索引,索引语法】
第八章 索引,索引结构,B-Tree,B+Tree,Hash,索引分类,聚集索引&二级索引,索引语法
1.索引:
①索引(index)是帮助MySQL高效获取数据的数据结构(有序)。
②特点:
 2.索引结构:
2.索引结构:
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构。
①索引结构:

②不同的存储引擎对于索引结构的支持情况:

3.B-Tree(多路平衡查找树):
①以一颗最大度数(max-degree)为5(5阶)的b-tree为例,那这个B树每个节点最多存储4个key,5个指针。
②树的度数指的是一个节点的子节点个数。
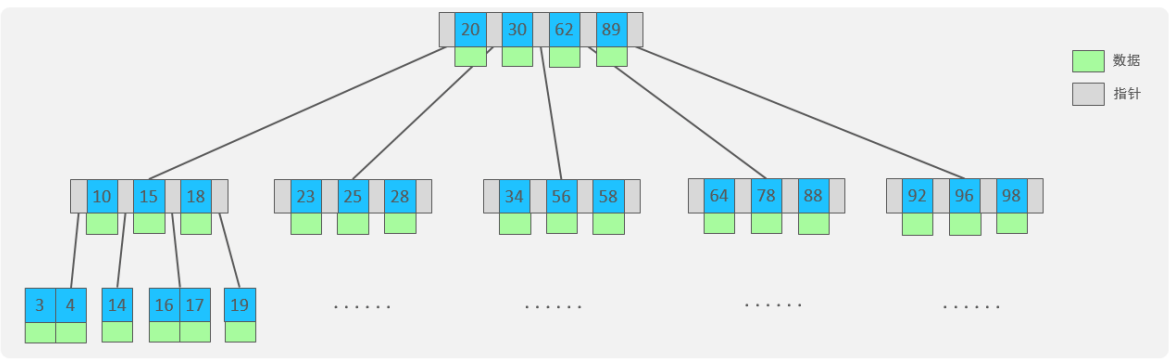
③特点:
(1)5阶的B树,每一个节点最多存储4个key,对应5个指针。
(2)一旦节点存储的key数量到达5,就会裂变,中间元素向上分裂。
(3)在B树中,非叶子节点和叶子节点都会存放数据。
4. B+Tree:
①B+Tree是B-Tree的变种,我们以一颗最大度数(max-degree)为4(4阶)的b+tree为例:

绿色框框起来的部分,是索引部分,仅仅起到索引数据的作用,不存储数据。
红色框框起来的部分,是数据存储部分,在其叶子节点中要存储具体的数据。
②B+Tree 与 B-Tree相比,主要有以下三点区别:
(1)所有的数据都会出现在叶子节点。
(2)叶子节点形成一个单向链表。
(3)非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的。
③MySQL中优化之后的B+Tree:MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能,利于排序。

5.Hash:
①哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
②如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
③特点:
(1)Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,…).
(2)无法利用索引完成排序操作。
(3)查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引。
④存储引擎支持:
在MySQL中,支持hash索引的是Memory存储引擎。 而InnoDB中具有自适应hash功能,hash索引是InnoDB存储引擎根据B+Tree索引在指定条件下自动构建的。
6.为什么InnoDB存储引擎选择使用B+tree索引结构?
①相对于二叉树,层级更少,搜索效率高;
②对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
③相对Hash索引,B+tree支持范围匹配及排序操作;
7.索引分类:
 8.聚集索引&二级索引:
8.聚集索引&二级索引:
①在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
 ②聚集索引选取规则:
②聚集索引选取规则:
如果存在主键,主键索引就是聚集索引。
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
③聚集索引的叶子节点下挂的是这一行的数据 。
二级索引的叶子节点下挂的是该字段值对应的主键值。

④回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。

9.InnoDB主键索引的B+tree高度为多高呢?

B+tree索引结构中,每一个节点最终存放在磁盘上就会存在一个页当中,一页的大小是固定的为16K,假设:一行数据大小为1k,一页中可以存储16行这样的数据。InnoDB的指针占用6个字节的空间(是固定的),key占用的字节取决于主键的类型(如int为4个字节),主键即使为bigint,占用字节数为8。 (1)高度为2:n为当前结点存储的key的数量,n+1为指针的数量。 n * 8 + (n + 1) * 6 = 16*1024 , 算出n约为 1170 1171* 16 = 18736 也就是说,如果树的高度为2,则可以存储 18000 多条记录。 (2)高度为3: 1171 * 1171 * 16 = 21939856 也就是说,如果树的高度为3,则可以存储 2200w 左右的记录。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
10.索引语法
(1)创建索引#唯一索引/全文索引 CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name ( index_col_name,... ); (2)查看索引: SHOW INDEX FROM table_name ; (3)删除索引: DROP INDEX index_name ON table_name ;- 1
- 2
- 3
- 4
- 5
- 6
①数据准备:
use itcast; CREATE TABLE tb_user ( id INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键', name VARCHAR(50) NOT NULL COMMENT '用户名', phone VARCHAR(11) NOT NULL COMMENT '手机号', email VARCHAR(100)<- 1
- 2
- 3
- 4
- 5
-
相关阅读:
【Java-LangChain:使用 ChatGPT API 搭建系统-9】评估(上)-存在一个简单的正确答案时
相比Vue和React,Svelte可能更适合你
【题解】[NOIP2015]扫雷游戏(Java & C++)
「网络编程」数据链路层协议_ 以太网协议学习
MybatisPlus处理业务数据新思路
从0到1学会Git(第三部分):Git的远程仓库链接与操作
Redis事务+watch+RDB+AOF+发布订阅+主从复制+哨兵模式+缓存穿透和雪崩及解决方案+使用watch实现秒杀相关
java封装,继承,多态
Cobalt Strike基本使用
[附源码]Python计算机毕业设计Django数字乡村基础治理系统
- 原文地址:https://blog.csdn.net/qq_43742813/article/details/128193152