-
八股文之jdk源码分析
JDK源码分析
String
通过加号拼接字符串分析
string字符串我们一般都是字面量赋值形式,声明的变量值放在常量池,一般字符串拼接,通过+形式,其实这是jdk做了优化,并不是表面看到连接符,比如说现在字符串a,字符串b,通过反编译对应字节码文件,加号变成
new stringbuilder,append方法,String 是不可变的对象(final), 因此在每次对 String 类型进行改变的时候其实都等同于在堆中生成了一个新的 String 对象,然后将指针指向新的 String 对象,这样不仅效率低下,而且大量浪费有限的内存空间,所以经常改变内容的字符串最好不要用 String 。因为每次生成对象都会对系统性能产生影响,特别是当内存中的无引用对象过多了以后, JVM 的 GC 开始工作,那速度是一定会相当慢的。另外当GC清理速度跟不上new String的速度时,还会导致内存溢出Error
list
ArrayList

初始化
重要属性
/** * Default initial capacity. 默认容量 */ private static final int DEFAULT_CAPACITY = 10; /** * Shared empty array instance used for empty instances. * 用于空实例的共享空数组实例 */ private static final Object[] EMPTY_ELEMENTDATA = {}; /** * Shared empty array instance used for default sized empty instances. We * distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when * first element is added. * 用于默认大小的空实例的共享空数组实例 * 我们区分这从EMPTY_ELEMENTDATA直到多少膨胀时添加第一个元素。 */ private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; /** * The array buffer into which the elements of the ArrayList are stored. * The capacity of the ArrayList is the length of this array buffer. Any * empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA * will be expanded to DEFAULT_CAPACITY when the first element is added. * 数组列表的元素存储在数组缓冲区中。ArrayList的容量就是这个数组缓冲区的长度 * 任何带elementData的空数组列表== DEFAULTCAPACITY_EMPTY_ELEMENTDATA将在添加第一个元素时扩展为DEFAULT_CAPACITY。 */ transient Object[] elementData; // non-private to simplify nested class access /** * The size of the ArrayList (the number of elements it contains). * 数组列表的大小 * @serial */ private int size;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
构造方法
/** * Constructs an empty list with the specified initial capacity. * * @param initialCapacity the initial capacity of the list * @throws IllegalArgumentException if the specified initial capacity * is negative */ public ArrayList(int initialCapacity) { if (initialCapacity > 0) { this.elementData = new Object[initialCapacity]; } else if (initialCapacity == 0) { this.elementData = EMPTY_ELEMENTDATA; } else { throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); } } /** * Constructs an empty list with an initial capacity of ten. * 创建一个list初始容量10 */ public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
add方法
/** * Appends the specified element to the end of this list. * 追加元素在list * @param e element to be appended to this list * @return true (as specified by {@link Collection#add}) */ public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!!增量 modCount elementData[size++] = e; return true; } /** * Inserts the specified element at the specified position in this * list. Shifts the element currently at that position (if any) and * any subsequent elements to the right (adds one to their indices). * 指定位置插入元素,后面元素向右移动 * @param index index at which the specified element is to be inserted * @param element element to be inserted * @throws IndexOutOfBoundsException {@inheritDoc} */ public void add(int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; } /** * 确保是否是第一次添加元素,如果是list初始化容量 * 否则判断是否需要扩容 **/ private void ensureCapacityInternal(int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCapacity); } /** * 判断是否需要扩容 **/ private void ensureExplicitCapacity(int minCapacity) { modCount++; // overflow-conscious code if (minCapacity - elementData.length > 0) grow(minCapacity); } /** * Increases the capacity to ensure that it can hold at least the * number of elements specified by the minimum capacity argument. * 1.5倍扩容 * @param minCapacity the desired minimum capacity */ private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
详细说明
当容器ArrayList第一次添加元素,调用add(E)方法,首先是判断是否是第一次添加元素,如果是初始化数组容量10
如果不是第一次元素,则判断添加该元素之后,是否容量是否够用;
如果不够用的话,进行扩容操作,原来数组元素+原来数组右移一位,调用arrays.copyOf(elementData,newCapacity);
get方法
/** * Returns the element at the specified position in this list. * 返回数据指定位置的元素 * @param index index of the element to return 数组中索引位置 * @return the element at the specified position in this list * @throws IndexOutOfBoundsException {@inheritDoc} */ public E get(int index) { rangeCheck(index); return elementData(index); } /** * Checks if the given index is in range. If not, throws an appropriate * runtime exception. This method does *not* check if the index is * negative: It is always used immediately prior to an array access, * which throws an ArrayIndexOutOfBoundsException if index is negative. * 方法不检查索引是否为负数,它只检查索引是否大于或等于数组的长度。 * 如果索引是负数,则数组访问会抛出ArrayIndexOutOfBoundsException。 */ private void rangeCheck(int index) { if (index >= size) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
详细说明
如果数组是个空数组,size 为 0 ,而你又去取第一个元素 get(0),元素都没有,所以就会报错。
list根据指定位置获取元素,首先判断位置是否大于数组长度,如果大于抛出IndexOutOfBoundsException异常
否则返回指定位置的元素
remove方法
/** * Removes the element at the specified position in this list. * Shifts any subsequent elements to the left (subtracts one from their * indices). * 移除指定位置元素 * 将所有后续元素向左移动(从它们的元素中减去1)*指数)。 * @param index the index of the element to be removed * @return the element that was removed from the list * @throws IndexOutOfBoundsException {@inheritDoc} */ public E remove(int index) { rangeCheck(index); // 数组结构性变化 modCount++ modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work return oldValue; } /** * Checks if the given index is in range. If not, throws an appropriate * runtime exception. This method does *not* check if the index is * negative: It is always used immediately prior to an array access, * which throws an ArrayIndexOutOfBoundsException if index is negative. * 方法不检查索引是否为负数,它只检查索引是否大于或等于数组的长度。 * 如果索引是负数,则数组访问会抛出ArrayIndexOutOfBoundsException。 */ private void rangeCheck(int index) { if (index >= size) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } /** * Removes the first occurrence of the specified element from this list, * if it is present. If the list does not contain the element, it is * unchanged. More formally, removes the element with the lowest index * i such that * (o==null ? get(i)==null : o.equals(get(i))) * (if such an element exists). Returns true if this list * contained the specified element (or equivalently, if this list * changed as a result of the call). * * @param o element to be removed from this list, if present * @return true if this list contained the specified element */ public boolean remove(Object o) { if (o == null) { for (int index = 0; index < size; index++) if (elementData[index] == null) { fastRemove(index); return true; } } else { for (int index = 0; index < size; index++) if (o.equals(elementData[index])) { fastRemove(index); return true; } } return false; } /* * Private remove method that skips bounds checking and does not * return the value removed. */ private void fastRemove(int index) { modCount++; int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
详细说明
1、根据指定位置移除元素
首先判断指定位置是否合法,看它是否大于数组长度,如果大于抛出IndexOutOfBoundsException异常
否则,指定位置合适,之后modCount++,由于数组结构性变化,之后看一下移除元素之后是否需要
移动元素,计算数组长度-1-指定位置 如果大于0,通过
System.arraycopy(elementData, index+1, elementData, index, numMoved); 左移,否则最后一个元素,不需要移动位置,最后一个位置置为null,这样方便之后将整个数组不再使用时,会被GC,数组长度-1 2、根据元素删除 首先判断指定元素是否null,如果 不为null,遍历数组找到元素对应索引位置,指定位置合适,之后modCount++,由于数组结构性变化,之后看一下移除元素之后是否需要 移动元素,计算数组长度-1-指定位置 如果大于0,通过System.arraycopy方法左移,否则最后一个元素,不需要移动位置,最后一个位置置为null,这样方便之后将整个数组不再使用时,会被GC ,数组长度-1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
set方法
/** * Replaces the element at the specified position in this list with * the specified element. * 使用指定元素替换指定位置的内容 * @param index index of the element to replace * @param element element to be stored at the specified position * @return the element previously at the specified position * @throws IndexOutOfBoundsException {@inheritDoc} */ public E set(int index, E element) { rangeCheck(index); E oldValue = elementData(index); elementData[index] = element; return oldValue; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
详细说明
首先判断指定位置是否合法,看它是否大于数组长度,如果大于抛出IndexOutOfBoundsException异常
否则,指定位置合适,直接赋值,返回老值
扩容grow方法
首先,对于ArrayList扩容,当调用无参构造new一个ArrayList时,此时size=0,数组为空。如果指定了数组大小的构造函数,或者是指定了collection元素的列表,这两个构造函数,初始值size就是自定义的了。
然后当执行add方法时,一定会先执行ensureCapacityInternal方法,参数叫做minCapacity(最小容量)=size+1。/** * Appends the specified element to the end of this list. * 追加元素在list * @param e element to be appended to this list * @return true (as specified by {@link Collection#add}) */ public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!!增量 modCount elementData[size++] = e; return true; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
而ensureCapacityInternal()函数里,还会计算一次最小容量,主要是给空参创建的加个默认容量,如果已经有容量了,不会进行更改。
private void ensureCapacityInternal(int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCapacity); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
扩容核心方法grow
/** * The maximum size of array to allocate. * Some VMs reserve some header words in an array. * Attempts to allocate larger arrays may result in * OutOfMemoryError: Requested array size exceeds VM limit */ private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; /** * Increases the capacity to ensure that it can hold at least the * number of elements specified by the minimum capacity argument. * * @param minCapacity the desired minimum capacity */ private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
可以看到newCapacity=oldCapacity+(oldCapacity >> 1);也就是旧容量的1.5倍。奇数的话最后一位的1会被消去。但是,新容量大小还要经历两次判断,最后才会执行copyOf函数。
一是如果新容量小于最小所需容量,可以知道,这种情况旧容量太大导致数值溢出,newCapacity数值溢出,小于minCapacity了。
二是判断新容量是不是大于最大数组长度(默认是Integer.MAX_VALUE-8),如果大于,就进到了这个函数private static int hugeCapacity(int minCapacity) { if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
hugeCapacity的逻辑主要是判断最小所需容量是不是已经<0了,会报OOM异常,大概是minCapacity=size+1.size=Integer.MAX_VALUE才会出现这种情况。
然后判断minCapacity是不是大于最大数组长度,如果是,新容量=Interger.MAX_VALUE(如果再次扩容,就会跑到上面的判断逻辑了,再次扩容 size+1会成负数了)。
如果还没有大于最大数组长度,就会新容量=最大数组长度。到此,新容量的计算就完成了,最后执行复制数组方法。扩容完成。
clear方法
/** * Removes all of the elements from this list. The list will * be empty after this call returns. */ public void clear() { modCount++; // clear to let GC do its work for (int i = 0; i < size; i++) elementData[i] = null; size = 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
遍历list,全部赋值null,不用的话让gc回收,最后数组长度变为0
modCount
问题复现
// 增强for循环 反编译之后发现是迭代器原型 ConcurrentModificationException for (String item:list){ if("abc".equals(item)){ list.add("增强for循环添加元素"); } } // 增强型for循环反编译之后就是迭代器遍历的 System.out.println(list); // 迭代器遍历添加元素 ConcurrentModificationException Iterator<String> listIterator = list.iterator(); while (listIterator.hasNext()) { if ("abc".equals(listIterator.next())) { list.add("迭代器添加元素"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

作用
Fail-Fast快速失败机制,遍历集合元素时候,如果集合结构发生了修改,立即抛出异常,以防止继续遍历。
记录了结构性改变的次数。结构性改变指的是那些修改了列表大小的操作,在迭代过程中可能会造成错误的结果。
解决方案
ListIterator<String> addListIterator = list.listIterator(); while (addListIterator.hasNext()){ if("胡一刀".equals(addListIterator.next())){ addListIterator.add("条小儿"); } } System.out.println("添加元素之后:"+list); // 方法二 for (int k = 0; k < list.size(); k++) { if ("苗人凤".equals(list.get(k))) { list.add( "10"); } } System.out.println(list);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
线程安全问题
/** * @Description 验证ArrayList多线程问题 */ @Test public void validListMultiThreads() throws InterruptedException { List<Integer> list = new ArrayList<>(); for (int i = 0; i < 4; i++) { new Thread(() -> { for (int j = 0; j <= 10000; j++) { list.add(new Random().nextInt(100)); } }).start(); } // 暂停线程的操作,精确到秒,线程暂停3秒,将其挂起 TimeUnit.SECONDS.sleep(3); System.out.println("size = " + list.size()); for (int i = 0; i < list.size(); i++) { if (null == list.get(i)) { System.out.println("error=========="); } } System.out.println("over==========="); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
两个问题
数组越界?
前提条件: 当前size=2 数组长度为2.
1、线程1 判断数组是否越界.因为size=2 长度为2,没有越界.将进行赋值操作.但是因为时间片问题导致了中断.
2、线程2 判断数组是否越界.因为size=2 长度为2,没有越界.将进行赋值操作.但是因为时间片问题导致了中断.
3、线程1 重新获取到主动权.上文判断了长度刚刚好够用.进行赋值操作element[size]=1,并且size++
4、线程2 因为上文判断了数组没有越界.所以进行赋值操作.但是此时的size=3了.再执行element[3]=2. 导致了数组越界了.数值为null?
线程1赋值操作element[0]=1,随后时间片用完了,中断,
线程2赋值操作element[0]=2,随后时间片用完了,中断
此处导致了之前所说的一个问题,后续线程将前面线程值覆盖了
线程1 自增 size++ size 2
线程2 自增 size size 3
此处导致了某些值为null的问题.因为原size=1, 但是因为线程1与线程2都将值赋值给了element[0],导致了element[1]内没有值,被跳过了.指针index指向了2.所以,导致了某些情况下值为null的情况.
解决方案一:同步
Collections.synchronizedList()方法其实底层也是在集合的所有方法之上加上了synchronized(默认使用的是同一个monitor对象,也可以自己指定)
public class UnsafeArrayList3 { public static void main(String[] args) { try { notThreadSafe(); } catch (Exception e) { e.printStackTrace(); } } public static void notThreadSafe() throws Exception{ final List<Integer> list = Collections.synchronizedList(new ArrayList<>()); for(int i=0;i<4;i++){ new Thread(()->{ for(int j=0;j<10000;j++){ list.add(new Random().nextInt(100)); } }).start(); } TimeUnit.SECONDS.sleep(3); System.out.println("size = "+list.size()); for(int i=0;i<list.size();i++){ if(null == list.get(i)){ System.out.println("error=========="); } } System.out.println("over==========="); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
解决方案二:COW
Copy On Write 也是一种重要的思想,在写少读多的场景下,为了保证集合的线程安全性,我们完全可以在当前线程中得到原始数据的一份拷贝,然后进行操作。
JDK集合框架中为我们提供了 ArrayList 的这样一个实现:CopyOnWriteArrayList。但是如果不是写少读多的场景,使用 CopyOnWriteArrayList 开销比较大,因为每次对其更新操作(add/set/remove)都会做一次数组拷贝。
/** * @Description 验证ArrayList多线程问题 */ @Test public void validListMultiThreads() throws InterruptedException { List<Integer> list = new CopyOnWriteArrayList<>(); for (int i = 0; i < 4; i++) { new Thread(() -> { for (int j = 0; j <= 10000; j++) { list.add(new Random().nextInt(100)); } }).start(); } // 暂停线程的操作,精确到秒,线程暂停3秒,将其挂起 TimeUnit.SECONDS.sleep(3); System.out.println("size = " + list.size()); for (int i = 0; i < list.size(); i++) { if (null == list.get(i)) { System.out.println("error=========="); } } System.out.println("over==========="); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
CopyOnWriteArrayList
属性介绍
/** The lock protecting all mutators 保护所有变量的锁 */ final transient ReentrantLock lock = new ReentrantLock(); /** The array, accessed only via getArray/setArray. * 这个数组只能通过getArray和setArray访问设置 * 通过“volatile数组”来保存数据的。一个线程读取volatile数组时,总能看到其它线程对该volatile变量最后的写入;就这样,通过volatile提供了“读取到的数据总是最新的”这个机制的 保证 **/ private transient volatile Object[] array; /** * Gets the array. Non-private so as to also be accessible * from CopyOnWriteArraySet class. */ final Object[] getArray() { return array; } /** * Sets the array. */ final void setArray(Object[] a) { array = a; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
初始化,构造方法
/** * @Description 无参构造 **/ public CopyOnWriteArrayList() { setArray(new Object[0]); } /** * Creates a list containing the elements of the specified * collection, in the order they are returned by the collection's * iterator. * * @param c the collection of initially held elements * @throws NullPointerException if the specified collection is null */ public CopyOnWriteArrayList(Collection<? extends E> c) { Object[] elements; if (c.getClass() == CopyOnWriteArrayList.class) elements = ((CopyOnWriteArrayList<?>)c).getArray(); else { elements = c.toArray(); // c.toArray might (incorrectly) not return Object[] (see 6260652) if (elements.getClass() != Object[].class) elements = Arrays.copyOf(elements, elements.length, Object[].class); } setArray(elements); } /** * Creates a list holding a copy of the given array. * 建一个包含给定数组副本的列表。 * @param toCopyIn the array (a copy of this array is used as the * internal array) * @throws NullPointerException if the specified array is null */ public CopyOnWriteArrayList(E[] toCopyIn) { setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
说明:setArray()的作用是给array赋值;其中,array是volatile transient
Object[]类型,即array是“volatile数组”。
关于volatile关键字,我们知道“volatile能让变量变得可见”,即对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。正在由于这种特性,每次更新了“volatile数组”之后,其它线程都能看到对它所做的更新。
关于transient关键字,它是在序列化中才起作用,transient变量不会被自动序列化。add
/** * Appends the specified element to the end of this list. * 将指定的元素追加到列表的末尾。 * @param e element to be appended to this list * @return {@code true} (as specified by {@link Collection#add}) */ public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1); newElements[len] = e; setArray(newElements); return true; } finally { lock.unlock(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
1 加锁(synchronized )。保证此时只有一个线程进入
2 获取原来的数组以及长度
3 复制新数据,并且长度+1
4 设置新数据(array使用volatile修饰,所以其他线程可见)
5 返回get
//根据index直接获取数组元素 // 不加锁 public E get(int index) { return elementAt(getArray(), index); }- 1
- 2
- 3
- 4
- 5
- 6
set
/** * Replaces the element at the specified position in this list with the * specified element. * 将列表中指定位置的元素替换为指定元素 * @throws IndexOutOfBoundsException {@inheritDoc} */ public E set(int index, E element) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); E oldValue = get(elements, index); if (oldValue != element) { int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len); newElements[index] = element; setArray(newElements); } else { // Not quite a no-op; ensures volatile write semantics setArray(elements); } return oldValue; } finally { lock.unlock(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
首先获取锁ReentrantLock,加锁,根据指定索引获取旧值,判断指定位置的新值与旧值是否相同,
不相同的话,数组拷贝,得到新数组新数组指定位置赋值操作,会通过将数据更新到volatile数组中
解锁
remove
/** * Removes the element at the specified position in this list. * Shifts any subsequent elements to the left (subtracts one from their * indices). Returns the element that was removed from the list. * 删除位于列表中指定位置的元素。 * 将所有后续元素向左平移(从它们的下标减去1) * @throws IndexOutOfBoundsException {@inheritDoc} */ public E remove(int index) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; E oldValue = get(elements, index); int numMoved = len - index - 1; if (numMoved == 0) setArray(Arrays.copyOf(elements, len - 1)); else { Object[] newElements = new Object[len - 1]; System.arraycopy(elements, 0, newElements, 0, index); System.arraycopy(elements, index + 1, newElements, index, numMoved); setArray(newElements); } return oldValue; } finally { lock.unlock(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
首先获取同一把锁,看一下怎么移动元素,根据 numMoved = len - index -1 ,如果删除最后一个元素直接返回新数组,新数组包含
除了最后一个元素的所有,如果不是最后一个元素的话,分两步拷贝首先将指定元素之前的内容拷贝新数组,之后将指定元素之后
所有内容拷贝到新数组,新数组赋值,解锁
// 关于Arrays.copyOf 数组拷贝 int[] arr=new int[]{1,2,3,4,5}; int[] ints = Arrays.copyOf(arr, 3); for(int i=0;i<ints.length;i++){ System.out.println(ints[i]); } // 1 // 2 // 3 // System.arraycopy 数组拷贝 int[] newArr=new int[4]; // arr:源数组 srcPos:源数组开始位置0,newArr:目标数组,destPos:目标数组开始位置0,length:拷贝长度2 // 拷贝所删除元素前面的元素到新数组 System.arraycopy(arr,0,newArr,0,2); // newArr 1,2 // 拷贝所删除元素后面的元素到新数组 // arr:源数组 srcPos:源数组开始位置3,newArr:目标数组,destPos:目标数组开始位置2,length:拷贝长度2 System.arraycopy(arr,3,newArr,2,2); // for(int i=0;i<newArr.length;i++){ System.out.println(newArr[i]); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
遍历
/** * Returns an iterator over the elements in this list in proper sequence. * 返回一个迭代器,以正确的顺序遍历列表中的元素。 *The returned iterator provides a snapshot of the state of the list * when the iterator was constructed. No synchronization is needed while * traversing the iterator. The iterator does NOT support the * {@code remove} method. * 返回的迭代器提供了列表状态的快照 当迭代器被构造时。此时不需要同步 * 遍历迭代器。迭代器不支持remove方法 * {@code remove}方法。 * @return an iterator over the elements in this list in proper sequence */
public Iterator<E> iterator() { return new COWIterator<E>(getArray(), 0); } static final class COWIterator<E> implements ListIterator<E> { /** Snapshot of the array 快照数组 */ private final Object[] snapshot; /** Index of element to be returned by subsequent call to next. * 后续调用next返回的元素的索引 */ private int cursor; private COWIterator(Object[] elements, int initialCursor) { cursor = initialCursor; snapshot = elements; } @SuppressWarnings("unchecked") public E next() { if (! hasNext()) throw new NoSuchElementException(); return (E) snapshot[cursor++]; } public boolean hasNext() { return cursor < snapshot.length; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
对于遍历删除问题复现
System.out.println("遍历cowlist"); CopyOnWriteArrayList<Integer> cowList = new CopyOnWriteArrayList<Integer>() {{ add(1); add(1); add(1); }}; Iterator<Integer> cowIterator = cowList.iterator(); while (cowIterator.hasNext()) { if (1 == cowIterator.next()) { cowIterator.remove(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

对于remove方法
/** * Not supported. Always throws UnsupportedOperationException. * @throws UnsupportedOperationException always; {@code remove} * is not supported by this iterator. * 迭代器遍历同时不支持删除操作 */ public void remove() { throw new UnsupportedOperationException(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
迭代器遍历同时修改,增加操作问题、
System.out.println("遍历cowlist"); CopyOnWriteArrayList<Integer> cowList = new CopyOnWriteArrayList<Integer>() {{ add(1); add(1); add(1); }}; Iterator<Integer> cowIterator = cowList.iterator(); while (cowIterator.hasNext()) { if (1 == cowIterator.next()) { int j = cowList.indexOf(new Integer(1)); cowList.set(j,23); // cowList.add(23); // cowIterator.remove() } System.out.println(cowIterator.next()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

基本原理
当向集合添加、移除元素时,并不是直接操作当前集合,而是首先对原集合进行拷贝、复制到一个新集合中。然后对该新集合进行添加、移除元素的操作。最后,再将对原集合的引用指向新集合即可。该机制的好处就在于当我们访问、读取集合是不需要加锁的,即COW机制是读写分离思想的具体体现。当然其弊端也是显而易见的,一方面由于写操作需要复制操作,所以对于较大规模的集合而言,其耗费的内存也是较为可观的;另一方面,由于读操作访问的是原集合,即使写操作在此期间已经完成。对于前者(读操作)而言也是不可见的,即其保证的是最终一致性
LinkedList

概述
(1)LinkedList底层维护了一个双向链表
(2)LinkedList中维护了两个属性first和last分别指向首节点和尾节点
(3)每个节点(Node对象)里又维护了prev(指向前一节点),next(指向后一节点),item(用于保存数据)三个属性,从而实现双链表
(4)因此元素的添加和删除效率较高
属性参数
transient int size = 0;//记录节点个数 transient Node<E> first;//first引用指向头节点 transient Node<E> last;//last引用指向尾节点- 1
- 2
- 3
- 4
- 5
- 6
构造函数
public LinkedList() { } public LinkedList(Collection<? extends E> c) { this();//调用无参构造器 addAll(c);//批量插入方法 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
插入数据
public boolean addAll(Collection c) { return addAll(size, c);//调用插入方法——addAll(int, Collection) } public boolean addAll(int index, Collection c) {//传入节点个数和初始化参数 checkPositionIndex(index);//检查下标合理性 Object[] a = c.toArray();//将c集合转换为Object数组a int numNew = a.length;//记录数组长度 if (numNew == 0)//数组长度为0 return false;//返回false,初始化失败 Nodepred, succ;//声明该节点的前驱节点和后继节点 if (index == size) {//如果下标等于节点个数,即从尾部加入 succ = null;//后继节点置空 pred = last;//前驱节点指向老链表的last节点 } else {//从指定位置添加节点 succ = node(index);//后继节点指向原index处节点 pred = succ.prev;//前驱节点指向原index处节点的前驱节点 } for (Object o : a) {//遍历存放c集合的数组a @SuppressWarnings("unchecked") E e = (E) o;//向下转换 Node newNode = new Node<>(pred, e, null);//新建节点存放元素 if (pred == null)//如果该节点的前驱节点为空,说明是头节点插入 first = newNode;//更新头节点 else pred.next = newNode;//将前驱节点和新节点关联 pred = newNode; } if (succ == null) {//后继节点为空,说明尾部插入 last = pred;//尾节点更新 } else {//不为空 pred.next = succ;//newNode指向后继节点 succ.prev = pred;//后继节点指向newNode } size += numNew;//元素长度更新 modCount++;//操作次数++ return true;//插入成功 } /** * 判断下标合理性 **/ private void checkPositionIndex(int index) { if (!isPositionIndex(index))//若下标不合理,则抛出异常 throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); } private boolean isPositionIndex(int index) {//下标大于等于0且小于等于size返回true return index >= 0 && index <= size; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
获取元素 返回原链表中index的节点
Node<E> node(int index) {//二分法查找法 // assert isElementIndex(index); if (index < (size >> 1)) {//index小于size的二分之一,从头节点开始查找 Node<E> x = first;//新建x指向first节点 for (int i = 0; i < index; i++)//找到原链表中下标为index的节点 x = x.next; return x;//返回原链表中下标为index的节点 } else {//下标在后半部分,从尾节点开始查找 Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
set
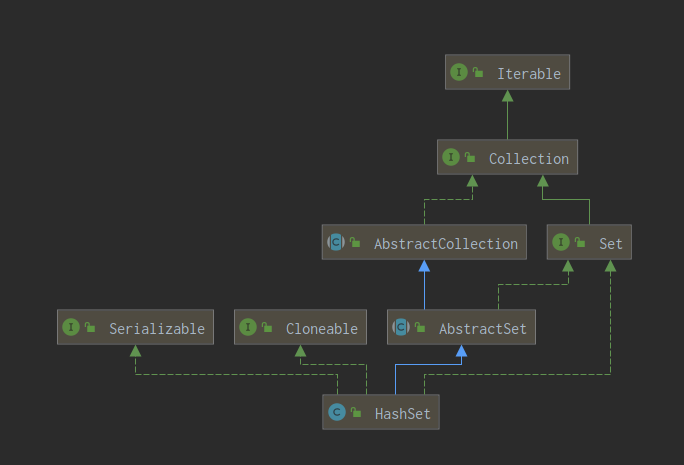
HashSet
变量以及参数
private transient HashMap<E,Object> map; // Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object();- 1
- 2
- 3
- 4
- 5
构造方法
/** * Constructs a new, empty set; the backing HashMap instance has * default initial capacity (16) and load factor (0.75). */ public HashSet() { map = new HashMap<>(); } /** * Constructs a new set containing the elements in the specified * collection. The HashMap is created with default load factor * (0.75) and an initial capacity sufficient to contain the elements in * the specified collection. * * @param c the collection whose elements are to be placed into this set * @throws NullPointerException if the specified collection is null */ public HashSet(Collection<? extends E> c) { map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); } /** * Constructs a new, empty set; the backing HashMap instance has * the specified initial capacity and the specified load factor. * * @param initialCapacity the initial capacity of the hash map * @param loadFactor the load factor of the hash map * @throws IllegalArgumentException if the initial capacity is less * than zero, or if the load factor is nonpositive */ public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<>(initialCapacity, loadFactor); } /** * Constructs a new, empty set; the backing HashMap instance has * the specified initial capacity and default load factor (0.75). * * @param initialCapacity the initial capacity of the hash table * @throws IllegalArgumentException if the initial capacity is less * than zero */ public HashSet(int initialCapacity) { map = new HashMap<>(initialCapacity); } /** * Constructs a new, empty linked hash set. (This package private * constructor is only used by LinkedHashSet.) The backing * HashMap instance is a LinkedHashMap with the specified initial * capacity and the specified load factor. * * @param initialCapacity the initial capacity of the hash map * @param loadFactor the load factor of the hash map * @param dummy ignored (distinguishes this * constructor from other int, float constructor.) * @throws IllegalArgumentException if the initial capacity is less * than zero, or if the load factor is nonpositive */ HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
add方法
/** * Adds the specified element to this set if it is not already present. * More formally, adds the specified element e to this set if * this set contains no element e2 such that * (e==null ? e2==null : e.equals(e2)). * If this set already contains the element, the call leaves the set * unchanged and returns false. * @param e element to be added to this set * @return true if this set did not already contain the specified * element */ public boolean add(E e) { return map.put(e, PRESENT)==null; } public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; // 关键代码 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { ... } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
* 如果指定的元素不存在,则将其添加到此集合 * 更正式一些,如果满足以下条件,则将指定的元素e添加到此集合。 * e == null ? e2 == null : e.equals(e2) * 如果集合set包含该元素,返回false- 1
- 2
- 3
- 4
contains方法
/** * Returns true if this set contains the specified element. * More formally, returns true if and only if this set * contains an element e such that * (o==null ? e==null : o.equals(e)). * * @param o element whose presence in this set is to be tested * @return true if this set contains the specified element */ public boolean contains(Object o) { return map.containsKey(o); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
去重原理
1.Java中HashSet是用散列表实现的,散列表的大小默认为16,加载因子为0.75.
2.去重原理:当hashset add一个元素A的时候,首先获取这个元素的散列码(hashcode的方法),即获取元素的哈希值。
情况一:如果计算出的元素的存储位置目前没有任何元素存储,那么该元素可以直接存储在该位置上。
情况二:如果算出该元素的存储位置目前已经存在有其他元素了,那么会调用该元素的equals方法与该位置的元素再比较一次,如果equals返回的值是true,那么该元素与这个位置上的元素就视为重复元素,不允许添加,如果equals方法返回的是false,那么该元素运行添加。
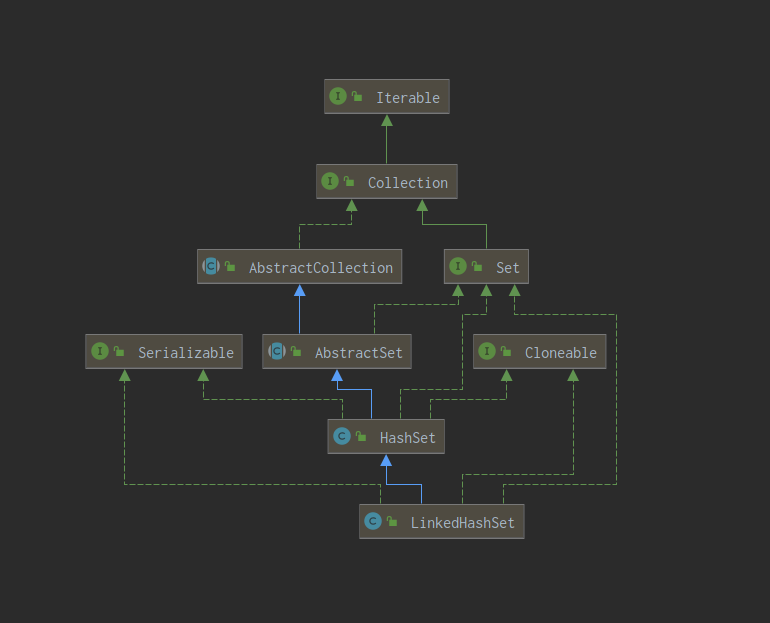
linkedhashset
/** * Constructs a new, empty linked hash set with the specified initial * capacity and load factor. * * @param initialCapacity the initial capacity of the linked hash set * @param loadFactor the load factor of the linked hash set * @throws IllegalArgumentException if the initial capacity is less * than zero, or if the load factor is nonpositive */ public LinkedHashSet(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor, true); } /** * Constructs a new, empty linked hash set with the specified initial * capacity and the default load factor (0.75). * * @param initialCapacity the initial capacity of the LinkedHashSet * @throws IllegalArgumentException if the initial capacity is less * than zero */ public LinkedHashSet(int initialCapacity) { super(initialCapacity, .75f, true); } /** * Constructs a new, empty linked hash set with the default initial * capacity (16) and load factor (0.75). */ public LinkedHashSet() { super(16, .75f, true); } /** * Constructs a new linked hash set with the same elements as the * specified collection. The linked hash set is created with an initial * capacity sufficient to hold the elements in the specified collection * and the default load factor (0.75). * * @param c the collection whose elements are to be placed into * this set * @throws NullPointerException if the specified collection is null */ public LinkedHashSet(Collection<? extends E> c) { super(Math.max(2*c.size(), 11), .75f, true); addAll(c); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
map
HashMap
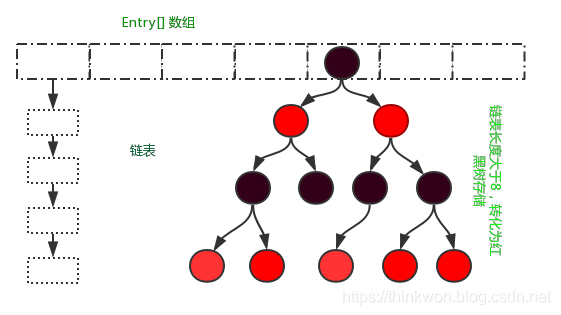
定位hash桶数组索引位置
&运算:按位与"&"功能是参与运算的两数各对应的二进位相与。只有对应的两个二进位均为1时,结果位才为1 ,否则为0
^运算:异或运算法则 如果a、b两个值不相同,则异或结果为1。如果a、b两个值相同,异或结果为0
初始化容量
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. * 将指定的值与映射中的指定键关联。如果映射之前包含一个键的映射,旧的值被替换。 * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with key, or * null if there was no mapping for key. * (A null return can also indicate that the map * previously associated null with key.) */ public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } // hashCode() native修饰的底层c函数,最后返回hash值是hashcode与16高低异或操作 static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } /** * Implements Map.put and related methods * * @param hash hash for key * @param key the key * @param value the value to put * @param onlyIfAbsent if true, don't change existing value * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // 初始化hash桶,table数组是延迟加载插入数据之后再进行初始化 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; ...省略 afterNodeInsertion(evict); return null; } /** * Initializes or doubles table size. If null, allocates in * accord with initial capacity target held in field threshold. * Otherwise, because we are using power-of-two expansion, the * elements from each bin must either stay at same index, or move * with a power of two offset in the new table. * * @return the table */ final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; // cap是capacity缩写,表示容量,如果容量不为空,说明已经开始初始化 if (oldCap > 0) { // 如果容量达到最大 1<<30则不再扩容 if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } // 按照旧容量和阈值的2倍计算新容量和阈值 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults // 这一部分,源代码也有注释 初始阈值为零表示使用默认值 // 调用无参构造,数组table默认容量1<<4,左移4位16 1 * 2^4 newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; ...省略 return newTab; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
初始化过程

public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }- 1
- 2
- 3
putVal()方法
/** * The bin count threshold for using a tree rather than list for a * bin. Bins are converted to trees when adding an element to a * bin with at least this many nodes. The value must be greater * than 2 and should be at least 8 to mesh with assumptions in * tree removal about conversion back to plain bins upon * shrinkage. */ static final int TREEIFY_THRESHOLD = 8; final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //判断数组是否未初始化 if ((tab = table) == null || (n = tab.length) == 0) //如果未初始化,调用resize方法 进行初始化 n = (tab = resize()).length; //通过 & 运算求出该数据(key)的数组下标并判断该下标位置是否有数据 if ((p = tab[i = (n - 1) & hash]) == null) //如果没有,直接将数据放在该下标位置 tab[i] = newNode(hash, key, value, null); //该数组下标有数据的情况 else { Node<K,V> e; K k; //判断该位置数据的key和新来的数据是否一样 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) //如果一样,证明为修改操作,该节点的数据赋值给e,后边会用到 e = p; //判断是不是红黑树 else if (p instanceof TreeNode) //如果是红黑树的话,进行红黑树的操作 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //新数据和当前数组既不相同,也不是红黑树节点,证明是链表 else { //遍历链表 for (int binCount = 0; ; ++binCount) { //判断next节点,如果为空的话,证明遍历到链表尾部了 if ((e = p.next) == null) { //把新值放入链表尾部 p.next = newNode(hash, key, value, null); //因为新插入了一条数据,所以判断链表长度是不是大于等于8 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //如果是,进行转换红黑树操作 treeifyBin(tab, hash); break; } //判断链表当中有数据相同的值,如果一样,证明为修改操作 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; //把下一个节点赋值为当前节点 p = e; } } //判断e是否为空(e值为修改操作存放原数据的变量) if (e != null) { // existing mapping for key //不为空的话证明是修改操作,取出老值 V oldValue = e.value; //一定会执行 onlyIfAbsent传进来的是false if (!onlyIfAbsent || oldValue == null) //将新值赋值当前节点 e.value = value; afterNodeAccess(e); //返回老值 return oldValue; } } //计数器,计算当前节点的修改次数 ++modCount; //当前数组中的数据数量如果大于扩容阈值 if (++size > threshold) //进行扩容操作 resize(); //空方法 afterNodeInsertion(evict); //添加操作时 返回空值 return null; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
获取元素
(1)、先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。 (2)、在通过数组下标快速定位到某个位置上。重点理解如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表,那么它就会拿着参数K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; //判断数组不为null并且长度大于0,并且通过hash算出来的数组下标的位置不为空,证明有数据 if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { //判断数组的位置的key的hash和内容是否等同与要查询的数据 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) //相等的话直接返回 return first; //判断是否有下个节点 if ((e = first.next) != null) { //判断是否为为红黑树 if (first instanceof TreeNode) //进行红黑树查询操作 return ((TreeNode<K,V>)first).getTreeNode(hash, key); //链表查询操作 do { //循环链表,逐一判断 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) //发现key的话就返回 return e; } while ((e = e.next) != null); } } //没有查询到返回null return null; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
扩容
向HashMap中添加数据时,有三个条件会触发它的扩容行为:
-
如果数组为空,则进行首次扩容。
-
将元素接入链表后,如果链表长度达到8,并且数组长度小于64,则扩容。
-
添加后,如果数组中元素超过阈值,即比例超出限制(默认为0.75),则扩容。
-
每次扩容时都是将容量翻倍,即创建一个2倍大的新数组,然后再将旧数组中的数组迁移到新数组里。由于HashMap中数组的容量为2^N,所以可以用位移运算计算新容量,效率很高。
5. 在数据迁移时,为了兼顾性能,不会重新计算一遍每个key的哈希值,而是根据位移运算后(左移翻倍)多出来的最高位来决定,如果高位为0则元素位置不变,如果高位为1则元素的位置是在原位置基础上加上旧的容量。
举个例子,来演示一下数据迁移时,元素在新数组里位置的判定。假设旧数组长度为16(00010000),则翻倍后新数组的长度为32(00100000)。我们从十进制数字上看不出什么,但是从二进制数字却可以看出二者的明显差别,即翻倍后新值的高位多了1。
如果我们把这两个值作为掩码,对key的哈希值做按位与运算,就能求出最高位那一位的差异。如果这一位是0则该元素的位置不变,否则该元素的位置就在原位置基础上加16。这个方式很巧妙,它省略了重新计算哈希值的时间,同时新增出来的一位是0或1是随机的,这样就把产生冲突的节点均匀的分散到新的槽里了。
//扩容、初始化数组 final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; //如果当前数组为null的时候,把oldCap老数组容量设置为0 int oldCap = (oldTab == null) ? 0 : oldTab.length; //老的扩容阈值 int oldThr = threshold; int newCap, newThr = 0; //判断数组容量是否大于0,大于0说明数组已经初始化 if (oldCap > 0) { //判断当前数组长度是否大于最大数组长度 if (oldCap >= MAXIMUM_CAPACITY) { //如果是,将扩容阈值直接设置为int类型的最大数值并直接返回 threshold = Integer.MAX_VALUE; return oldTab; } //如果在最大长度范围内,则需要扩容 OldCap << 1等价于oldCap*2 //运算过后判断是不是最大值并且oldCap需要大于16 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold 等价于oldThr*2 } //如果oldCap<0,但是已经初始化了,像把元素删除完之后的情况,那么它的临界值肯定还存在, 如果是首次初始化,它的临界值则为0 else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; //数组未初始化的情况,将阈值和扩容因子都设置为默认值 else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } //初始化容量小于16的时候,扩容阈值是没有赋值的 if (newThr == 0) { //创建阈值 float ft = (float)newCap * loadFactor; //判断新容量和新阈值是否大于最大容量 newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } //计算出来的阈值赋值 threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) //根据上边计算得出的容量 创建新的数组 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //赋值 table = newTab; //扩容操作,判断不为空证明不是初始化数组 if (oldTab != null) { //遍历数组 for (int j = 0; j < oldCap; ++j) { Node<K,V> e; //判断当前下标为j的数组如果不为空的话赋值个e,进行下一步操作 if ((e = oldTab[j]) != null) { //将数组位置置空 oldTab[j] = null; //判断是否有下个节点 if (e.next == null) //如果没有,就重新计算在新数组中的下标并放进去 newTab[e.hash & (newCap - 1)] = e; //有下个节点的情况,并且判断是否已经树化 else if (e instanceof TreeNode) //进行红黑树的操作 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); //有下个节点的情况,并且没有树化(链表形式) else { //比如老数组容量是16,那下标就为0-15 //扩容操作*2,容量就变为32,下标为0-31 //低位:0-15,高位16-31 //定义了四个变量 // 低位头 低位尾 Node<K,V> loHead = null, loTail = null; // 高位头 高位尾 Node<K,V> hiHead = null, hiTail = null; //下个节点 Node<K,V> next; //循环遍历 do { //取出next节点 next = e.next; //通过 与操作 计算得出结果为0 if ((e.hash & oldCap) == 0) { //如果低位尾为null,证明当前数组位置为空,没有任何数据 if (loTail == null) //将e值放入低位头 loHead = e; //低位尾不为null,证明已经有数据了 else //将数据放入next节点 loTail.next = e; //记录低位尾数据 loTail = e; } //通过 与操作 计算得出结果不为0 else { //如果高位尾为null,证明当前数组位置为空,没有任何数据 if (hiTail == null) //将e值放入高位头 hiHead = e; //高位尾不为null,证明已经有数据了 else //将数据放入next节点 hiTail.next = e; //记录高位尾数据 hiTail = e; } //如果e不为空,证明没有到链表尾部,继续执行循环 } while ((e = next) != null); //低位尾如果记录的有数据,是链表 if (loTail != null) { //将下一个元素置空 loTail.next = null; //将低位头放入新数组的原下标位置 newTab[j] = loHead; } //高位尾如果记录的有数据,是链表 if (hiTail != null) { //将下一个元素置空 hiTail.next = null; //将高位头放入新数组的(原下标+原数组容量)位置 newTab[j + oldCap] = hiHead; } } } } } //返回新的数组对象 return newTab; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
链表树化
将单向链表转化为红黑树。树化操作主要发生在put操作中。
当链表长度
超过8,且容量达到64时,触发树化for (int binCount = 0; ; ++binCount) { //这里是遍历到链表的最后一个 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); /** * 这里这个树化阈值的判断需要仔细琢磨一下 * 如果当前链表有八个节点,刚刚将newNode插入到了尾结点后面,也就是说 * 此时的newNode是链表中的第九个节点,此时才会进行树化 * 因为bitCount是从0开始的,也就是说bitCount为7的时候,才会树化,此时已经有了八个节点 * newNode再插进来,当然是第九个了 */ if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } /** * 在遍历的过程中,如果找到相同的key,就退出遍历,进行覆盖 * 但是不是在这里覆盖, 在下面判断中进行的覆盖 * 可以整体看下这里的逻辑,如果进入到下面的if判断中,那此时就会中断for循环,这时 e != null * 如果这里的if判断一直没有进去,那就会进入到上面 if((e = p.next) == null)的判断,也就是说,e == null */ if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } // 这是put方法中的部分代码,在当前插入的元素大于8个时,会进行树化 /** * 链表转换红黑树,进行树化的目的是将链表中节点的查询效率提高 * 1.需要满足两个条件:数组不为空且hashmap数组的长度超过64,否则,只会进行扩容,不会进行树化 * 如果数组长度不超过64,就可以进行扩容,因为扩容之后,链表的长度就会变为一半 * 2.e表示的是数组中某个链表对应的头结点 * 2.1 do while循环,会把链表中每个node节点进行转换,转换成treeNode,然后将链表变成了双向链表,有prev和next,hd表示的是原链表的第一个节点, * 2.2 然后根据hd进行真正的红黑树转换,hd就是红黑树初始化的根节点 * * 所以:链表转红黑树,首先会把当前的单向链表,转换成双向链表,然后再拿着双向链表的头结点hd去进行红黑树的转换 * * @param tab * @param hash:待插入元素key值对应的hash */ final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { /** * replacementTreeNode:把e这个node节点变为双向链表中的节点 treeNode * * e:是未转变红黑树之前链表的第一个节点 * hd:是e对应的treeNode * tl:是一个动态变量,永远表示的是最后一个节点 * * 所以下面的代码,是把原本的链表转换成了treeNode,我们姑且可以认为是双向链表 */ TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) /** * 这里的treeify是将双向链表转换为红黑树,这里只需要入参双向链表的头节点就可以了 */ hd.treeify(tab); } } // 在treeifyBin方法中,会先把当前链表中的元素替换成双向链表,然后从tab[0]位置,依次向红黑树中添加元素 /** * Forms tree of the nodes linked from this node. * 红黑树的根节点如果发生了变化,就需要把变化之后的根节点放到双向链表的head * 所以:我们可以认为:在树化之后,双向链表的头节点,就是红黑数的root节点,在每次向插入红黑树中插入数据之后,如果root节点发生了变化 * 同时会维护双向链表的节点 */ final void treeify(Node<K,V>[] tab) { TreeNode<K,V> root = null; /** * 这里会遍历前面维护好的的双向链表 */ for (TreeNode<K,V> x = this, next; x != null; x = next) { next = (TreeNode<K,V>)x.next; //首先将根节点的左右节点设置为null x.left = x.right = null; //把第一个hd,设置为root节点,默认是黑色的 if (root == null) { x.parent = null; x.red = false; root = x; } else { /** * 这里的x就是要插入到树中的元素 * 在每次插入到红黑树之前,是需要先判断当前要插入的节点是要插入到哪个位置? * 父节点是谁? */ K k = x.key; int h = x.hash; Class<?> kc = null; /** * 遍历树中已经存在的节点,从root节点开始 */ for (TreeNode<K,V> p = root;;) { int dir, ph; K pk = p.key; /** * 如果新结点的hash值小于树中已经存在的树节点,就是-1;如果新结点的hash值大于树中的结点对应的hash,就是1,意思就是,-1往左插入,1往右插入 * 所以,判断当前节点是要插入到节点的左边还是右边,就是根据这里来判断的 * 如果root节点大于要插入的节点,那就是往左边插入,反之,向右边插入 * * 所以:这里在判断dir的值时,有以下几个逻辑 * 1.先判断key的hash值,如果hash值相等,就进行下一步判断 * 2.再判断key是否实现了Comparable接口,如果实现了,就通过compareTo * 去比较,如果比较的值还是相等,就执行下一步 * 3.调用tieBreakOrder * 先判断k和pk对应的className是否一样 * 然后再判断identityHashCode对应的值 * * 这里为什么要先判断hashCode,hashCode相等之后,在最后再调用System.identityHashCode() * 是为了防止程序员自己重写hashCode方法,返回了固定值,比如:为重修额hashCode * ,返回了1,那就区分不出来哪个key大 哪个key小了 */ if ((ph = p.hash) > h) dir = -1; else if (ph < h) dir = 1; else if ((kc == null && (kc = comparableClassFor(k)) == null) || (dir = compareComparables(kc, k, pk)) == 0) dir = tieBreakOrder(k, pk); TreeNode<K,V> xp = p; /** * 这里是,根据上面的dir来进行遍历判断,for循环,一直找到最底层的孙子结点,判断条件就是p.left或者p.right为null, * 就表示当前的p结点是最左边或者最右边的了 如果dir <= 0,就往左,否则 往右 * */ if ((p = (dir <= 0) ? p.left : p.right) == null) { x.parent = xp; if (dir <= 0) xp.left = x; else xp.right = x; /** * 我们可以理解为上面的逻辑就是为了找到当前要插入的x节点对应的parent * * 这是把x节点插入到红黑树中,并返回插入之后的root节点,因为有可能在插入X * 节点之后,红黑树进行了平衡或者红黑颜色的转换,导致root节点变化 * 所以:这个方法就是把x插入到root节点,并进行平衡或者红黑转换的过程,最后会返回转换之后的root节点 */ root = balanceInsertion(root, x); break; } } } } /** * 下面这个方法中完成的操作: * 1.把红黑树的根节点移到tab[i] * 2.把root节点移到双向链表的第一个元素位置 * 这里是把跟结点移到tab[i]上,因为在红黑树转换的过程中,root结点是可能发生转换的 * 同时,把root结点对应的treeNode变成双线链表的头结点head,因为红黑树的root结点,很有可能是双向链表中的某个节点;要保证root的根节点对应的双线链表的头结点 * */ moveRootToFront(tab, root); } // 这个方法,我们可以简单认为,就做了两件事情 // 1、将当前要插入的节点,写入到红黑树中,就是最后一行前面的代码所做的事情 // 2、将当前最新的root节点,移动到双向链表的头部,就是最后一行代码做的事情 /** * Ensures that the given root is the first node of its bin. * 这个方法是把入参中的root节点,变为当前双向链表的root节点(头节点) */ static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) { int n; if (root != null && tab != null && (n = tab.length) > 0) { int index = (n - 1) & root.hash; TreeNode<K,V> first = (TreeNode<K,V>)tab[index]; /** * 如果root节点和tab[i]位置的元素不一样,就进行转换 * * 这里有一个点没看懂:tab数组是当前hashmap的数组,为什么是从当前数组中 * 找到一个位置i对应的头结点? */ if (root != first) { Node<K,V> rn; // 将root节点赋值到tab[i]位置 tab[index] = root; //rp是root节点的上一个节点(有可能进行转换之后,root节点在双向链表中间某个位置) TreeNode<K,V> rp = root.prev; //如果root节点不是最后一个节点,就把root下一个节点的prev指向root的前一个节点 if ((rn = root.next) != null) ((TreeNode<K,V>)rn).prev = rp; //如果root的上一个节点不为null,就把上一个节点的next指向root的下一个节点 if (rp != null) rp.next = rn; //将现在tab[i]对应的元素设置为root的下一个节点,也就是把root节点放到first的前面 if (first != null) first.prev = root; root.next = first; root.prev = null; } assert checkInvariants(root); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
线程安全问题
https://mp.weixin.qq.com/s?__biz=MzIxMjE5MTE1Nw==&mid=2653192000&idx=1&sn=118cee6d1c67e7b8e4f762af3e61643e&chksm=8c990d9abbee848c739aeaf25893ae4382eca90642f65fc9b8eb76d58d6e7adebe65da03f80d&scene=21#wechat_redirect
ConcurrentHashMap
https://blog.csdn.net/wwj17647590781/article/details/118151008?spm=1001.2014.3001.5501
构造器
不同种类的构造器
/** * Creates a new, empty map with the default initial table size (16). * 通过无参构造方法创建map,初始化容量为16 */ public ConcurrentHashMap() { } /** * Creates a new, empty map with an initial table size * accommodating the specified number of elements without the need * to dynamically resize. * 指定初始容量的map,将指定的容量按照一定算法获取2的整数次幂 * @param initialCapacity The implementation performs internal * sizing to accommodate this many elements. * @throws IllegalArgumentException if the initial capacity of * elements is negative */ public ConcurrentHashMap(int initialCapacity) { if (initialCapacity < 0) throw new IllegalArgumentException(); int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1)); this.sizeCtl = cap; } /** * Copies all of the mappings from the specified map to this one. * These mappings replace any mappings that this map had for any of the * keys currently in the specified map. * 根据指定map创建chm * @param m mappings to be stored in this map */ public void putAll(Map<? extends K, ? extends V> m) { tryPresize(m.size()); for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) putVal(e.getKey(), e.getValue(), false); } /** * Creates a new, empty map with an initial table size based on * the given number of elements ({@code initialCapacity}) and * initial table density ({@code loadFactor}). * * @param initialCapacity the initial capacity. The implementation * performs internal sizing to accommodate this many elements, * given the specified load factor. * @param loadFactor the load factor (table density) for * establishing the initial table size * @throws IllegalArgumentException if the initial capacity of * elements is negative or the load factor is nonpositive * 指定table初始容量和负载因子的构造器 * @since 1.6 */ public ConcurrentHashMap(int initialCapacity, float loadFactor) { this(initialCapacity, loadFactor, 1); } /** * Creates a new, empty map with an initial table size based on * the given number of elements ({@code initialCapacity}), table * density ({@code loadFactor}), and number of concurrently * updating threads ({@code concurrencyLevel}). * 指定table初始容量、负载因子、并发级别的构造器 * @param initialCapacity the initial capacity. The implementation * performs internal sizing to accommodate this many elements, * given the specified load factor. * @param loadFactor the load factor (table density) for * establishing the initial table size * @param concurrencyLevel the estimated number of concurrently * updating threads. The implementation may use this value as * a sizing hint. * @throws IllegalArgumentException if the initial capacity is * negative or the load factor or concurrencyLevel are * nonpositive */ public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); if (initialCapacity < concurrencyLevel) // Use at least as many bins initialCapacity = concurrencyLevel; // as estimated threads long size = (long)(1.0 + (long)initialCapacity / loadFactor); int cap = (size >= (long)MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)size); this.sizeCtl = cap; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
常量
//最大容量. private static final int MAXIMUM_CAPACITY = 1 << 30; //默认初始容量 private static final int DEFAULT_CAPACITY = 16; static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; //负载因子,为了兼容JDK1.8以前的版本而保留,JDK1.8中的ConcurrentHashMap的负载因子恒定为0.75 private static final float LOAD_FACTOR = 0.75f; //链表--->树的阈值:即链接结点数大于8时, 链表转换为树. static final int TREEIFY_THRESHOLD = 8; //树--->链表的阈值:即树结点树小于6时,树转换为链表. static final int UNTREEIFY_THRESHOLD = 6; /** * 在链表--->树之前,还会有一次判断: * 即只有键值对数量大于MIN_TREEIFY_CAPACITY,才会发生转换。 * 这是为了避免在Table建立初期,多个键值对恰好被放入了同一个链表中而导致不必要的转化。 */ static final int MIN_TREEIFY_CAPACITY = 64; /** * 在树--->链表之前,还会有一次判断: * 即只有键值对数量小于MIN_TRANSFER_STRIDE,才会发生转换. */ private static final int MIN_TRANSFER_STRIDE = 16; //用于在扩容时生成唯一的随机数. private static int RESIZE_STAMP_BITS = 16; //可同时进行扩容操作的最大线程数. private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1; /** * The bit shift for recording size stamp in sizeCtl. */ private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; /* * hash值的意义 */ static final int MOVED = -1; // 标识ForwardingNode结点(在扩容时才会出现,不存储实际数据) static final int TREEBIN = -2; // 标识红黑树的根结点 static final int RESERVED = -3; // 标识ReservationNode结点() static final int HASH_BITS = 0x7fffffff; // 标识Node结点,自然数0,1,2... //CPU核心数,扩容时使用 static final int NCPU = Runtime.getRuntime().availableProcessors();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
字段
//Node数组,标识整个Map,首次插入元素时创建,大小总是2的幂次. transient volatile Node<K, V>[] table; //扩容后的新Node数组,只有在扩容时才非空. private transient volatile Node<K, V>[] nextTable; /** * sizeCtl:控制table的初始化和扩容.很重要💦💦💦💦 * 0 : 初始默认值 * -1 : 有线程正在进行table的初始化 * >0 : table初始化时使用的容量,或初始化/扩容完成后的阈值threshold * -(1 + nThreads) : 记录正在执行扩容任务的线程数 */ private transient volatile int sizeCtl; //扩容时需要用到的一个下标变量. private transient volatile int transferIndex; //计数基值,当没有线程竞争时,计数将直接加到该变量上。类似于LongAdder的base变量 private transient volatile long baseCount; //计数数组,出现并发冲突时使用,这时候计数不能直接加到baseCount变量上,类似于LongAdder的cells数组 private transient volatile CounterCell[] counterCells; // 自旋标识位,用于CounterCell[]扩容时使用。类似于LongAdder的cellsBusy变量 private transient volatile int cellsBusy; // 视图相关字段 private transient KeySetView<K, V> keySet; private transient ValuesView<K, V> values; private transient EntrySetView<K, V> entrySet;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
put方法源码分析
/** * Maps the specified key to the specified value in this table. * Neither the key nor the value can be null. * 指定key,value,并且key,value都不能为null *The value can be retrieved by calling the {@code get} method * with a key that is equal to the original key. * 可以通过调用该方法检索键值对 * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with {@code key}, or * {@code null} if there was no mapping for {@code key} * @throws NullPointerException if the specified key or value is null */
public V put(K key, V value) { return putVal(key, value, false); } /** * @Description 实际的插入操作 * @param key 表示键值对=》键 * @param value 表示键值对=》值 * @param onlyIfAbsent true=>表示key不存在才进行插入操作 * **/ final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); // 使用链表保存时,binCount记录table[i]这个桶中所保存的结点数 // 使用红黑树保存时,binCount==2,保证put后更改计数值时能够进行扩容检查,同时不触发红黑树化操作 int binCount = 0; // 死循环进行插入 for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; // 首次初始化 if (tab == null || (n = tab.length) == 0) tab = initTable(); // table[i]对应的桶为null,则直接插入结点 // tabAt(tab, i)方法是调用Unsafe类的方法查看值,保证每次获取到的值都是最新的 // table[i]的索引i的计算方式 (n - 1) & hash) 为什么这样计算 // 这是因为当table.length为2的幂次时,(table.length-1) 的二进制形式的特点是除最高位外全部是1,配合这种索引计算方式可以实现key在table中 // 的均匀分布 ,减少hash冲突——出现hash冲突时,结点就需要以链表或红黑树的形式链接到table[i],这样无论是插入还是查找都需要额外的时间 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) // 插入一个链表结点,成功返回 break; // no lock when adding to empty bin } // 发现ForwardingNode结点(通过MOVED标识ForwardingNode结点存在),说明此时table正在扩容,则尝试协助数据迁移 else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); // 出现hash冲突,也就是table[i]桶中已经有了结点 else { V oldVal = null; // 对table[i]结点上锁,避免并发情况 synchronized (f) { // 再判断一下节点 是不是在这个 table[i]上 if (tabAt(tab, i) == f) { // fh >= 0--->table[i]是链表结点 if (fh >= 0) { // 记录结点数,超过阈值后,需要转为红黑树,提高查找效率 binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; // 找到“相等”的结点,判断是否需要更新value值(onlyIfAbsent为false则可以插入) if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { // 记录key冲突的原来对应的value值 oldVal = e.val; // onlyIfAbsent标志仅当不存在时才插入 if (!onlyIfAbsent) e.val = value; break; } // 如果没有找到,则直接插在尾部即可 Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } // 继续判断table[i]是不是红黑树结点 else if (f instanceof TreeBin) { Node<K,V> p; // 红黑树对应的基值,包括了treebin和root,所以以2为基础 binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { // 超过阈值,链表 -> 红黑树 转换 if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } // 表明本次操作增加了新值, 计数值加1 addCount(1L, binCount); return null; } /** * @Description 计算hash值的方法,防止并发情况 **/ static final int spread(int h) { return (h ^ (h >>> 16)) & HASH_BITS; } /** * Initializes table, using the size recorded in sizeCtl. * 初始化table, 使用sizeCtl作为初始化容量. */ private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; // transient volatile Node- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
扩容机制
linkedhashmap
https://blog.csdn.net/qq_40050586/article/details/105851970
概述
LinkedHashMap和HashMap的存储结构基本相同,都是数组加链表。唯一不同的是,链表结点有两个指针,分别是before和after,指向该结点的直接后继和直接前驱,再通过双向链表表头结点,就可以实现从双向链表中的任意一个结点开始,很方便地访问它的前驱结点和后继结点。LinkedHashMap采用的hash算法和HashMap相同,但它扩展了Entry(结点,用于存储key和value)。LinkedHashMap中的Entry增加了 before 和 after两个指针,用于维护双向链表。

构造函数
/** * Constructs an empty insertion-ordered LinkedHashMap instance * with the specified initial capacity and load factor. * * @param initialCapacity the initial capacity * @param loadFactor the load factor * @throws IllegalArgumentException if the initial capacity is negative * or the load factor is nonpositive */ public LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); accessOrder = false; } /** * 构造一个空的,按插入序(accessOrder = false)的LinkedHashMap,使用默认初始大小和负载因子0.75 * * @param initialCapacity the initial capacity * @throws IllegalArgumentException if the initial capacity is negative */ public LinkedHashMap(int initialCapacity) { super(initialCapacity); accessOrder = false; } /** * 默认构造函数也是关闭了get改变顺序,使用插入序。 */ public LinkedHashMap() { super(); accessOrder = false; } /** * Constructs an insertion-ordered LinkedHashMap instance with * the same mappings as the specified map. The LinkedHashMap * instance is created with a default load factor (0.75) and an initial * capacity sufficient to hold the mappings in the specified map. * * @param m the map whose mappings are to be placed in this map * @throws NullPointerException if the specified map is null */ public LinkedHashMap(Map<? extends K, ? extends V> m) { super(); accessOrder = false; putMapEntries(m, false); } /** * 这个构造方法指定了accessOrder * * @param initialCapacity the initial capacity * @param loadFactor the load factor * @param accessOrder the ordering mode - true for * access-order, false for insertion-order * @throws IllegalArgumentException if the initial capacity is negative * or the load factor is nonpositive */ public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
维护链表关键
afterNodeRemoval,afterNodeInsertion,afterNodeAccess。这三个方法的主要作用是,在删除,插入,获取节点之后,对链表进行维护。简单来说,这三个方法中执行双向链表的操作
//在节点删除后,维护链表,传入删除的节点 void afterNodeRemoval(Node<K,V> e) { // unlink //p指向待删除元素,b执行前驱,a执行后驱 LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; //这里执行双向链表删除p节点操作,很简单。 p.before = p.after = null; if (b == null) head = a; else b.after = a; if (a == null) tail = b; else a.before = b; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
//在节点被访问后根据accessOrder判断是否需要调整链表顺序 void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last; //如果accessOrder为false,什么都不做 if (accessOrder && (last = tail) != e) { //p指向待删除元素,b执行前驱,a执行后驱 LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; //这里执行双向链表删除操作 p.after = null; if (b == null) head = a; else b.after = a; if (a != null) a.before = b; else last = b; //这里执行将p放到尾部 if (last == null) head = p; else { p.before = last; last.after = p; } tail = p; //保证并发读安全。 ++modCount; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
void afterNodeInsertion(boolean evict) { // possibly remove eldest LinkedHashMap.Entry<K,V> first; //removeEldestEntry(first)默认返回false,所以afterNodeInsertion这个方法其实并不会执行 if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null, false, true); } } protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
为什么不执行也可以呢,这个要到put操作的时候就能看出来了。
那么removeEldestEntry这个方法有什么用呢,看名字可以知道是删除最久远的节点,也就是head节点,这个方法实际是给我们自己扩展的。默认是没有用的,接下来实现LRU的代码中将可以看到它的作用。
put源码分析
LinkedHashMap没有重写HashMap的put方法,所以执行put操作的时候,还是使用的是HashMap的put方法。那么这样如何保证链表的逻辑呢?原因就是HashMap的putVal方法中实际调用了维护链表的方法,下面是关键代码:HashMap的putVal()方法
//默认的传入的evict是true final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { ................ ................ ................ ................ if (e != null) { // existing mapping for key //如果e不为null,此时的e指向的就是在map中的那个插入点,所以这个时候来赋值。 V oldValue = e.value; // onlyIfAbsent入口参数,为true,则不更新value(前面已说明)。 //这个地方的主要作用主要控制如果map中已经有那个key了,是否需要需要更新值 if (!onlyIfAbsent || oldValue == null) e.value = value; //这里其实是插入成功后执行的,获得的效果就是将e放到了链表结尾。 //所以afterNodeInsertion方法就算什么都不做也可以。 //但是如果accessOrder为false,那么我们新插入的节点,都不会进入链表了 afterNodeAccess(e); return oldValue; } } //fast-fail机制的实现,为了保证并发读安全。 ++modCount; //容器中的键值对数自增,如果大于了阈值,开始扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
在put方法中,HashMap会在合适的位置使用 afterNodeAccess(e),和afterNodeInsertion(evict);方法。因为在HashMap中也定义了这三个函数,但是都是为空函数,在LInkedHashMap中只是重写了这3个方法。我们在使用map.put(key,value)的时候,实际调用HashMap#putVal(key,value)方法,然后再调用afterNodeAccess方法,那么这个时候调用的会是子类的afterNodeAccess方法吗?
这个就要涉及到多态的知识了,可以从虚拟机方面去解释:在虚拟机加载类的解析过程中,对方法调用有两种分派方式,静态分派对应重载,动态分派对应重写。这里对应的就是动态分派。动态分配是在运行时发生的,它对于方法是按照实际类型来首先寻找的。找不到再往父类走。这里的实际类型其实值new 后面跟着的类。所以这里不用担心会调用到父类的方法。
afterNodeInsertion方法不是没有用,而是留给扩展用的,下面会展示。
还有一点,put操作中使用afterNodeAccess来将新插入的节点放到尾部。但是这个方法要受到accessOrder的控制,如果accessOrder为false(默认就为false)那么新插入的节点应该就不能插入到链表中了。这样设计有什么特殊的意义吗?
get源码分析
LinkedHashMap重写了HashMap的get方法,如下:
/** * 调用hashmap的getNode方法获取到值之后,维护链表 * @param key * @return */ public V get(Object key) { Node<K,V> e; if ((e = getNode(hash(key), key)) == null) return null; if (accessOrder) afterNodeAccess(e); return e.value; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
remove源码分析
final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; //判断table是否为空,该key对应的桶是否为空 if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; else if ((e = p.next) != null) { if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } //到这里了其实node就已经指向了要删除的节点了 //matchValue的作用是指现在是否需要值匹配。因为可能没有传入value,所以判断一下 if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p) tab[index] = node.next; else p.next = node.next; ++modCount; --size; //调用维护链表的操作 afterNodeRemoval(node); return node; } } return null; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
实现LRU算法缓存
LRU,即最近最少使用。LRU中保存的数据如果满了,那么就会将最近最少使用的数据删除。
LinkedHashMap通过使accessOrder为true,可以满足这种特性。
class LRUCache extends LinkedHashMap { private int capacity; public LRUCache(int capacity) { //accessOrder为true super(capacity, 0.75F, true); this.capacity = capacity; } public int get(int key) { return (int)super.getOrDefault(key, -1); } public void put(int key, int value) { super.put(key, value); } protected boolean removeEldestEntry(Map.Entry eldest) { return size() > capacity; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
这里重写了removeEldestEntry方法,然后removeEldestEntry方法在afterNodeInsertion中被调用,如果这个方法返回真,那么就会删除head指向的节点。根据每次get的节点都会放到尾部的特性,所以head指向的节点就是最久没有使用到的节点,所以可以删除。由于我们每次put完(HashMap#putVal())都会调用这个afterNodeInsertion方法,所以可以上面的设计可以使put过后如果size超了,将删除最久没有使用的一个节点,从而腾出空间给新的节点。
总结
一句话总结,LinkedHashMap就是HashMap中将其node维护成了一个双向链表。只要搞懂了HashMap就可以很容易搞懂LinkedHashMap。
TreeMap

概念理解
TreeMap集合是基于红黑树(Red-Black tree)的NavigableMap实现。该集合最重要的特点就是可排序,该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的Comparator进行排序,具体取决于使用的构造方法。这句话是什么意思呢?就是说TreeMap可以对添加进来的元素进行排序,可以按照默认的排序方式,也可以自己创建排序器放入构造方法指定排序方式。根据上一条,我们要想使用
TreeMap存储并排序我们自定义的类(如User类),那么必须自己定义比较机制:一种方式是User类去实现java.lang.Comparable接口,并实现其compareTo()方法。另一种方式是写一个类(如MyCompatator)去实现java.util.Comparator接口,并实现compare()方法,然后将MyCompatator类实例对象作为TreeMap的构造方法参数进行传参(当然也可以使用匿名内部类)类名及类成员变量
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable { // 比较器对象 private final Comparator<? super K> comparator; // 根节点 private transient Entry<K,V> root; // 集合大小 private transient int size = 0; // 树结构被修改的次数 private transient int modCount = 0; // 静态内部类用来表示节点类型 static final class Entry<K,V> implements Map.Entry<K,V> { K key; // 键 V value; // 值 Entry<K,V> left; // 指向左子树的引用(指针) Entry<K,V> right; // 指向右子树的引用(指针) Entry<K,V> parent; // 指向父节点的引用(指针) boolean color = BLACK; // } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
构造方法
public TreeMap() { // 1,无参构造方法 comparator = null; // 默认比较机制 } public TreeMap(Comparator comparator) { // 2,自定义比较器的构造方法 this.comparator = comparator; } public TreeMap(Map m) { // 3,构造已知Map对象为TreeMap comparator = null; // 默认比较机制 putAll(m); } public TreeMap(SortedMap- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
put方法
public V put(K key, V value) { Entry<K,V> t = root; // 获取根节点 // 如果根节点为空,则该元素置为根节点 if (t == null) { compare(key, key); // type (and possibly null) check root = new Entry<>(key, value, null); size = 1; // 集合大小为1 modCount++; // 结构修改次数自增 return null; } int cmp; Entry<K,V> parent; Comparator<? super K> cpr = comparator; // 比较器对象 // 如果比较器对象不为空,也就是自定义了比较器 if (cpr != null) { do { // 循环比较并确定元素应插入的位置(也就是找到该元素的父节点) parent = t; // t就是root // 调用比较器对象的compare()方法,该方法返回一个整数 cmp = cpr.compare(key, t.key); if (cmp < 0) // 待插入元素的key"小于"当前位置元素的key,则查询左子树 t = t.left; else if (cmp > 0) // 待插入元素的key"大于"当前位置元素的key,则查询右子树 t = t.right; else // "相等"则替换其value。 return t.setValue(value); } while (t != null); } // 如果比较器对象为空,使用默认的比较机制 else { if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key; // 取出比较器对象 do { // 同样是循环比较并确定元素应插入的位置(也就是找到该元素的父节点) parent = t; cmp = k.compareTo(t.key); // 同样调用比较方法并返回一个整数 if (cmp < 0) // 待插入元素的key"小于"当前位置元素的key,则查询左子树 t = t.left; else if (cmp > 0) // 待插入元素的key"大于"当前位置元素的key,则查询右子树 t = t.right; else // "相等"则替换其value。 return t.setValue(value); } while (t != null); } Entry<K,V> e = new Entry<>(key, value, parent); // 根据key找到父节点后新建一个节点 if (cmp < 0) // 根据比较的结果来确定放在左子树还是右子树 parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; // 集合大小+1 modCount++; // 集合结构被修改次数+1 return null; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
getEntry,getFirstEntry,getLastEntry方法
final Entry<K,V> getEntry(Object key) { // 如果有自定义比较器对象,就按照自定义规则遍历二叉树 if (comparator != null) return getEntryUsingComparator(key); if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key; Entry<K,V> p = root; while (p != null) { // 按照默认比较规则遍历二叉树 int cmp = k.compareTo(p.key); if (cmp < 0) p = p.left; else if (cmp > 0) p = p.right; else return p; } return null; } final Entry<K,V> getFirstEntry() { // 获取第一个元素也就是最小的元素,一直遍历左子树 Entry<K,V> p = root; if (p != null) while (p.left != null) p = p.left; return p; } final Entry<K,V> getLastEntry() { // 获取最后个元素也就是最大的元素,一直遍历右子树 Entry<K,V> p = root; if (p != null) while (p.right != null) p = p.right; return p; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
排序方案
默认排序
/** * 验证有序集合 */ @Test public void checkSortCollection() { // 默认排序,通过Comparable接口中compareTo方法 log.info("默认排序,key是字符串类型"); TreeMap<String, Object> map = new TreeMap<>(); map.put("c", "v1"); map.put("b", "v3"); map.put("A", "v2"); map.forEach((i, j) -> log.info("map:key->[{}],value:[{}]", i, j)); log.info("默认排序,key是数值类型"); TreeMap<Integer, Object> intMap = new TreeMap<>(); intMap.put(11,"Three"); intMap.put(1,"One"); intMap.put(3,"Two"); intMap.forEach((k,v)->log.info("key:[{}],value:[{}]",k,v)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
16:05:32.535 [main] INFO com.geekmice.staging.staging.dao.EveryQuestionTest - 默认排序,key是字符串类型
16:05:32.600 [main] INFO com.geekmice.staging.staging.dao.EveryQuestionTest - map:key->[A],value:[v2]
16:05:32.602 [main] INFO com.geekmice.staging.staging.dao.EveryQuestionTest - map:key->[b],value:[v3]
16:05:32.602 [main] INFO com.geekmice.staging.staging.dao.EveryQuestionTest - map:key->[c],value:[v1]
16:05:32.602 [main] INFO com.geekmice.staging.staging.dao.EveryQuestionTest - 默认排序,key是数值类型
16:05:32.603 [main] INFO com.geekmice.staging.staging.dao.EveryQuestionTest - key:[1],value:[One]
16:05:32.603 [main] INFO com.geekmice.staging.staging.dao.EveryQuestionTest - key:[3],value:[Two]
16:05:32.603 [main] INFO com.geekmice.staging.staging.dao.EveryQuestionTest - key:[11],value:[Three]自定义排序
实现Comparable接口,重写compareTo()方法
@Data @AllArgsConstructor @NoArgsConstructor static class School implements Comparable<School> { private String schoolName; private String schoolAddr; private Integer num; /** * 实现Comparable接口在这里自定义排序规则 * 如果什么不写的话,默认返回return 0;只能存储第一个被put的元素 * 升序这个写法 * * @param o * @return */ @Override public int compareTo(School o) { if (num > o.getNum()) { return 1; } else if (num < o.getNum()) { return -1; } return 0; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
案例说明
/** * 验证有序集合 */ @Test public void checkSortCollection() { log.info("自定义排序之key实现Comparable接口"); TreeMap<School, Integer> customizeKeyMap = new TreeMap<>(); customizeKeyMap.put(new School(UUID.randomUUID().toString(),UUID.randomUUID().toString(),10),1); customizeKeyMap.put(new School(UUID.randomUUID().toString(),UUID.randomUUID().toString(),11),1); customizeKeyMap.put(new School(UUID.randomUUID().toString(),UUID.randomUUID().toString(),1),1); customizeKeyMap.forEach((k,v)->log.info("key:[{}],value:[{}]",k,v)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
创建排序器
static class MyComparator implements Comparator<School> { @Override public int compare(School o1, School o2) { if (o1.getNum() > o2.getNum()) { return 1; } else if (o1.getNum() < o2.getNum()) { return -1; } return 0; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
案例分析
/** * 验证有序集合 */ @Test public void checkSortCollection() { log.info("自定义排序之创建排序器实现Comparator接口"); MyComparator myComparator = new MyComparator(); TreeMap<School, Integer> customizeComparator = new TreeMap<>(myComparator); customizeComparator.put(new School(UUID.randomUUID().toString(),UUID.randomUUID().toString(),1),1); customizeComparator.put(new School(UUID.randomUUID().toString(),UUID.randomUUID().toString(),-1),1); customizeComparator.put(new School(UUID.randomUUID().toString(),UUID.randomUUID().toString(),11),1); customizeComparator.forEach((k,v)->log.info("key:[{}],value:[{}]",k,v)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

大厂之路一由浅入深、并行基础、源码分析一 “J.U.C”之collections框架:ConcurrentHashMap扩容迁移等方法的源码分析
-
相关阅读:
合并请求格式太乱?工单内容各写各的?表单模板来帮你
学会Linux,看完这篇就行了!
基于springboot实现体育场馆运营平台项目【项目源码】
国庆作业6
Apifox:满足你对 Api 的所有幻想
基于Netty,搭建高性能IM即时通讯集群
非零基础自学Java (老师:韩顺平) 第14章 集合 14.13 Map 接口实现类 - HashMap
电容器选型指南-电子元器件选型指导系列
单体、分布式、 微服务架构发展
优思学院|摩托罗拉6西格玛诞生的故事
- 原文地址:https://blog.csdn.net/greek7777/article/details/128180229
