-
ActiveMQ 笔记(十)Linux部署:单机与集群部署流程
1. 单机部署
(1) 获取安装包
方法1:从官网下载
官网: ActiveMQ方法2:直接用wget命令下载
- cd /opt
- wget http://archive.apache.org/dist/activemq/5.15.3/apache-activemq-5.15.3-bin.tar.gz
(2)解压安装包并拷贝到工作目录
- cd /opt/apache-activemq-5.15.3
- cp -r apache-activemq-5.15.3 /usr/local/activemq-stand-alone
使用wget下载安装包,解压后,
(3)启动activemq/usr/local/activemq-stand-alone/bin/activemq start全路径启动
/usr/local/activemq-stand-alone/bin/activemq start(4)带运行日志的启动方式
让启动的日志信息不在控制台打印,而放到专门的文件中:- mkdir log
- touch log/myRunmq.log
- ./bin/activemq start > ./log/myRunmq.log
(5)关闭activemq
./activemq stop(6)重启activemq
./activemq restart(7)验证:访问apache activemq控制台
默认的用户名和密码是admin/admin
(8)备注:- ActiveMQ采用61616端口提供JMS服务
- ActiveMQ采用8161端口提供管理控制台服务
(9)关闭进程
ps -ef | grep activemq | grep -v grep | awk '{print $2}' | xargs -r kill -9说明:
- | 管道符,用来隔开两个命令,管道符左边命令的输出会作为管道符右边命令的输入
- ps 命令用来列出系统中当前运行的进程,ps -ef 显示所有进程信息,连同命令行
- grep 命令用来过滤/搜索特定字符,grep test在这里为搜索过滤所有含有test名称的进程
- grep -v grep 显示不包含匹配文本的所有行,在这里为筛选出所有不包含grep名称的进程,对上一步的进程再做一次筛选(ps -ef列出了所有的进程,包括命令行)
- awk 在文件或字符串中基于指定规则浏览和抽取信息,把文件逐行读入,以空格为默认分隔符将每行切片,然后进行后续处理。这里利用awk '{print $2}' 将上一步中过滤得到的进程进行打印,$2表示打印第二个域(PID, 进程号) $0 表示所有域,$1表示第一个域,$n表示第n个域
- xargs 命令是给命令传递参数的过滤器,善于把标准数据转换成命令行参数。在这里则是获取前一个命令的输出,把它转换成命令行参数传递给后面的kill命令。-r选项表示如果输入为空,则不执行后面的命令
- kill -9 强制关闭进程
(10)卸载
activemq解压缩版,只需要删除安装目录即可。建议卸载前,先关闭进程。rm -rf /usr/local/activemq-stand-alone/1.2 集群方案(共有三种)
主要是基于zookeeper+replicated-leveldb-store的主从集群- 基于shareFileSystem共享文件系统(KahaDB)
- 基于JDBC
- 基于可复制的LevelDB
2. 基于zookeeper+LevelDB集群
官网提供的集群原理图: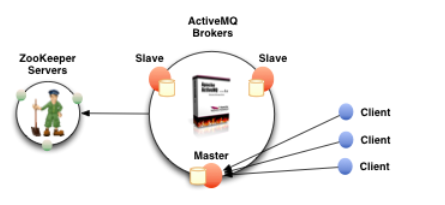
2.1 概述
5.9.0新推出的主从实现,基于zookeeper来选举出一个master,其他节点自动作为slave实时同步消息。因为有实时同步数据的slave的存在,master不用担心数据丢失,所以leveldb会优先采用内存存储消息,异步同步到磁盘。所以该方式的activeMQ读写性能都最好,特别是写性能能够媲美非持久化消息。
2.2 zookeeper集群搭建
由于Kafka依赖于Zk,因此搭建Kafka环境需先搭建Zk集群环境。
主机 ip 主机一 192.168.126.135 主机二 192.168.126.136 主机三 192.168.126.137 (1)上传zookeepe压缩包,并解压:
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz拷贝安装包到/usr/local/目录下:
cp -r apache-zookeeper-3.7.1-bin /usr/local/zookeeper进入到 conf 目录,看到 zoo_sample.cfg 文件,cp 复制生成 zoo.cfg 文件,如下:
cp conf/zoo_sample.cfg conf/zoo.cfg(3)创建data目录,并新建myid用于集群服务,里面内容填写当前主机id,我是三台服务器的集群,id分别为1,2,3
- mkdir /usr/local/zookeeper/data
- vim data/myid
(4)将zookeeper/conf下的zoo_sample.cfg重命名为zoo.cfg
修改内容:
- dataDir=/usr/local/zookeeper/data
- #这个地方的路径就是上面创建data文件夹的地址。根据自己的实际地址填写。
并在文本最后添加节点信息:
- server.1=192.168.126.135:2888:3888
- server.2=192.168.126.136:2888:3888
- server.3=192.168.126.137:2888:3888
节点信息里的 “server.”后面的数字就是约定该服务器的主机id。必须一致,不然集群启动会失败。
(5)启动zookeeper
/usr/local/zookeeper/bin/zkServer.sh start(6)查看zookeeper状态
/usr/local/zookeeper/bin/zkServer.sh status -
相关阅读:
UI5 Tooling
以数智化驱动为核心,构建研发效能增长动力
【台前调度】使用指南:如何打开和关闭iPadOS 16台前调度
朴素贝叶斯——垃圾邮件过滤
基础复习——共享参数SharedPreferences——记住密码项目——存储卡的文件操作(读写文件&读写图片)...
Python调用C++/CUDA
nmap各种扫描的注意事项
2023高频前端面试题-HTML
概述:隐式神经表示(Implicit Neural Representations,INRs)
Kubernetes 部署集群1.28.2版本(无坑)
- 原文地址:https://blog.csdn.net/weixin_42405670/article/details/128142498