-
三天入门Redis【快速浏览版】
文章目录
第一天
1.1 Redis基础
1.1.1 NoSql引入
从现代网络架构来理解当前NoSql的一些主要功能

1.1.2 NoSql特点
- NoSql概述
NoSql为“Not Only Sql”,意味着不只是sql,泛指非关系型数据库。NoSql不依赖业务逻辑方式存储,而以简单的key-value模式存储。因此大大增加了数据库的扩展能力。- 不遵循SQL标准;
- 不支持ACID;
- 远超于SQL的性能;
- NoSql的应用场景
- 对数据高并发读写;
- 海量数据的读写;
- 对数据高可拓展性的;
- NoSql不适用场景
- 需要事务支持;
- 基于sql的结构化查询存储,处理复杂的关系,需要“即席”查询;
- 用不着sql的和用了sql也不行的,就用NoSql;
1.1.3 NoSql数据库
- Hbase:Hbase的目标就是处理数据量非常庞大的表,可以用普通计算机处理超过10万亿行数据,还可以处理数百万列的数据表;
- Cassandra:其设计的目的在于管理由大量商用服务器构建起来的庞大集群上的海量数据(数据量通常达到PB级别);
- Neo4j:图数据库;
1.1.4 Redis概述
- redis是一个开源的key-value存储系统;
- 和Memcached类似。它支持的value类型相对较多,包括string,list,set,zset,hash;
- 这些数据都支持pop/push,add/remove以及取交集和差集及更丰富的操作,而这些操作都是原子性的【事务包含的所有操作要么全部成功,要么全部失败回滚】;
- 在这个基础之上,redis支持各种不同方式的排序;
- 与Memcached一样,为了保证效率,数据都是缓存在内存当中的。区别是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件中;
- 并在这个基础之上实现了master-slave(主从)同步;
1.1.5 Redis文件的作用
- redis-benchmark:性能测试工具,可以在本机上运行,查看自己机器的性能;
- redis-check-aof:修改有问题的aof文件;
- redis-check-rdb:修复有问题的dump.rdb;
- redis-sentinel:Redis集群使用;
- redis-cli:客户端,操作入口;
- redis-server:Redis服务启动命令;
# 以指定的配置文件启动redis服务 # 这里的/etc/redis-conf是在原始的redis-conf上cp过来的, # 修改后在已改文件运行,不会破坏原有的那个文件 redis-server /etc/redis-conf #Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf- 1
- 2
- 3
- 4
- 5
1.1.6 Redis相关介绍
- redis默认的端口是6379
- 与其他的NoSql相比,Redis能支持更多的数据类型单线程+多路IO复用

1.2 常用的五大类型及操作⭐️
1.2.1 Redis键(key)
# 查看所得键 keys * # 查看具体某一个键是否存在 exists keyname # 查看键的类型 type keyname # 删除指定key数据 del keyname # 根据value选择非阻塞删除[仅将key从keyspace元数据中删除,真正的删除会在后续的异步操作] unlink keyname # 为key设置过期时间 expire keyname 10 # 查看key还有多少秒过期,-1表示永不过期,-2表示已经过期 ttl keyname- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.2.2 库的一些操作
# 切换库[redis中默认有16个库,一般默认使用0号库] select databaseNum # 查看当前数据库key的数量 dbsize # 清空当前库 flushdb # 通杀全部库 flushall- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.2.3 Redis字符串
-
简介
- String类型是Redis最基本的类型;
- String类型是二进制安全的。意味着Redis的String可以包含任何数据,包括jpg图片和序列化对象;
- 一个Redis中字符串value最多可以是512M;
-
常用命令
- 添加
# 当key不存在时候,可以往数据库中添加一对key-value # 如果key存在,相当于修改了对应key的value【覆盖】 set <key><value> # 如果想要实现key不存在的时候才设置成功,也就是不覆盖设置 setnx <key><vale> # 用新值替换旧值,并返回旧值 getset <key><value>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 获取
get <key>- 1
- 追加
# 相当于在对应key的value后面追加新的内容,返回追加后的长度 append <key><value>- 1
- 2
- 获取长度
strlen <key>- 1
- value值增1
# value值必须为数值型 # keyname对应的value值增加1,如果原来空,则值变为1。返回加后的值 incr <key> # 减同理 decr <key>- 1
- 2
- 3
- 4
- 5
- value增长指定幅度
# keyname对应value增加increasement incrby <key><increasement> # keyname对应value减少decreasement decrby <key><decreasement>- 1
- 2
- 3
- 4
- 依次增加多对key
mset <key1><value1><key2><value2>.... msetnx <key1><value1><key2><value2>....- 1
- 2
- 同时获取多个key对应对应的value
mget <key1><key2><key3>....- 1
- 获取指定范围取值
# 获取值的范围,类似java中substring,前包,后包 getrange <key><起始位置><结束位置>- 1
- 2
- 从指定位置覆盖
# 有一点抽线看下图中的展示 setrange <key><起始位置><value> # 例子: 127.0.0.1:6379> get name "lucytom" 127.0.0.1:6379> setrange name 3 abc (integer) 7 127.0.0.1:6379> get name "lucabcm"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 设置键的同时设置过期时间
setex <key><过期时间><value>- 1
-
数据结构
redis的String的底层其实就是一个可变长度的字符串
1.2.4 Redis列表(List)
- 简介
- List可以实现单键多值。
- Redis列表是最简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边);
- 它的底层实际上是一个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点的性能会比较差;
- 常用命令
- 添加
# 从左边/右边插入一个或多个值 lpush/rpush <key><value1><value2>...- 1
- 2
- 导出
# 值在键在,值亡人亡 # 从左边/右边吐出一个值 lpop/rpop <key>- 1
- 2
- 3
- 按照索引下标获得元素
# 从左到右 lrange <key><start><stop>- 1
- 2
- 按照索引下标获得元素
# 从左到右 lindex <key><index>- 1
- 2
- 获取列表长度
llen <key>- 1
- 在value后main插入一个newvalue
linsert <key> before <value><newvalue>- 1
- 从左边删除n个value
# (从左到右) lrem <key><n><value>- 1
- 2
- 替换下标为index的值
lset <key><index><value- 1
- 数据结构
List的数据结构为快速链表quickList- 首先在列表元素较少的情况下会使用一块连续的内存储存,这个结构就是ziplist,也即是压缩列表。
- 它将所有的雨啊怒紧挨着一起存储,分配的一块连续的内存。
- 当数据量较多的时候才会改成quickList。
- 因为普通链表需要的附加指针空间较大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next;
- Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。

1.2.5 Redis集合(Set)
- 简介
- redis set对外提供一个功能与list类似的一个列表的功能,特殊之处在于set是可以自动排重的,当需要存储一个列表数据,但不希望出现重复数据时,set是一个很好的选择。
- Redis的set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)
一个算法,随着数据的增加,执行时间的长度如果是O(1),数据增加,查找数据的时间不变
- 常用命令
- 添加
# 讲一个或多个member元素加入到集合key中,已经存在的元素将被忽略 sadd <key><value1><value1>- 1
- 2
- 获取
# 取出集合中的所有值 smembers <key>- 1
- 2
- 删除
# 从key对应的集合中依次进行删除 srem <key><value1><value2>...- 1
- 2
- 移动
# 把集合中一个值从一个集合移动到另一个集合 smove <source><destination><value>- 1
- 2
- 判断集合中是否有该值
# 判断key对应的集合中是否有value,有1,没有0 sismember <key><value>- 1
- 2
- 获取集合元素的个数
scard <key>- 1
- 随机取出n个值
# 随机从该集合中吐出count个值 spop <key><count>- 1
- 2
- 随机取出n个值
# 随机从该集合中取出n个值,不会从集合中删除 srandmember <key><count> # 例子 127.0.0.1:6379> smembers name1 1) "jack" 2) "xiaogang" 127.0.0.1:6379> smembers name2 1) "tompsen" 2) "kevin" 3) "ross" 127.0.0.1:6379> smove name2 name1 kevin (integer) 1 127.0.0.1:6379> smembers name1 1) "jack" 2) "xiaogang" 3) "kevin"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 返回两个集合的交集元素
sinter <key1><key2>- 1
- 返回两个集合的并集元素
sunion <key1><key2>- 1
- 返回两个集合的差集元素
# key1中的不包含key2中的 sdiff <key1><key2>- 1
- 2
- 数据结构
- Redis中Set的数据结构是dict字典,字典是用哈希表实现的;
- Java中的HashSet的内部结构使用的是HashMap,只不过所有的value都指向同一个对象。Redis的Set结构也是一样,他的内部也是使用Hash结构,所有的value都是指向一个内部值;
1.2.6 Redis(Hash)
-
简介
- Redis hash 是一个键值对集合;
- Redis hash是一个string类型的filed和value的映射表,hash特别适用于存储对象,类似Java里面的Map
; - 用户ID为查找的key,存储的value用户对象包括姓名,年龄,生日等信息,如果用普通的key/value结构来存储;
其存储结构如下:

-
常用命令
- 添加
hset <key><filed><value> # 当然也可以使用hsetnx- 1
- 2
- 3
- 获取
hget <key><filed>- 1
- 批量设置
hmset... - 1
- 判断key是否存在
# 存在返回1,不存在返回0 hexits <key><filed>- 1
- 2
- 查看该hash集合的所有filed
hkeys <key>- 1
- 查看该hash集合的所有value
hvals <key>- 1
- 指定filed的值加上增量1
# 前提是filed必须是数值型 hincrby <key><filed><increment>- 1
- 2
-
数据结构
Hash类型对应的数据结构两种:ziplist(压缩列表),HashTable(哈希表)。当filed-value长度比较短且个数较少时,使用ziplist,否则使用hashtable。
1.2.7 Redis有序集合(ZSet)
- 简介
- Rdies有序几个zset与普通set非常相似,是一个没有重复元素的字符串集合。
- 不通之处在于Zset集合的每个成员都关联了一个评分(Score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合成员是唯一的,但是评分可以重复。
- 因为元素是有序的,所以你可以很快的根据评分(Score)或者次序(Position)获取一个范围的元素。
- 访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
- 常用命令
- 添加
# 将一个或多个member元素及其score值加入到有序集key当中 zadd <key><score1><value1><score2><value2>- 1
- 2
- 获取
# 返回有序集合key中,下标在之间的元素 - 1
- 2
- 3
- 返回指定分数之间结果集
# 返回min和max之间的结果集 zrangebyscore <key><min><max>- 1
- 2
- 返回指定分数之间结果集(以从大到小)
zrevrangebyscore <key><min><max>- 1
- 为元素的score加上增量
zincrby <key><increment><member>- 1
- 删除
zrem <key><member>- 1
- 统计指定Score之间的个数
zcount <key><min><max>- 1
- 返回该值在集合中的排名,从0开始
zrank <key><member>- 1
- 数据结构
- SortSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于java数据结构Map
- 具体有以下两个数据结构
- Hash,hash的作用就是关联元素value和权重score,保障元素的唯一性,可以通过元素value找到相应的score值。【定义元素结构】
- 跳跃表,跳跃表的目的在于给元素score排序,根据score的范围获取元素聊表。【定位元素】

- SortSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于java数据结构Map
1.3 Redis配置文件
# 注释了来允许远程连接 bind 127.0.0.1 -::1 # 关闭保护模型 protected-mode yes- 1
- 2
- 3
- 4
redis配置文件涉及到非常多的功能,在这里先不具体得去了解细节。等日后有需要再去具体的了解即可。
1.4 发布与订阅
1.4.1 什么是发布与订阅
- Redis发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接受消息;
- Redis客户端可以订阅任意数量的频道;
1.4.2 Redis的发布与订阅
-
客户端可以订阅频道

-
当频道发布消息之后,就会把消息发送给订阅消息的客户端

1.4.3 订阅发布的操作
- 打开一个客户端订阅channel1
SUBSCRIBE <channel...>- 1
- 打开另一个客户端,给channel1发布消息hello
publish <channel><message>- 1
1.5 Redis6新数据类型
1.5.1 Bitmap
-
简介
Redis提供了Bitmaps这个“数据类型”,可以实现对位的操作:- Bitmaps本身不是一种数据类型,实际上它就是字符串(key-value);
- Bitmaps单独提供一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把Bitmaps想象成一个以位为单位的数组,数据的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量。

-
常用命令
- 添加
setbit <key><offset><value>- 1
1.很多应用的用户id以一个指定的数字(例如10000)开头,直接将用户的id和Bitmaps的偏移量对应势必会造成一定的浪费,通常的做法是每次setbit操作时将用户id减去一个指定的数字。
2.在第一次初始化Bitmaps时候,假如偏移量非常大,那么整个初始化过程执行会比较慢,可能会造成Redis的阻塞。- 获取
# 获取键的第offset位的值(从0开始算) getbit <key><offset>- 1
- 2
- 统计个数
# 统计个位置上值为1的个数 bitcount <key> # 在上面的例子基础之上 bitcount <key><start><end>- 1
- 2
- 3
- 4
- 操作
# operation可以是and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存在destkey中 bitop <operation><destkey><key...>- 1
- 2
-
Bitmap和Set的对比
在针对活跃用户存储方面,Bitmap在内存和查询时间上天生具有非常大的优势。但是在活跃用户较少或者僵尸用户较多的时候,使用该类型来保存非产生非常大的冗余。
1.5.2 HyperLogLog
- 简介
在工作中,我们经常遇到与统计相关的功能需要,比如统计网站PV(page view的页面访问量),可以使用Redis的incr、incrby轻松实现。但像UV(unique Visitor)独立访问、独立ip数、搜索记录等需要去重和计数问题如何去解决?这种求集合中不重复的问题称为基数问题。- 解决基数问题有很多种方案:
(1)数据存储在mysql表当中,使用distinct count计算不重复个数;
(2)适用Redis提供的hash、set、bitmaps等数据结构来处理;
以上的方案结果精确,但是随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。 - 能否能够降低一定的精度来平衡储存空间?Redis推出了HyperLogLog。
- 解决基数问题有很多种方案:
- Redis HyperLogLog是用来做基数统计的算法,HyperLogLog的优点是在输入的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的;
- 在Redis里面,每个HyperLogLog键只需要花费12kb内存,就可以计算接近2^64个不同的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
- 但是,因为HyperLogLog只会根据输入与元素来计算基数,而不会存储输入元素本身,所以HyperLogLog不能集合那样,返回输入的各个元素。
- 什么是基数?
简单来说,比如数据集合 { 1 , 3 , 5 , 7 , 5 , 7 , 8 } \{1,3,5,7,5,7,8\} {1,3,5,7,5,7,8},那么这个数据集的基数集为{1,3,5,7,8},基数(不重复的元素)为5。基数估计就是在误差可接受的范围内,快速计算基数。
- 常用命令
- 添加
# 添加指定元素到HyperLogLog中 pfadd <key><element...>- 1
- 2
- 统计个数
pfcount <key>- 1
- 融合
# 将多个key进行融合 pfmerge <key...>- 1
- 2
1.5.3 GeoSpitial
- 简介
Redis3.2中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置、查询、范围查询、距离查询、经纬度Hash等常见操作。 - 常用命令
- 添加
# 添加地理位置(经度、纬度、名称) # 有效的精度从-180度到180。有效的纬度从-85.05度到85.05度 # 当坐标位置超出指定位置时候,该命令将返回一个错误 # 已经添加的错误是无法再次往里面添加的 geoadd <key><longtitude><latitude><member>...- 1
- 2
- 3
- 4
- 5
- 获取
# 获取指定地区的坐标值 geopos <key><member>- 1
- 2
- 找出指定范围内的元素
# 以给定的经纬度为中心,找出某一半径内的元素 georadius <key><longitude><latitude>radius m|km|ft|mi- 1
- 2
第二天
2.1 Go连接Redis
本文使用go-redis作为连接工具
2.1.1 测试连接
package main import ( "context" "fmt" "github.com/go-redis/redis/v8" ) // Background返回一个非空的Context。 它永远不会被取消,没有值,也没有期限。 // 它通常在main函数,初始化和测试时使用,并用作传入请求的顶级上下文。 var ctx = context.Background() var DB *redis.Client func main() { rdb := redis.NewClient(&redis.Options{ // 需要修改成你的配置,本地无需修改 Addr: "127.0.0.1:6379", Password: "", DB: 0, }) _, err := rdb.Ping(ctx).Result() if err != nil { fmt.Println(err) } fmt.Println("连接成功") // 成功连接将其赋值给全局变量 DB = rdb }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
2.1.2 go-redis操作String
func OperateString() { // 测试添加 res1, err := DB.Set(ctx, "name", "kevin", time.Minute).Result() if err != nil { fmt.Println(err) } fmt.Printf("插入成功:%s\n", res1) // 同时多行插入 res2, err := DB.MSet(ctx, "car", "BMW", "flower", "ross").Result() if err != nil { fmt.Println(err) } fmt.Printf("插入多行成功:%s\n", res2) // 获取 res3, err := DB.Get(ctx, "name").Result() if err != nil { fmt.Println(err) return } fmt.Printf("key=name value=%s\n", res3) // 追加 res4, err := DB.Append(ctx, "car", "benz").Result() if err != nil { fmt.Println(err) return } fmt.Printf("追加成功:%d", res4) // 获取长度 res5, err := DB.StrLen(ctx, "car").Result() if err != nil { fmt.Println(err) } fmt.Printf("长度为:%d\n", res5) // value值增加1 DB.MSet(ctx, "age", 15).Result() res6, err := DB.Incr(ctx, "age").Result() if err != nil { fmt.Println(err) } fmt.Println(res6) // 按照指定的值增加 res7, err := DB.IncrBy(ctx, "age", 4).Result() if err != nil { fmt.Println(err) } fmt.Println("增长后的age值:", res7) // 一次获取多对值 res8, err := DB.MGet(ctx, "age", "car", "flower").Result() if err != nil { fmt.Println(err) } for _, v := range res8 { fmt.Println(v) } // 从指定的位置获取值 res9, err := DB.GetRange(ctx, "car", 0, 1).Result() if err != nil { fmt.Println(err) } fmt.Println("值为:", res9) // 设置键的过期时间 res10, err := DB.SetEX(ctx, "animal", "bird", 30*time.Minute).Result() if err != nil { fmt.Println(err) } fmt.Println(res10) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
2.1.3 go-redis操作List
func OperateList() { // 添加 DB.LPush(ctx, "name", "marry") DB.LPush(ctx, "name", "tom") DB.LPush(ctx, "name", "jack") // 查看 res2, err := DB.LRange(ctx, "mame", 0, -1).Result() if err != nil { fmt.Println(err) } for _, v := range res2 { fmt.Println(v) } // 导出一个 // 获取列表长度 length, err := DB.LLen(ctx, "name").Uint64() fmt.Println("长度为:", length) res3, err := DB.LPop(ctx, "name").Result() if err != nil { fmt.Println(err) } fmt.Printf("pop的结果是:%s\n", res3) length, err = DB.LLen(ctx, "name").Uint64() fmt.Println("长度为:", length) //从左边删除一个 n, err := DB.LRem(ctx, "name", 1, "jack").Result() if err != nil { fmt.Println(err) } fmt.Printf("删除了%d\n", n) // 将下标为index的value改为指定的值 res4, err := DB.LSet(ctx, "name", 1, "ross").Result() if err != nil { fmt.Println(err) } fmt.Println("改值后", res4) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
2.1.4 go-redis操作Set
func OperateSet() { // 添加 DB.SAdd(ctx, "name", "xh") DB.SAdd(ctx, "name", "ross") DB.SAdd(ctx, "name", "kevin") DB.SAdd(ctx, "name", "jack") DB.SAdd(ctx, "name", "scoot") DB.SAdd(ctx, "car", "scoot") DB.SAdd(ctx, "car", "ross") DB.SAdd(ctx, "car", "dz") // 获取 res1, err := DB.SMembers(ctx, "name").Result() if err != nil { fmt.Println(err) } for _, v := range res1 { fmt.Println(v) } // 删除 res2, err := DB.SRem(ctx, "name", "xh").Result() if err != nil { fmt.Println(err) } fmt.Printf("删除%d\n个", res2) // 判断集合中是否有该值 res3, err := DB.SIsMember(ctx, "name", "kevin").Result() if err != nil { fmt.Println(err) } if res3 { fmt.Println("该集合中有kevin") } // 获取集合元素的个数 res4, err := DB.SCard(ctx, "name").Uint64() if err != nil { fmt.Println(err) } fmt.Printf("此时集合中有%d个\n", res4) // 随机吐出1个 res5, err := DB.SPop(ctx, "name").Result() if err != nil { fmt.Println(err) } fmt.Println("随机突出的一个元素是:", res5) // 随机吐出n个 res6, err := DB.SRandMemberN(ctx, "name", 3).Result() if err != nil { fmt.Println(err) } fmt.Println(res6) // 返回两个集合的交集 res7, err := DB.SInter(ctx, "name", "car").Result() if err != nil { fmt.Println(err) } fmt.Println(res7) // 返回两个集合的并集 res8, err := DB.SUnion(ctx, "name", "car").Result() if err != nil { fmt.Println(err) } fmt.Println(res8) // 返回两个集合的差集【name中有,而car中没有】 res9, err := DB.SDiff(ctx, "name", "car").Result() if err != nil { fmt.Println(err) } fmt.Println(res9) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
2.1.5 go-redis操作Hash
func OperateHash() { // 添加 DB.HSet(ctx, "user001", "name", "kevin") DB.HSet(ctx, "user001", "age", 15) DB.HSet(ctx, "user001", "year", 1999) DB.HSet(ctx, "user001", "country", "China") DB.HSet(ctx, "user002", "name", "ross") DB.HSet(ctx, "user002", "age", 17) DB.HSet(ctx, "user002", "year", 2000) DB.HSet(ctx, "user002", "country", "American") // 获取指定filed name002, err := DB.HGet(ctx, "user002", "name").Result() if err != nil { fmt.Println(err) } fmt.Println("user002_name=", name002) // 批量设置 res1, err := DB.HMSet(ctx, "user003", "name", "zhangsan", "age", 12).Result() if err != nil { fmt.Println(err) } fmt.Println(res1) // 判断key是否存在 res2, err := DB.HExists(ctx, "user002", "name").Result() if err != nil { fmt.Println(err) } fmt.Println(res2) // 查看该hash集合的所有value res3, err := DB.HVals(ctx, "user001").Result() if err != nil { fmt.Println(err) } fmt.Println(res3) // 在指定的值加上增量1 res4, err := DB.HIncrBy(ctx, "user001", "age", 1).Result() if err != nil { fmt.Println(err) } fmt.Println(res4) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
2.1.6 go-redis操作Zset
func OperateZset() { // 添加 DB.ZAdd(ctx, "name", &redis.Z{ Score: 2, Member: "kevin", }) DB.ZAdd(ctx, "name", &redis.Z{ Score: 3, Member: "jack", }) DB.ZAdd(ctx, "name", &redis.Z{ Score: 1, Member: "ross", }) DB.ZAdd(ctx, "name", &redis.Z{ Score: 5, Member: "tom", }) //获取 res1, err := DB.ZRange(ctx, "name", 1, 3).Result() if err != nil { fmt.Println(err) } fmt.Println(res1) //返回指定分数之间结果集 res2, err := DB.ZRangeByScore(ctx, "name", &redis.ZRangeBy{ Min: "0", Max: "3", }).Result() fmt.Println(res2) //删除某一个元素 res3, err := DB.ZRem(ctx, "name", "jack").Result() if err != nil { fmt.Println(err) } fmt.Println(res3) // 返回集合中的排名 res4, err := DB.ZRank(ctx, "name", "tom").Result() if err != nil { fmt.Println(err) } fmt.Println(res4) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
2.1.7 一些常规操作
func OperateDB() { // 查看所有的键 res, err := DB.Keys(ctx, "*").Result() if err != nil { fmt.Println(err) } fmt.Println(res) // 查看某一个键是否存在 n, err := DB.Exists(ctx, "name").Result() if err != nil { fmt.Println(err) } fmt.Println(n) // 查看键的类型 str, err := DB.Type(ctx, "name").Result() if err != nil { fmt.Println(err) } fmt.Println(str) // 为键设置过期时间 success, err := DB.Expire(ctx, "name", 5*time.Minute).Result() if err != nil { fmt.Println(err) } if success { fmt.Println("设置时间成功") } //查看键的过期时间 t, err := DB.TTL(ctx, "name").Result() if err != nil { fmt.Println(err) } fmt.Println(t) time.Sleep(5 * time.Second) t, err = DB.TTL(ctx, "name").Result() if err != nil { fmt.Println(err) } fmt.Println(t) //更换数据库 n, err = DB.DBSize(ctx).Result() if err != nil { fmt.Println(err) } fmt.Println("数据库的大小为", n) //删除键 n, err = DB.Del(ctx, "name").Result() if err != nil { fmt.Println(err) } fmt.Println("删除成功") //删除库中所有的数据 DB.FlushDB(ctx).Result() }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
2.2 Redis事务
2.2.1 Redis事务定义
- redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序执行。事务在执行的过程中,不会被其它客户端发送来的命令打断。
- redis事务的主要作用就是串联多个命令,防止别的命令插队。
2.2.2 Muti、Exec、Discard
-
从输入Multi命令开始,输入的命令都会依次进入命令队列当中,但不会执行,直到输入Exec后,Redis会将之前的命令队列中的命令依次执行。

-
演示1如下
127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> set user011 dz QUEUED 127.0.0.1:6379(TX)> set user012 zs QUEUED 127.0.0.1:6379(TX)> exec 1) OK 2) OK- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
演示2如下
127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> set a1 a QUEUED 127.0.0.1:6379(TX)> set a2 b QUEUED 127.0.0.1:6379(TX)> discard OK- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
注意,,如果组队中出现了报告错误,执行时整个的所有队列都会取消(如例子1)。如果组队中没有报错,而是逻辑错误,不会取消整个队列,只有执行到那个命令的时候才出错,其余地方都正常执行,见下面这个例子。
# 例子1 127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> set name1 kevin QUEUED 127.0.0.1:6379(TX)> set name2 ross QUEUED 127.0.0.1:6379(TX)> set name3 (error) ERR wrong number of arguments for 'set' command 127.0.0.1:6379(TX)> exec (error) EXECABORT Transaction discarded because of previous errors.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
# 例子2 127.0.0.1:6379> set name dz OK 127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> set name1 kevin QUEUED 127.0.0.1:6379(TX)> incr name QUEUED 127.0.0.1:6379(TX)> set name2 ross QUEUED 127.0.0.1:6379(TX)> exec 1) OK 2) (error) ERR value is not an integer or out of range 3) OK- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.2.3 事务冲突
- 简介
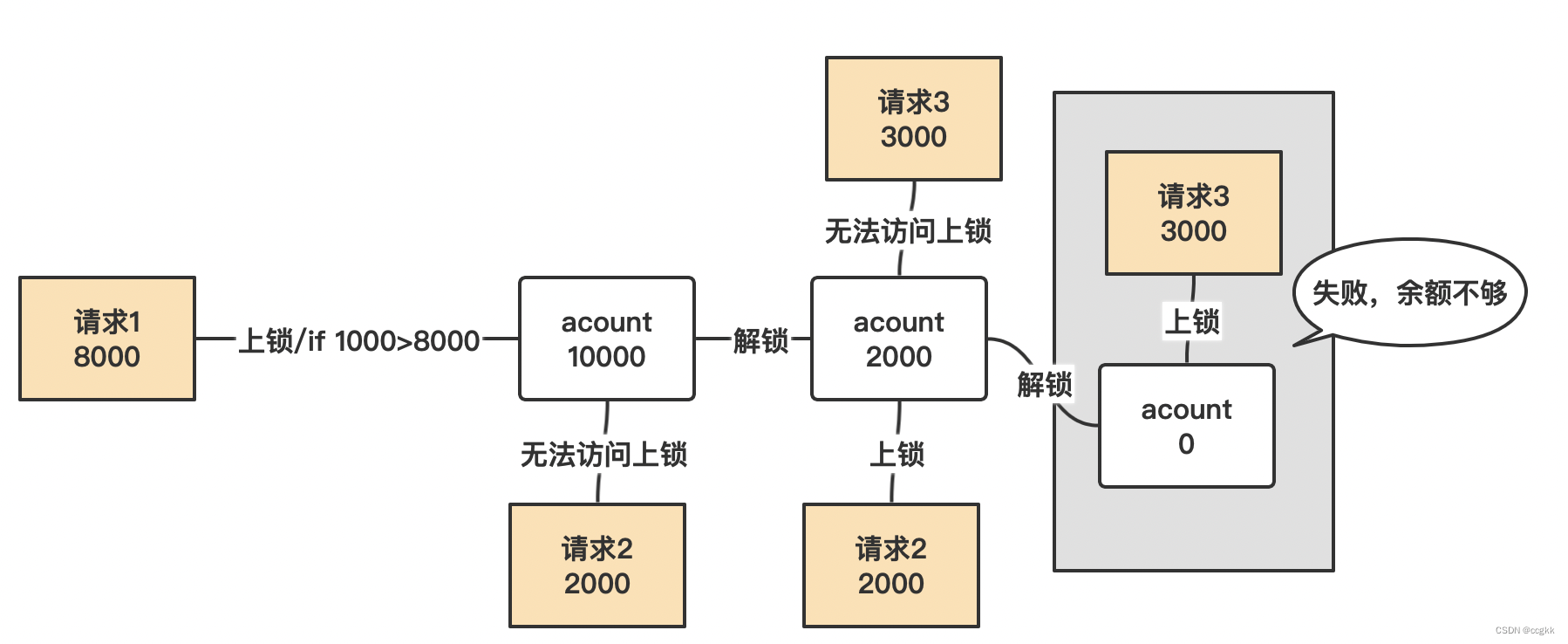
想象一个场景:很多人有你的账户,同时去参加双十一抢购。比如说原账户有10000元,一个请求想给金额减8000,一个请求想给金额减5000,一个请求想给金额减1000。如下场景:

- 解决方案1:悲观锁
悲观锁,顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿取数据的时候就会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统关系性数据库里面有很多都是这种锁机制,比如行锁,表锁等。读锁、写锁等都是在操作之前先上锁。缺点是效率很低。
- 解决方案2:乐观锁
乐观锁,顾名思义。就是很乐观,每次去拿取数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有更新这个数据,可以使用版本号等机制。【乐观锁的关键在于理解这个地方的version,其实其相当于给数据加上了一个版本号。比如说像在下图中,两个请求分别拿到数据的v1.0版本,如果第一个请求先处理了数据,则将数据的版本变为v1.1。而在请求2处理数据时,它会先请求数据库获取版本的数据号,如果数据号与自己对应的版本号不对应,则不能处理该数据。】乐观锁适用于多度的应用类型,这样可以提高吞吐量。redis就是利用check-and-set机制实现这个事务的

2.2.4 常用命令
- 在执行multi之前,先执行watch key1 [key2],可以监视一个(或多个)key,如果在事务执行之前这个key被其他命令所改动,那么事物将被打断。
WATCH key [key...]- 1

- 取消对命令的监视
unwatch key [key...]- 1
2.2.5 Redis事务的三个特性
- 单独的隔离操作
- 事务中的所有命令都会序列化、按顺序地执行。事务在执行过程中,不会被其他客户端发来的命令请求所打断。
- 没有隔离级别的概念
- 队列中的命令没有提交之前都不会被实际执行,因为事务提交前的任何指令都不会被实际执行。
- 不保证原子性
- 事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚。
2.3 秒杀案列
2.3.1 版本1-简单版本
连接池的配置详细见csdn博客
func MsCode(uuid, prodid string) bool { // 1、对uuid和prodid进行非空判断 if uuid == "" || prodid == "" { return false } //2、获取连接 rdb := DB //3、拼接key kcKey := "kc:" + prodid + ":qt" userKey := "sk:" + prodid + ":user" //4、获取库存 str, err := rdb.Get(ctx, kcKey).Result() if err != nil { fmt.Println(err) fmt.Println("秒杀还未开始.......") return false } // 5、判断用户是否重复秒杀操作 flag, err := rdb.SIsMember(ctx, userKey, userKey).Result() if err != nil { fmt.Println(err) } if flag { fmt.Println("你已经参加了秒杀,无法再次参加。。。。") return false } // 6、判断商品数量,如果库存数量小于1,秒杀结束 str, err = rdb.Get(ctx, kcKey).Result() if err != nil { fmt.Println(err) } n, err := strconv.Atoi(str) if err != nil { fmt.Println(err) } if n < 1 { fmt.Println("秒杀结束,请下次再来吧。。。。") return false } // 7、秒杀过程 // 7.1、库存减1 num, err := rdb.Decr(ctx, kcKey).Result() if err != nil { fmt.Println(err) } if num != 0 { // 7.2、添加用户 rdb.SAdd(ctx, userKey, uuid) } return true }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
2.3.2 版本2-超卖问题
版本1会有一个问题,就是如果接受并发抢购问题,会造成多卖的情况。为了解决这个情况,我们需要监视库存,然后开启事务处理,代码如下:
err = rdb.Watch(ctx, func(tx *redis.Tx) error { n, err := tx.Get(ctx, kcKey).Int() if err != nil && err != redis.Nil { return err } if n <= 0 { return fmt.Errorf("抢购结束了!请下次早点来。。。。") } _, err = tx.TxPipelined(ctx, func(pipeliner redis.Pipeliner) error { err := pipeliner.Decr(ctx, kcKey).Err() if err != nil { return err } err = pipeliner.SAdd(ctx, userKey, uuid).Err() if err != nil { return err } return nil }) return err }, kcKey)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2.3.3 版本3—解决库存遗留问题
- 描述
因为redis中使用watch是使用了悲观锁的形态,而悲观锁会自然得造成库存问题,因此要使用乐观锁。而redis天然不支持乐观锁,基于此,需要时lua来编写相关脚本。 - Lua脚本语言
- Lua是一个小巧的语言,Lua脚本可以直接被C/C++调用,也可以反过来调用C/C++的函数,Lua并没有提供强大的库,一个完整的Lua解释器不过200k,所以不适合作为独立开发应用程序语言,而是作为嵌入式脚本语言。
- 很多应用程序、游戏使用Lua作为自己的嵌入式脚本语言,以此来实现可配置、可扩展性。这其中包括魔兽世界、魔兽争霸地图、愤怒的小鸟等众多游戏插件或外挂。
- Lua脚本在Redis中的优势
- 将复杂的或者多步的redis操作,写为一个脚本,一次提交给redis执行,减少反复连接redis的次数。提升性能。
- luan脚本类似redis事务,有一定的原子性,不会被其他命令插队,可以完成一些redis事务性的操作。
- redis的lua脚本功能,只有在redis2.6以上的版本才可以使用。
- 利用lua脚本淘汰用户,解决超卖问题。
- redis2.6版本以后,通过lua脚本解决争夺问题,实际上是redis利用其单线程的特性,用任务队列的方式解决多任务并发问题。
- 代码编写
func useLua(userid, prodid string) bool { //编写脚本 - 检查数值,是否够用,够用再减,否则返回减掉后的结果 var luaScript = redis.NewScript(` local userid=KEYS[1]; local prodid=KEYS[2]; local qtKey="sk:"..prodid..":qt"; local userKey="sk:"..prodid..":user"; local userExists=redis.call("sismember",userKey,userid); if tonumber(userExists)==1 then return 2; end local num=redis.call("get",qtKey); if tonumber(num)<=0 then return 0; else redis.call("decr",qtKey); redis.call("SAdd",userKey,userid); end return 1; `) //执行脚本 n, err := luaScript.Run(ctx, DB, []string{userid, prodid}).Result() if err != nil { return false } switch n { case int64(0): fmt.Println("抢购结束") return false case int64(1): fmt.Println(userid, ":抢购成功") return true case int64(2): fmt.Println(userid, ":已经抢购了") return false default: fmt.Println("发生未知错误!") return false } return true }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
通过下面的程序进行并发请求:
func main() { // 并发的版本 for i := 0; i < 20; i++ { go func() { uuid := GenerateUUID() prodid := "1023" time.Sleep(10 * time.Second) useLua(uuid, prodid) }() } time.Sleep(15 * time.Second)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.4 Redis持久化操作
2.4.1 操作1:RDB
- 什么是RDB?
在指定的时间间隔内将内存中的数据集快照写入到磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。【一句话描述:它是一个数据持久化的方法,由主线程创建的fork来执行一个将内存中的数据写入一个临时文件,然后周期性的替换dump.rdb】 - 备份是如何执行的
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上此持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完成性不是特别敏感,那么RDB方式要比AOF方式更加高效。RDB的缺点是最后一次持久化的数据可能丢失。这样做的优势很多,比如减少io操作、保证数据的一致性。其基本逻辑如下:

- RDB中的Fork
- fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器)数值都和原有进程一样,但是是一个全新的进程,并作为原进程的子进程
- 在Linux程序中,fork()会产生一个与父进程完全相同的子进程,但子进程在此后会被exec系统调用,出于效率考虑,Linux会引入"写时复制技术"
- 一般情况下父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程
写时复制技术:指的是先将数据写入到一个文件中,然后需要写入数据的时候直接用新的文件将原始的文件覆盖。
- dump.rdb文件-
在redis.conf配置文件名称,默认为dump.rdb
 同时注意配置文件中还有一个dir,这表示会在你启动redis的位置产生一个dump.rdb
同时注意配置文件中还有一个dir,这表示会在你启动redis的位置产生一个dump.rdb

如果在快照的时候发生错误就停止可以设置一下变量
 对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩,当然不压缩可以设置为no
对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩,当然不压缩可以设置为no 在存储完快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大概10%的性能消耗,如果希望获取最大的性能提升,可以关闭此功能。
在存储完快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大概10%的性能消耗,如果希望获取最大的性能提升,可以关闭此功能。 另外还可以配置save。
另外还可以配置save。
格式:save 秒钟 写操作次数
RDB是整个内存的压缩过的Snapshot,RDB的数据结构,可以配置复合的快照触发条件,默认是一分钟内改了一万次,或5分钟内改了10万次,或15分钟内修改了一次
禁用:不设置save指令,或者给save传入空字符串
- save VS bgsave
- save:save时只管保存,其他不管,全部阻塞,手动保存,不建议
- bgsave:Redis会在后台异步进行快照操作,快照的同时还可以响应客户端的请求。
可以通过lastsave命令获取最后一次执行快照的时间
- 优势
- 适合大规模的数据恢复;
- 对数据完成性和一致性要求不高更合适;
- 节省磁盘空间;
- 恢复速度快;

- 劣势
- fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
- 虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
- 在备份周期在一定间隔时间做一次备份,如果redis意外down掉的话,就会丢失最有一次快照后的所有修改。
- rdb的备份
- 将*.rdb的文件拷贝到别的地方
- rdb的恢复
- 关闭redis
- 先把备份的文件拷贝到工作目录下cp
- 启动redis,备份数据会直接加载
2.4.2 AOF
-
什么是AOF?
以日志的形式来记录每个写操作(增量保存),将redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容讲写指令从前到后执行一次以完成数据的恢复工作。 -
AOF持久化流程
- 客户端的请求写命令会被append追加到AOF缓冲区;
- AOF缓冲区根据AOF持久化策略[always,everysec,no]将操作sync同步到磁盘的AOF文件中;
- AOF文件大小超过重写策略或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量;
-
AOF文件默认不开启
- 可以在redis.conf中配置文件名称,默认为appendonly.aof;
- AOF文件的保存路径,同RDB的路径一致;
-
AOF和RDB同时开启,redis听谁的?
AOF和RDB同时开启,系统默认取AOF的数据(数据不存在丢失) -
AOF启动/修复/恢复
- AOF的备份机制和性能虽然和RDB不同,但是备份和恢复的操作同RDB一样,都是拷贝备份文件,需要恢复时在拷贝到redis的工作目录下,启动系统即加载
- 正常恢复
- 修改默认的appendonly no为yes
- 将有数据的aof文件复制一份保存到对应的目录中(查看目录:config get dir)
- 异常恢复
- 修改默认的appendonly no 为yes
- 如遇到AOF文件损坏,通过/usr/local/bin/redis-check-aof --fix appendonly.aof进行恢复
- 备份被写坏的AOF文件
- 恢复:重启redis,然后重新加载
-
AOF同步频率设置
- appendfsync always
始终同步。每次redis的写入都会被立刻记入日志;性能较差但数据完成性比较好 - appendfync everysec
每秒同步,每秒计入日志一次,如果宕机,本秒的数据可能丢失 - appendfsync no
redis不主动进行同步,把同步时机交给操作系统
- appendfsync always
-
ReWrite重写
- 什么是重写?
- AOF采用文件追加的方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过了所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集合,可以使用命令bgrewriteaof
- 重写原理,如何实现重写?
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),redis4.0版本后的重写,是指将上面rdb的快照,以二进制的形式附在aof头部,作为已有的历史数据,替换原来的流水账操作。 - 触发机制,何时重写?
Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发;重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定redis要满足一定的条件才会进行重写。
- 什么是重写?
-
优势
- 备份机制更稳健,丢失数据概率更低;
- 可读的日志文本,通过操作AOF更稳健,可以处理误操作
-
劣势
- 比如RDB占用更多的磁盘空间
- 恢复备份速度要慢
- 每次读写都同步的话,有一定的性能压力
- 存在个别Bug,造成恢复不能
2.4.3 总结用哪个?
官方推荐两个都启用。如果对数据不敏感,可以选单独用RDB。不建议单独用AOF,因为可能会出现Bug。如果只是单纯用内存缓存,可以都不用。
2.5 Redis的主从复制⭐️
2.5.1 主从复制是什么?
主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,master以写为主,Slave以读为主。

2.5.2 主从复制能干嘛?
- 读写分离【原来这就是所谓的读写分离,如果对一台服务器进行读操作或者写操作,那么该台数据库的读写压力太大了,因此这种设计能够十分有效的减少IO某一台的IO压力】;
- 容灾的快速恢复【其中一台出问题,能够切换到另外一台服务器,增加了容错】;
但是注意如果是主出现了问题怎么办呢?
事实上,一般不会出现多主多从的情况,而要解决这个问题,可以使用集群。

2.5.3 Redis主从复制配置⭐️
-
创建文件
-
复制redis.conf
-
配置一主两从,创建三个配置文件:redis6379.conf、redis6380.conf、redis6381.conf
-
在三个配置文件写入内容
include /myredis/redis.conf pidfile /var/run/redis_6379.pid port 6379 dbfilename dump6379.rdb- 1
- 2
- 3
- 4
-
修改appendonly为no
-
分别以指定的文件启动
# 使用本命令查看当前进程的情况 ps aux | grep redis- 1
- 2
-
查看三台主机运行情况
info replication- 1

-
配置主从关系
slaveof 主机ip 端口号- 1
-
在6380执行:slave 127.0.0.1 6380


-
同样将6379添加为6381的从服务器,最终搭建好的一个效果:
# 在master上添加一个key 127.0.0.1:6381> set name kevin OK 127.0.0.1:6381>- 1
- 2
- 3
- 4
# 在slave上获取key,注意slave不能设置key 127.0.0.1:6379> keys * 1) "name" 127.0.0.1:6379> get name "kevin" 127.0.0.1:6379>- 1
- 2
- 3
- 4
- 5
- 6
127.0.0.1:6380> keys * 1) "name" 127.0.0.1:6380> get name "kevin" 127.0.0.1:6380>- 1
- 2
- 3
- 4
- 5
2.5.4 主从复制原理
- 如果一个slave挂掉(可以使用shutdown模拟),然后重新启动后会发现,该服务器的角色从slave变成了master,需要重新使用slave命令重新配置,重新配置以后会加载数据,即使挂掉的期间中新添加的数据也会被添加进来。
- 如果一个master挂掉,那么slave仍然角色不变,如果这个时候在slaver中使用info replication查看信息其会显示master已经down【允许投敌,不允许串位】
- 主从复制原理如下:
- 当slaver连接上master之后,salver向master发送进行数据同步消息;
- master接到slaver发送过来的同步消息,先对这部分数据进行持久化到rdb文件中,把rdb文件发送到slaver中,而slaver再从master中拿到的rdb文件中进行读取。
- 每次主服务器进行写操作之后,和服务器进行数据自动同步。
- 全量复制:slave服务在接受到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master继续讲新的所有收集到的修改命令依次传给slave,完成同步。
2.5.5 薪火相传
这种架构简单来说就是将slaver1作为slaver2的master,这样以来就直接串连起来。但注意,如果slaver1出现问题,slaver2就无法进行消息的复制。

2.5.6 反客为主

如果master挂掉,那么slaver就会变成master【手动】slaveof no one- 1
127.0.0.1:6380> info replication # Replication role:slave master_host:127.0.0.1 master_port:6381 master_link_status:down master_last_io_seconds_ago:-1 master_sync_in_progress:0 slave_read_repl_offset:4817 127.0.0.1:6380> slaveof no one OK 127.0.0.1:6380> info replication # Replication role:master connected_slaves:0 master_failover_state:no-failover master_replid:ffc0b52b77203b169b1e8bb02a0f28463fe6ee46 master_replid2:8cea75e4638b6a2cd625c2ff5c64c69e7545714c- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.5.7 哨兵模式(sentinel)
- 什么是哨兵模式?
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将库转换为主库

- 配置哨兵模式
-
新建一个sentinel.conf文件(文件名绝对不能错)
-
配置哨兵模式
# mymaster为监控对象起的服务器名称,1为至少有多少个哨兵同意迁移的数量 sentinel monitor mymaster 127.0.0.1 6379 1- 1
- 2
-
启动哨兵
redis-sentinel sentinel.conf- 1
-
当主机挂掉,从机选举中产生新的主机
(大概10秒钟左右会看到哨兵窗口日志,切换了新的主机)
哪个主机会被选举为主机呢?根据优先级别:slave-priority
原主机重启就会变成从机,下面就是master(6381)出错,然后slaver(6379)被哨兵选作为新的master,然后将(6380)作为(6379)的slaver。127.0.0.1:6379> info replication # 带等一会就好了 Error: Broken pipe 127.0.0.1:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6380,state=online,offset=20290,lag=0 master_failover_state:no-failover- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
127.0.0.1:6380> info replication # 出现这个错误等一会儿就好了 Error: Broken pipe 127.0.0.1:6380> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.5.8 复制延时
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使得这个问题更加严重。
2.5.9 主机选择规则

- 优先级在redis.conf中默认:replica-priority 100 值越小优先级越高
- 偏移量是指获得原主机数据最全的
- 每个redis实例启动后都会随机生成一个40位的runid
2.6 Redis集群
2.6.1 问题
- 容量不够,redis如何进行扩容?
- 并发写操作,redis如何分摊?
- 另外主从模式、薪火相传模式,主机宕机导致ip地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息。之前通过代理主机来解决,但是在redis3.0中提供了解决方案。就是无中心化集群配置。


2.6.2 什么是集群?
- Redis集群实现了对Redis的水平扩容,即启动N个Redis节点,将整个数据库分布存储在N个结点中,每个节点存储数据的1/N;
- Redis集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求;
2.6.3 删除持久化数据
将rdb、aof文件都删除掉
2.6.4 制作集群实例⭐️
这6个实例的端口分别是:6379、6380、6381、6389、6390、6391
-
配置基本信息
- 开启daemonize yes
- Pid 文件名字
- 指定端口
- Log文件名字
- dump.rdb 名字
- appendonly guan关掉或者换名字
-
redis cluster配置修改
-
cluster-enabled yes 打卡集群模式
-
cluster-config-file nodes-6379.conf 设置节点配置文件名
-
cluster-node-timeout 15000 设定节点关联时间,超过该时间(毫秒),集群自动进行主从切换
配置文件的大致信息如下:include /home/bigdata/redis.conf port 6379 pidfile /var/run/redis_6379.pid dbfile dump6379.rdb dir /home/bigdata/redis_cluster logfile /home/bigdata/redis_cluster/redis_err_6379.log cluster-enabled yes cluster-config-file nodes-6379.conf cluster-node-timeout 15000- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在vim中的一个操作技巧:将指定的部分替换可以使用以下命令:%s/6379/6389
-
最终启动所有的服务
MacBook-Pro ~ % ps aux | grep redis 3844 0.0 0.0 408940096 2016 s002 S+ 3:09下午 0:00.25 redis-server 127.0.0.1:6389 [cluster] 3815 0.0 0.0 408790592 2016 ?? S 3:08下午 0:00.31 redis-server 127.0.0.1:6380 [cluster] 3746 0.0 0.0 408781376 2000 ?? S 3:06下午 0:00.39 redis-server 127.0.0.1:6379 [cluster] 4002 0.0 0.0 408626880 1296 s004 S+ 3:14下午 0:00.00 grep redis 4000 0.0 0.1 408930880 4672 s001 S+ 3:14下午 0:00.01 redis-server 127.0.0.1:6391 [cluster] 3970 0.0 0.1 408930880 4704 s000 S+ 3:14下午 0:00.03 redis-server 127.0.0.1:6390 [cluster] 3938 0.0 0.1 408790592 4384 s003 S+ 3:13下午 0:00.06 redis-server 127.0.0.1:6381 [cluster]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
-
合体
- 切换到自己安装redis的目录
cd /usr/local/bin/- 1
- 使用一下命令进行合体
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6389 127.0.0.1:6390 127.0.0.1:6391- 1
此命令中,尽量不要用127.0.0.1,要用真实的IP地址。但是如果你的真实ip无法找到,报错connect refuse则可以再尝试使用127.0.0.1 --replices 1采用最简单的方式配置集群,一台主机,一台从机,正好三组- 1
- 2

-
查看节点信息
# 集群中任意一个端口都可以进去 redis-cli -c -p 6379- 1
- 2
# 查看集群信息 127.0.0.1:6379> cluster nodes b92fb808235845755a5bf7b0efb4d243732641cd 127.0.0.1:6391@16391 slave f3d761edcb54bc8c4315748e4a7766a3c52ef791 0 1669621253796 3 connected 724d45a2f2afb7c4384d0f2a2dc8ebf4e90a9b19 127.0.0.1:6389@16389 slave b0294ee276b22b7d11ae0c404d55b86d7efe104a 0 1669621252785 1 connected 03f22e7b1c9c6f14aa4497369ffb92d3f6dab5d1 127.0.0.1:6390@16390 slave 6468a7f8491a2b4c4c753dcff4296ce2ed343287 0 1669621252000 2 connected 6468a7f8491a2b4c4c753dcff4296ce2ed343287 127.0.0.1:6380@16380 master - 0 1669621252000 2 connected 5461-10922 b0294ee276b22b7d11ae0c404d55b86d7efe104a 127.0.0.1:6379@16379 myself,master - 0 1669621251000 1 connected 0-5460 f3d761edcb54bc8c4315748e4a7766a3c52ef791 127.0.0.1:6381@16381 master - 0 1669621253000 3 connected 10923-16383- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.6.5 Redis Cluster如何分配节点?
一结点至少要有三个主结点。选项–cluster-replicas 1表示我们希望为集群中的每个主结点创建一个从结点。分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上
2.6.6 什么是slot?
[OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.- 1
- 2
- 3
- 4
一个Redis集群包含16384个插槽(hash slot),数据库中的每个键都属于这个16384个插槽的其中一个,集群使用公式CRC16(key)%16384来计算键key属于哪个槽,其中CRC16(key)语句用于计算键key和CRC16校验和。集群中的每个节点负责处理一部分插槽。举个例子,如果一个集群可以有主结点,其中节点A负责0号至5460号插槽。

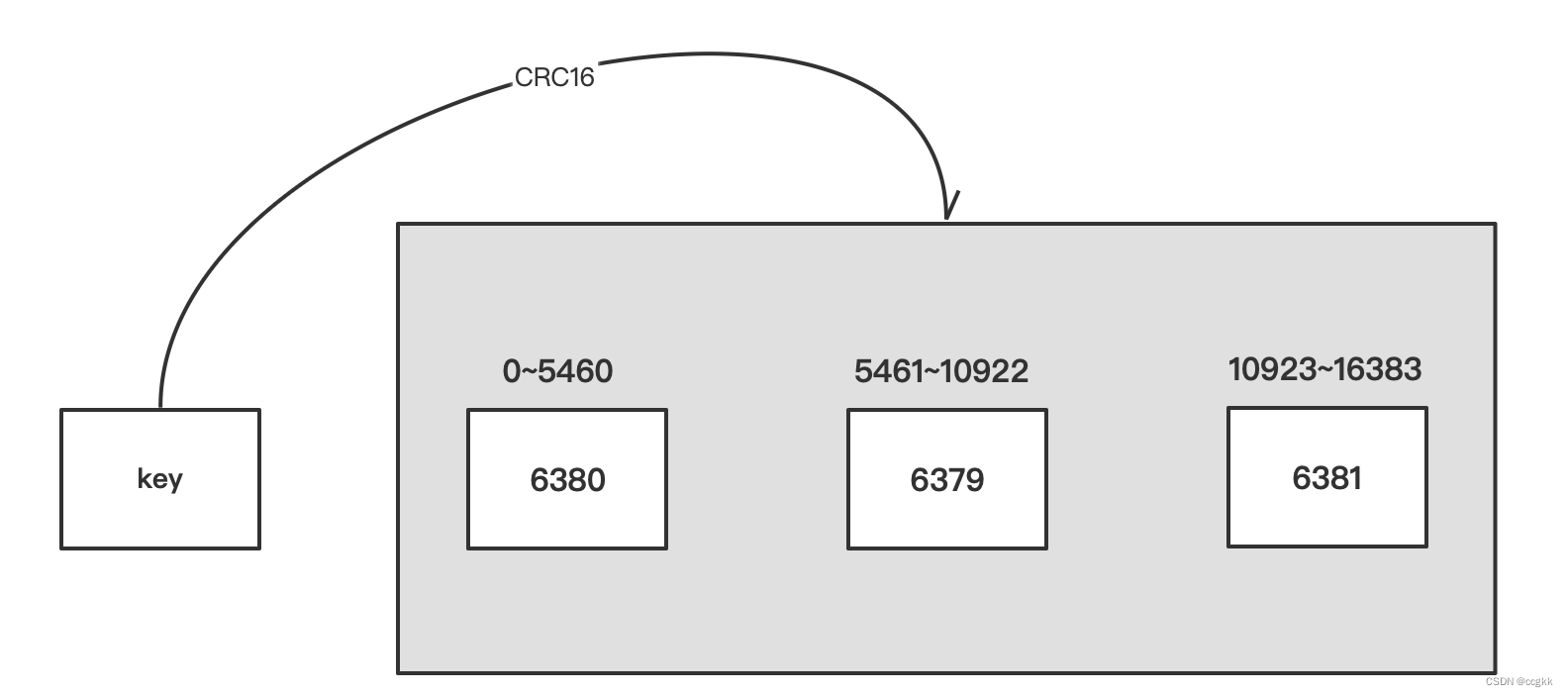 这个地方的一个简单理解就是将key能够平均得分配到集群当中去。下面11.7的实际案列能够更加清晰得理解。
这个地方的一个简单理解就是将key能够平均得分配到集群当中去。下面11.7的实际案列能够更加清晰得理解。2.6.7 在集群中录入值?
- 插入单个值
127.0.0.1:6379> set name kevin -> Redirected to slot [5798] located at 127.0.0.1:6380 OK- 1
- 2
- 3
- 插入多个值
127.0.0.1:6380> mset name{user} tom age{user} 10 OK- 1
- 2
- 查询集群中的值
# 计算name键对应的slot值 127.0.0.1:6380> cluster keyslot name (integer) 5798 # 计算5798中有多少个值 127.0.0.1:6380> cluster countkeysinslot 5798 (integer) 1 127.0.0.1:6380> cluster getkeysinslot 5798 1 1) "name"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.6.8 故障恢复
-
如果住结点下线?从结点能否自动升为主结点?注意:15秒超时

-
主结点恢复后,主从关系如何?主结点回来变成从机

-
如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?这个取决于自身的配置。如果某一段插槽的主从都挂掉,cluster-require-full-coverage为yes,那么,整个集群都挂掉。如果cluster-require-full-coverage为no那么该插槽数据全部不能使用,也无法存储。redis.conf中的参数cluster-require-full-coverage
2.6.9 使用集群的好处
- 实现扩容;
- 分摊压力;
- 无中心配置相对简单;
2.6.10 使用集群的不足
- 多键操作是不被支持;
- 多键的Redis事务是被支持的。lua脚本不被支持;
- 由于集群方案出现晚,很多公司已经采用了其他集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
第三天
3.1 应用问题解决
3.1.1 缓存穿透
- 现象
- redis查询不到数据库;
- 出现很多非正常 url访问;
- 原因
- 应用服务器压力变大了;
- redis命中率降低了;
- 一致查询数据库;
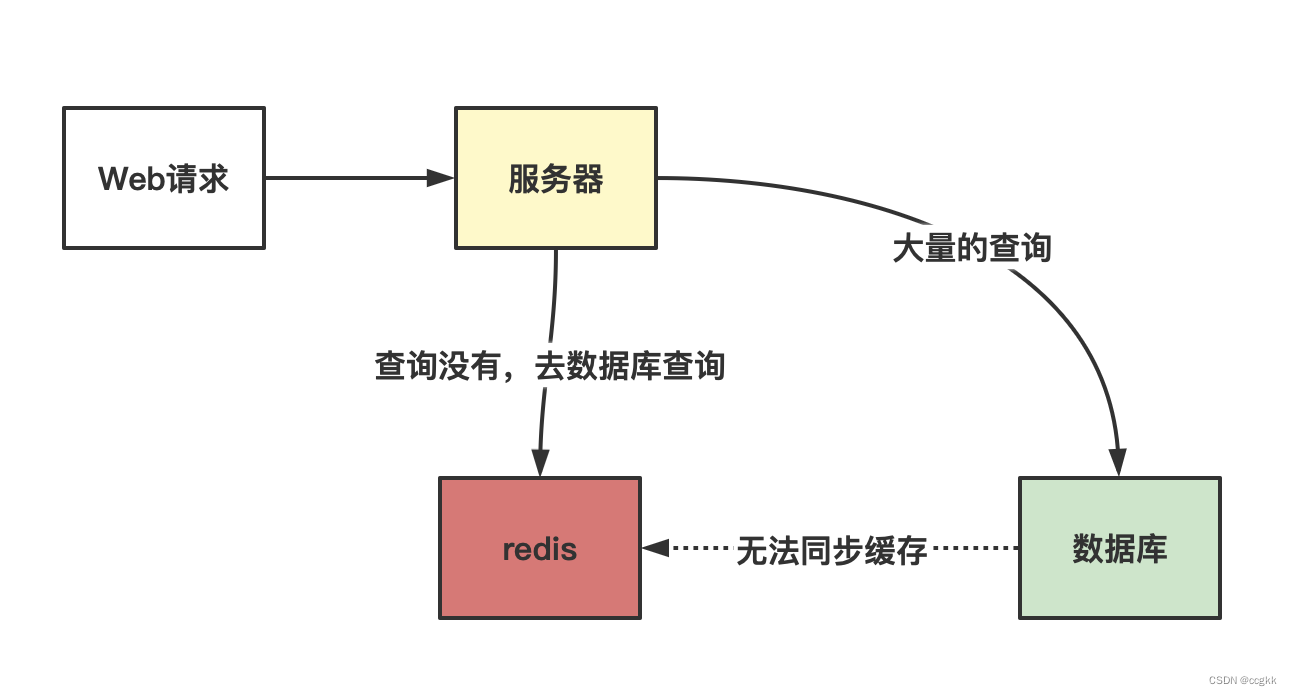
- 解决方案
- 对空值缓存:如果一个查询返回的数据为空(不管数据是否存在),我们任然把这个结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过五分钟;
- 设置可访问的名单(白名单):使用bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmaps里面的id进行比较,如果访问的id不再bitmaps里面,进行拦截,不允许访问;
- 采用布隆过滤器:(布隆过滤器Bloom Filter)是1970年由布隆提出的。他实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数);
- 进行实时监控:当发现Redis的命中率开始极速下降,需要排查访问对象和访问数据,和运维人员配合,可以设置黑名单限制服务;
3.1.2 缓存击穿
- 问题描述
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大量并发可能会瞬间把后端DB压垮。

- 原因
- 数据库访问瞬时增加;
- redis没有没有出现大量key过期;
- redis正常运行;
- redis某个key过期了,大量访问使用这个key
- 解决方案
key可能会在某些时间点被超高并发访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。- 预先设置热门数据:在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长;
- 实时调整:现场监控哪些数据热门,实时调整key的过期时长
- 使用锁:
(1)就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db;
(2)先使用缓存工具的某些带成功操作返回值的操作(比如redis的SETNX);
(3)当操作返回成功时,再load db的操作,并回设缓存,最后删除mutex key;
(4)当操作返回失败,证明有线程在load db,当线程睡眠一段时间再重试get缓存的方法;
3.1.3 缓存雪崩
- 问题描述
- key对应的数据存在,但在redis中过期,此时,若有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发请求可能会瞬间把后端DB击穿。
- 在极少时间段,查询大量key的集中过期情况。
- 缓存雪崩与缓存击穿的区别在于这里针对很多key缓存,前者是某一个key,其他都正常访问。

- 解决方案
- 构建多级缓存架构:nginx缓存+redis缓存+其他缓存(ehcache等)
- 使用锁或消息队列:用加锁或者队列的方式来保证不会有大量的线层对数据库一次性进行读写,从而避免失效时大量并发请求落到底层存储系统上。不适用高并发情况。
- 设置过期标志:记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
- 将缓存失效时间分散开:比如我们可以在原有的失效时间基础上加一个随机值,比如1-5分钟随机,这样每一个缓存过期时间的重复率就会降低,就很难引发集体失效的事件。
3.2 分布式锁
3.2.1 问题描述
- 随着业务发展,原单体单机部署的系统被演化称分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同的机器上,这将使远单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨jvm的互斥机制来控制共享资源的访问,这就是分布式锁需要解决的问题!
- 分布式锁主流的实现方案:
- 基于数据库实现分布式锁;
- 基于缓存(Redis等);
- 基于ZooKeeper;
- 分布式锁主流的实现方案:
- 性能:redis最高;
- 可靠性:zookeeper最高;
这里,我们就基于redis实现分布式锁
3.2.2 解决方案:使用redis实现分布式锁
redis:命令
# EX second:设置键的过期时间为second秒。 # SET key value EX second 效果等同于SETEX key second value- 1
- 2
- 3
- 设置锁
setnx <key><value>- 1
- 手动释放锁
del <key>- 1
- 自动释放锁
setnx <key><value> # 到期后自动释放 expire <key> <time>- 1
- 2
- 3
- 上锁后突然出现异常,无法设置过期时间
# EX second:设置键的过期时间为second秒。 # SET key value EX second 效果等同于SETEX key second value # 上锁的同时设置过期时间 set <key><value> NX EX 10000- 1
- 2
- 3
- 4
3.2.3 UUID防误删
自己只能删除自己的锁,不能删除别人的锁。
- 第一步 uuid表示不同的操作
set lock uuid nx ex 10- 1
- 第二步 释放锁的时候,判断当前uuid和要释放锁uuid是否一样

3.2.3 原子性操作

简单来说,就是一个有一个服务器在要删除但是还没有删除锁的时候,锁到期了,自动释放了,然后另一个服务器又拿到这个锁开始操作,因此丧失了原子性。同时为了保证分布式锁可用性,需要满足一下四个条件:- 互斥性。在任意时刻,只有一个客户端能持有锁;
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动释放解锁,也能保证后续其他的客户端能加锁;
- 解铃还需系铃人。加锁与解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
- 加锁和解锁必须具有原子性能。
3.3 Redis6新功能
3.3.1 ACL
- 简介
Redis ACL是Access Control List(访问控制列表)的缩写,该功能允许根据可以执行的命令和可以访问的键来限制某些连接。在Redis 5版本之前,Redis安全规则只有密码控制还有通过rename来调整高危命令比如flushdb、keys *、shutdown等。Redis 6 则提供ACL的功能对用户进行更细粒度的权限控制:- 接入权限:用户名和密码
- 可以执行的命令
- 可以操作的key
- ACL命令
-
查看用户权限列表
acl list- 1

-
acl cat
# 查看自己能够使用哪些命令 acl cat # 查看当前用户 acl whoami- 1
- 2
- 3
- 4
-
使用sclsetuser命令创建和编辑用户ACL
# 通过命令创建新用户默认权限:没有使用任何规则 # 如果用户不存在,就just create;如果用户已经存在,则上面命令将不执行任何操作 acl set user1 # 设置用户名、密码、ACL权限、并启用用户 # 只能在对cache开头的key进行get操作 acl set user2 on > password ~cached:* +get # 切换用户 auth username password- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
3.3.2 IO多线程
- 简介
IO多线程其实指的客户端交互部分的网络IO交互处理模块多线程,而非执行命令多线程。Redis6执行命令依然是单线程。默认不开启,需要在配置文件中进行配置才可以使用:io-thread-do-reads yes io-threads 4- 1
- 2
3.3.3 工具支持Cluster
之前老版Redis想要搭建集群需要单独安装ruby环境,Redis 5将redis-trib.rb的功能集成到redis-cli。另外官方redis-benchmark工具开始支持cluster模式了,通过多线程的方式对多个分布进行压测。
- NoSql概述
-
相关阅读:
Redis源码(1) 建立监听服务和开启事件循环
【ESD专题】金属外壳连接器的信号PIN脚需要进行ESD测试吗?
第7章 - 多无人机系统的协同控制 --> 实验验证
论文解读(GROC)《Towards Robust Graph Contrastive Learning》
【华为上机真题 2022】流水线
前后端分离项目,vue+uni-app+php+mysql订座预约小程序系统设计与实现
WireShark 常用协议分析
Socks5代理IP在网络安全、跨境电商和游戏中的应用
MacBook Pro(M1 Pro芯片)兼容Tensorflow1.X版本的解决方法
2013年11月10日 Go生态洞察:Go语言四周年回顾
- 原文地址:https://blog.csdn.net/weixin_43495948/article/details/128092387
