-
1. Unified Structure Generation for Universal Information Extraction 阅读笔记
Author Information:

Institutions Information:
1 Chinese Information Processing Laboratory
2State Key Laboratory of Computer Science Institute of Software, Chinese Academy of Sciences, Beijing, China
3 Baidu Inc., Beijing, China
4 University of Chinese Academy of Sciences, Beijing, China
5 Beijing Academy of Artificial Intelligence, Beijing, China
目录
2. Unified Structure Generation for Universal Information Extraction
2.1 Structural Extraction Language for Uniform Structure Encoding
2.2 Structual Schema Instructor for Controllable IE Structure Generation
2.2.1 Structual Schema Instructor (结构模式指导器)
2.2.2 Structure Generation with UIE (使用UIE生成结构)
3. Pre-training and Fine-tuning for UIE
3.1 Pre-training Corpus Construction +3.2 Pre-training
4.2 Experiments on Low-resource Settings
4.3 Ablations on Pre-training Tasks
Abstract
信息提取具有不同的目标、异构结构和需求特定的模式。在本文,作者们提出了一个统一的文本到结构(text-to-structure)的生成框架,即UIE。其可以普遍的建模不同的信息抽取任务,自适应的生成目标结构,并且可以从不同的知识源(different knowledge sources)中协作学习一般的信息抽取能力。
具体的,UIE通过结构化抽取语言SEL(Structured extraction language)统一的编码不同的抽取结构,通过基于模式的提示机制(schema-based prompt mechanism)结构模型指导器 SSI(structural schema instructor)自适应的生成目标提取,并通过大规模预训练的文本到结构模型捕获常见的信息抽取能力。
在4个IE任务(entity, relation, event and sentiment extraction tasks)的13个数据集上进行了监督、低资源、小样本实验,验证,取得了SOTA性能。这些结果验证了UIE的有效性 (effectiveness)、普遍性 (universality)和可转移性(transferability)。
1. Introduction
当前,大多数的IE方法是基于特定任务的,这将会导致对于不用的IE人物而言,需要专用的框架,独立的模型,特定化的知识源。这些专门化任务的解决方案极大地阻碍了IE系统的快速架构开发、有效的知识共享和快速的跨领域适应。(1)首先,为大量的IE任务/设置/场景开发专用的架构是非常复杂的。(2)第二,学习孤立的模型严重限制了相关任务和设置之间的知识共享。(3)最后,构建专门用于不同IE任务的数据集和知识源是非常昂贵和耗时的。
因此,开发一个通用的IE体系结构,可以统一地建模不同的IE任务,自适应地预测异构结构,并有效地从各种资源中学习,这将是非常有益的,我们称之为通用IE (Universal IE)。
从根本上来说,所有的IE任务都可以被建模为从文本到结构的转换,不同的任务对应不同的结构。IE中的这些文本到结构的转换可以进一步分解为几个原子转换操作 (atomic transformation operations):
Spotting (定位):在输入的原句中定位到目标信息片段。例如在给定Entity PER的时候,要定位到“Steve”定位,给定sentiment expression要定位到“excited”;
Associating (关联):指找出Spotting输出的信息片段之间的关系。例如,把“Steve”和“Apple”分配为关系“work for”的参数1和参数2,也就头实体和尾实体。
通过这种方式,不同的IE任务可以分解为一系列原子文本到结构的转换,所有IE模型共享相同的底层发现和关联能力。

- 为了对异构IE结构进行建模,论文设计了一种结构提取语言(SEL),该语言可以有效地将不同的IE结构编码为统一的表示,从而可以在相同的文本到结构生成框架中对各种IE任务进行通用建模。
- 为了自适应地为不同的IE任务生成目标结构,论文提出了结构模式指导器(SSI),这是一种基于模式的prompt机制,用于控制UIE中要发现的内容、要关联的内容以及要生成的内容。
通过这两种转化,就可以将上图中的(a)转换成图(b)
本文的贡献点:
1)我们提出UIE,一个通用的文本到结构的生成架构,可以自动的编码不同的IE任务,自适应的生成目标结构,并从不同的知识源协作学习(collaboratively learn)一般的IE的能力
2)我们设计了一个通用的结构生成网络,通过结构提取语言将异构(heterogeneous)的IE结构编码为统一的表示,并控制UIE模型哪些spot, 哪些associate哪些生成。
3)我们通过统一的预训练算法对大规模文本结构生成模型进行预训练。据我们所知,这是第一个文本到结构的预训练提取模型,它可以有利于未来的IE研究。
2. Unified Structure Generation for Universal Information Extraction
核心思想:
给定SSI和文本X,作为输入,UIE会通过Encoder-Decoder结构生成SEL。
2.1 Structural Extraction Language for Uniform Structure Encoding
2.1节主要描述怎样将异构的IE结构编码成通用的表示方式。具体通过Spotting和Associating两个步骤。
- 第一步是做定位(Spotting)。在输入的原句中定位到目标信息片段。
- 第二步是做关联(Associating)。指找出Spotting输出的信息片段之间的关系。
structured extraction language (SEL)将异构IE结构编码为统一的表示,每个SEL表达式包含三种类型的语义单元,示例如下图:

Spot Name: 指目标信息片段的类别,在实体抽取中指实体类别,在事件抽取中可以指事件类型和论元类别。
Info Span: Spotting操作(原句中定位到目标信息片段)的输出,即原句子中的目标信息片段。
Asso Name: 指两个信息片段之间的关系类型,也就是Associating操作(Spotting输出的信息片段之间的关系)的输出。给定一个样本实例:Steve became CEO of Apple in 1997.
进行关系抽取、事件抽取、命名实体识别就可以统一的生成如下结构:

2.2 Structual Schema Instructor for Controllable IE Structure Generation
本文提出了结构模式指导器(SSI),这是一种基于模式(schema)的提示(prompt)机制,用于控制不同的生成需求:在Text前拼接上相应的Schema Prompt,输出相应的SEL结构语言。
针对四个不同的IE任务,不同任务的形式是:
- 实体抽取:[spot] 实体类别 [text]
- 关系抽取:[spot] 实体类别 [asso] 关系类别 [text]
- 事件抽取:[spot] 事件类别 [asso] 论元类别 [text]
- 观点抽取:[spot] 评价维度 [asso] 观点类别 [text]

所以,UIE的整体框架为:

形式上,UIE将给定的结构模式指导器SSI(s)和文本序列(x)作为输入,并生成采用SEL语法描述的结构化数据(y),其中包含基于模式s从x中提取的信息:

2.2.1 Structual Schema Instructor (结构模式指导器)
为了描述任务的提取目标,Structural Schema Instructor(SSI)构建了一个基于模式的提示(schema-based prompt),并在生成过程中将其用作前缀。包含三种类型的token:
- SPOTNAME:信息提取任务中的目标定位名称。如NER任务中的“person”
- ASSONAME:目标关联名称。如关系提取任务中的“work for”;
- Special Symbols([spot], [asso],[text]):分别添加在每个spot name、association name和文本序列前面添加。
SSI中的所有标记都被连接起来,并放在原始文本序列之前。如下图所示:
s ⨁ x = [ s 1 , s 2 , . . . , s | s | , x 1 , x 2 , . . . , x x ] = [ [ s p o t ] , . . [ s p o t ] . . . , [ a s s o ] , . . . , [ a s s o ] . . . , [ t e x t ] , x 1 , x 2 , . . . , x x ] " role="presentation">2.2.2 Structure Generation with UIE (使用UIE生成结构)
所谓UIE模型,本质上是一个标准的Transformer,包含了Encoder和Decoder。首先将SSI信息和句子拼接(其中
 是SSI信息,
是SSI信息,  是句子),输入至Encoder,得到每一个token的隐藏层表示:
是句子),输入至Encoder,得到每一个token的隐藏层表示:
接下来,使用隐藏层表示在Decoder端生成目标结构化信息,如下面的公式:

(在解码的步骤 i中 ,UIE生成SEL序列中的第 i 个token
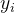 和解码器状态
和解码器状态 )
)3. Pre-training and Fine-tuning for UIE
3.1 Pre-training Corpus Construction +3.2 Pre-training
生成任务是不可控,如果生成的信息结构不符合前面定义的结构,那怎样抽取信息呢?作者通过了定义不同的损失避免的这种情况。
UIE预训练语料主要来自Wikipedia、Wikidata和ConceptNet,构建了3种预训练数据(20210401version的Wikipedia and Wikidata dump and ConceptNet, 具体细节部分可参考附录A.1),并分别构造3种预训练任务,将大规模异构数据整合到一起进行预训练:
其一:
D_pair: 是一个文本-结构的并行数据。通过Wikipedia对齐Wikidata,构建text-to-structure的平行语料,数据表示为(s,x,y)
Text-to-Structure Pre-training:每个实例都是一个并行对(token序列x,结构化记录y), D_pair 是用于预训练UIE的文本到结构映射能力。预训练时随机取样一些负例(spots、association)作为噪声训练(引入negative schema)。
作者发现如果在生成的token中,加个损失,用来判断当前token是不是spotting或者是不是associating效果会变好。
这里的正样本就是spotting或者assocating,负样本则是随机抽取的token。损失如下:

其二:
D_record: 是一个结构数据集,其中每个实例都是结构化记录 y(None,None,y)
Structure Generation Pre-training:为了具备SEL语言的结构化能力,这部分输入只有结构化数据record,输入前面的部分,使其生成剩余部分,并且只训练UIE的decoder部分,使其学会SEL语法。
D_record是用来预训练UIE的结构decoding能力。
这个损失就是生成任务中,自回归的一个损失。用于预训练UIE的结构解码能力,损失如下所示:

其三:
为了提高UIE的语义表示,作者还加了MLM(Masked Language Model)任务。用于预训练UIE的语义编码能力,可以有效地缓解token语义的灾难性遗忘,尤其是在SPOTNAME和ASSONAME token上。。损失如下:
D_text: 是一个无结构化的原始文本数据集。论文使用英文维基百科中的所有纯文本,构造无结构的原始文本数据:(None,x'(破坏过的源文本),x''(破坏的目标spans))
Retrofitting Semantic Representation:为了具备基础的语义编码能力,对D_text数据进行 span corruption训练。这部分做的是无监督的masked language model任务,和T5中的预训练任务一样,在原始句子中MASK掉15%的tokens,然后生成MASK的部分,输入中已经呈现的部分输出MASK。
D_text:用来预训练UIE的语义解码(semantic encodiing)能力。

最后将这三种损失相加,进行大规模的预训练:

值得注意的是,作者并不是分开做这三个预训练任务的,而是将其统一化,全部表示为三元组 (s,x,y),其中 s 是加在输入句子前面的prompt,x 是输入的原始句子,y 是需要生成的目标句子,在每一个batch中随机抽取每一个任务的数据去训练。Dpair 数据表示为 (s,x,y),Drecord 数据表示为 (None,None,y),Dtext 数据表示为 (None,x′,x″),这样无论是哪种任务都是输入一个三元组,即可统一训练。
3.3 On-Demand Fine-tuning
微调部分和预训练任务的 Dpair 类似,数据形式是 (s,x,y),微调的Loss计算方式如式 (9) 所示。

如下表所示,微调部分依然加入了负样本,下部分第二行加入了负样本,随机插入一些原标签中没有的信息,输入句子中并没有facility的实体,而标签中插入了 (facility: [NULL])。

拒绝机制(RM)的一个示例,此处“(facility:[NULL])是学习阶段注入的拒绝噪声,推理阶段将忽略[NULL]值范围。
4. Experiment
4.1 Main Results
本文在13个IE基准上进行了实验,涉及4个很有代表性的IE任务(包括实体提取、关系提取、事件提取、结构化情感提取)及其组合(例如,联合实体-关系提取)。结果如下:

最右边的SEL列是指基于T5-v1.1-large进行微调得到的结果(没有预训练的UIE模型),UIE是指基于UIE-large进行微调的结果,可以看到几乎在全部数据集上都取得了SOTA的结果,但是通过对比SEL和UIE发现预训练部分对结果的提升并不大,通过这个可以看出作者设计的SEL语法和SSI还是很强大的,另一方面也说明T5本身的生成能力就很强大。
4.2 Experiments on Low-resource Settings
另外,作者也给除了few-shot的效果,如下:

UIE真正强大的地方是小样本情况下,泛化能力非常强,远超基于T5的微调结果,在全监督设置下预训练部分的能力没有体现出来,但在低资源下针对性的预训练可以非常好的提升泛化能力。
4.3 Ablations on Pre-training Tasks

5. Related Work
此处不赘述,感兴趣的可以自己看论文哈。
6. Conclusion
在本文中,我们提出了一个统一的文本到结构的生成框架——UIE,它可以普遍地建模不同的IE任务,自适应地生成目标结构,并无畏地从不同的知识源学习一般的IE能力。实验结果表明,UIE在监督环境和低资源环境下都取得了非常具有竞争力的性能,验证了它的普遍性、有效性和可转移性。同时还发布了一个大规模的预先训练的文本到结构模型,这将有利于未来的研究。对于未来的工作,我们希望将UIE扩展到kb感知 (KB-aware)的IE任务,如实体链接,以及文档软件的IE任务,如共同引用(co-reference)。
参考:
UIE:Unified Structure Generation for Universal Information Extraction
-
相关阅读:
竞争与冒险 毛刺
lammps教程:CNA晶体结构分析命令
Kubernetes(K8S第三部分之资源控制器)
docker 安装 gitlab 访问不了
【Redis学习笔记】第六章 Redis持久化
解决QT的无界面程序,Ctrl+C无法触发析构函数的问题
【Docker】Dockerfile使用技巧
为什么删除Windows 11上的Bloatware可以帮助加快你的电脑速度
朴素贝叶斯(基于概率论)
《HTML+CSS+JavaScript》之第3章 基本标签
- 原文地址:https://blog.csdn.net/weixin_41862755/article/details/128068490