-
Redis实战篇(五)好友关注
1、点赞 ------------ Set
2、点赞排行 ------SortedSet
3、共同关注 -------set sinter一、共同关注
@Override public Result followCommons(Long id) { // 1.获取当前用户 Long userId = UserHolder.getUser().getId(); String key = "follows:" + userId; // 2.求交集 String key2 = "follows:" + id; Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2); if (intersect == null || intersect.isEmpty()) { // 无交集 return Result.ok(Collections.emptyList()); } // 3.解析id集合 List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList()); // 4.查询用户 List<UserDTO> users = userService.listByIds(ids) .stream() .map(user -> BeanUtil.copyProperties(user, UserDTO.class)) .collect(Collectors.toList()); return Result.ok(users); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
二、关注推送(Feed流)
关注推送也叫Feed流,直译为投喂。为用户持续的提供沉浸式的体验,通过无限下拉刷新获取新的信息。
TimeLine 智能排序 定义 不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注 利用智能算法屏蔽违规的、用户不感兴趣的内容 优点 信息全面,不会有缺失。并且实现也相对简单 投喂用户感兴趣信息,用户粘度很高 缺点 信息噪音很多,用户不一定感兴趣,内容获取效率低 如果算法不精准,可能起到反效果 1、Feed流的实现方式



拉模式 推模式 推拉结合 写比例 低 高 中 读比例 高 低 中 用户读取延迟 高 低 低 实现难度 复杂 简单 很复杂 使用场景 很少使用 用户量少,没有大V 过千万的用户量,有大V 2、Feed分页问题
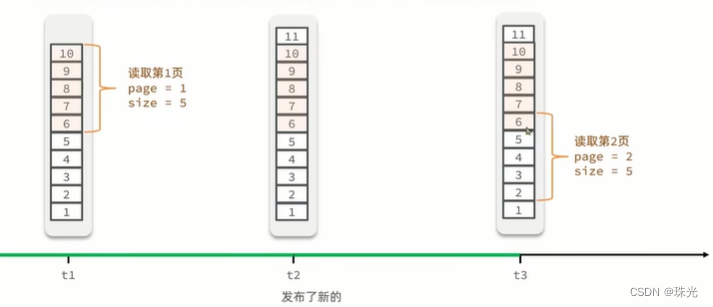
Feed流中的数据会不断更新,所以数据的角标也在变化,因此不能采用传统的分页模式。采用滚动分页。

推送粉丝收件箱@Override public Result saveBlog(Blog blog) { // 1.获取登录用户 UserDTO user = UserHolder.getUser(); blog.setUserId(user.getId()); // 2.保存探店笔记 boolean isSuccess = save(blog); if(!isSuccess){ return Result.fail("新增笔记失败!"); } // 3.查询笔记作者的所有粉丝 select * from tb_follow where follow_user_id = ? List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list(); // 4.推送笔记id给所有粉丝 for (Follow follow : follows) { // 4.1.获取粉丝id Long userId = follow.getUserId(); // 4.2.推送 String key = FEED_KEY + userId; stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis()); } // 5.返回id return Result.ok(blog.getId()); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
(3)滚动分页
滚动分页:
max:当前时间戳 | 上一次查询的最小时间戳
min:0
offset : 0 | 在上一次的结果中,与最小值一样的元素个数
count: 5@Data public class ScrollResult { private List<?> list; private Long minTime; private Integer offset; }- 1
- 2
- 3
- 4
- 5
- 6
@Override public Result queryBlogOfFollow(Long max, Integer offset) { // 1.获取当前用户 Long userId = UserHolder.getUser().getId(); // 2.查询收件箱 ZREVRANGEBYSCORE key Max Min LIMIT offset count String key = FEED_KEY + userId; Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet() .reverseRangeByScoreWithScores(key, 0, max, offset, 2); // 3.非空判断 if (typedTuples == null || typedTuples.isEmpty()) { return Result.ok(); } // 4.解析数据:blogId、minTime(时间戳)、offset List<Long> ids = new ArrayList<>(typedTuples.size()); long minTime = 0; // 2 int os = 1; // 2 for (ZSetOperations.TypedTuple<String> tuple : typedTuples) { // 5 4 4 2 2 // 4.1.获取id ids.add(Long.valueOf(tuple.getValue())); // 4.2.获取分数(时间戳) long time = tuple.getScore().longValue(); if(time == minTime){ os++; }else{ minTime = time; os = 1; } } // 5.根据id查询blog String idStr = StrUtil.join(",", ids); List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list(); // 6.封装并返回 ScrollResult r = new ScrollResult(); r.setList(blogs); r.setOffset(os); r.setMinTime(minTime); return Result.ok(r); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
-
相关阅读:
SQL排序函数详解+案例实战
这篇spring事务理解透了,工资直接涨10K
1236 - 二分查找
ava面试八股文-基础概念二
Day10_Git版本控制、项目总结,preview_220627,
spark集群搭建
微服务设计模式
顶级AI工具大盘点!
Linux脚本之监控系统内存使用情况并给予警告
【保姆级图文教程】QT下载、安装、入门、配置VS Qt环境
- 原文地址:https://blog.csdn.net/qq_38618691/article/details/127888852
