-
第七章第三节:散列表(Hash Table)
教程
- 散列表(Hash Table)https://www.bilibili.com/video/BV1b7411N798/?p=75&share_source=copy_web&vd_source=d228985826b563972268952905224139
- 散列表(Hash Table) https://www.bilibili.com/video/BV1b7411N798/?p=76&share_source=copy_web&vd_source=d228985826b563972268952905224139
1. 散列表(Hash Table)
1.1 散列表的基本概念
散列表(Hash Table),又称哈希表。是一种数据结构,特点是︰数据元素的关键字与其存储地址直接相关


查找成功:


查找失败






装填因子会直接影响散列表的查找效率
1.2 散列函数的构造方法
在构造散列函数时,必须注意以下几点:
- 散列函数的定义域
必须包含全部需要存储的关键字,而值域的范围则依赖于散列表的大小或地址范围。 - 散列函数计算出来的地址应该能等概率、均匀地分布在整个地址空间中,从而减少冲突
的发生。 - 散列函数
应尽量简单,能够在较短的时间内计算出任一关键字对应的散列地址。
下面介绍常用的散列函数。
1.2.1 除留佘数法

质数又称素数。指除了1和此整数自身外,不能被其他自然数整除的数
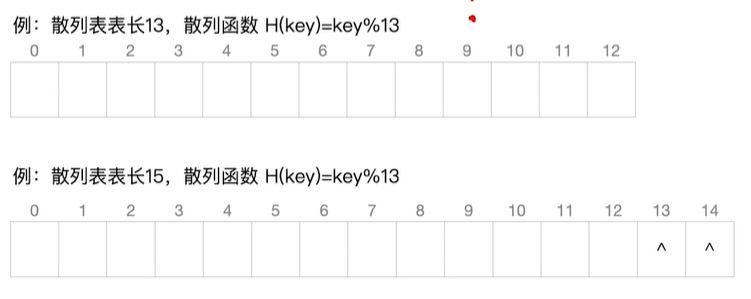
以上两个散列函数的p值相同,第二个散列表的13和14基本上就给舍弃了,这样的设计目标――
让不同关键字的冲突尽可能地少
1.2.2 直接定址法

例如:
1.2.3 数字分析法
数字分析法——
选取数码分布较为均匀的若干位作为散列地址.设关键字是r进制数(如十进制数),而
r个数码在各位上出现的频率不一定相同,可能在某些位上分布均匀一些,每种数码出现的机会均等﹔而在某些位上分布不均匀,只有某几种数码经常出现,此时可选取数码分布较为均匀的若干位作为散列地址。这种方法适合于已知的关键字集合,若更换了关键字,则需要重新构造新的散列函数。举例:

1.2.4 平方取中法
平方取中法――
取关键字的平方值的中间几位作为散列地址。
具体取多少位要视实际情况而定。这种方法得到的散列地址与关键字的每位都有关系,因此使得散列地址分布比较均匀,适用于关键字的每位取值都不够均匀或均小于散列地址所需的位数。



1.3 处理冲突的方法
1.3.1 拉链法

1.3.2 开放定址法

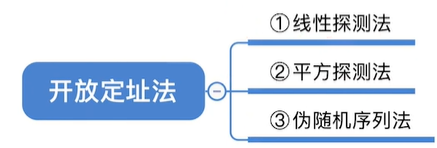
1.3.2.1 线性探测法(常考)






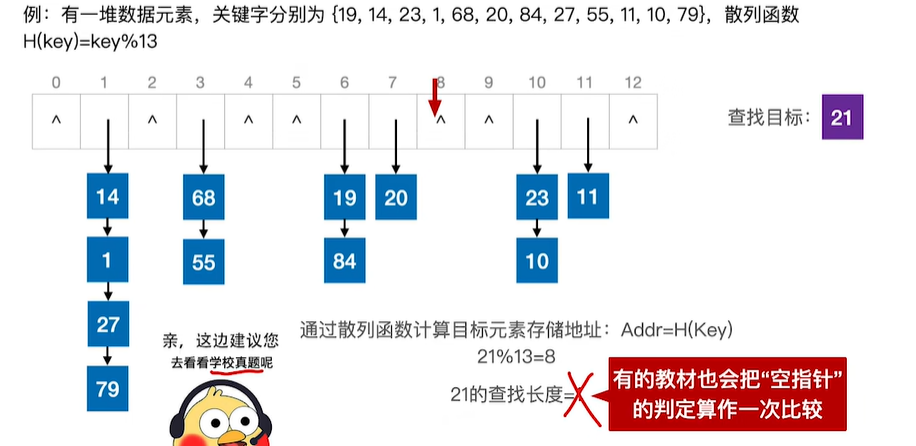
查找目标:27


查找目标:21




越早遇到空位置,就可以越早确定查找失败

1.3.2.2 平方探测法

平方探测法:比起线性探测法更不易产生“聚集(堆积)”问题非重点小坑︰散列表长度m必须是一个可以表示成4j+3的素数,才能探测到所有位置
1.3.2.3 伪随机序列法

1.3.3 再散列法

1.4 散列查找及性能分析
1.4.1 查找效率分析(ASL)——线性探测法



总结

-
相关阅读:
三菱PLC slmp(mc)协议
css知识学习系列(10)-每天10个知识点
DCA培训心得笔记(二)
SCAU 编译原理 实验1 词法分析实验
【Java】状态修饰符 final & static
Pytorch教程
华为机试真题 Java 实现【最多团队】
如何辨别优秀的人 选拔出最能打的选手
JVM原理和优化
【OpenCV 例程200篇】212. 绘制倾斜的矩形
- 原文地址:https://blog.csdn.net/qq_56897195/article/details/127780198