-
猿创征文|大数据开发必备的数据采集工具汇总
前言
随着大数据近几年的发展,已经在国内外的开发市场积累出一大批大数据开发的技术型人才,不论是批处理还是流处理各大公司都研究出一套专门解决自身公司业务的大数据解决方案。它们是市面上大数据组件的融合碰撞产生的适合自身的。
在数据处理的最前端一定是数据的采集技术,数据的采集技术也是百家争鸣,一片蓝海,对于一个优秀的大数据开发工程师,我们怎么将这些技术栈灵活的应用,前提是我们要对其认真的研究,理解其最佳的应用场景,今天我来带大家认识5种数据采集工具。

1、Flume
适用场景
适合用于日志数据的采集
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。

工作方式
Flume-og采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master间使用gossip协议同步数据。
Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。Flume-ng另一个主要的不同点是读入数据和写出数据由不同的工作线程处理(称为 Runner)。 在 Flume-og 中,读入线程同样做写出工作(除了故障重试)。如果写出慢的话(不是完全失败),它将阻塞 Flume 接收数据的能力。这种异步的设计使读入线程可以顺畅的工作而无需关注下游的任何问题。
2、Flink CDC
适用场景
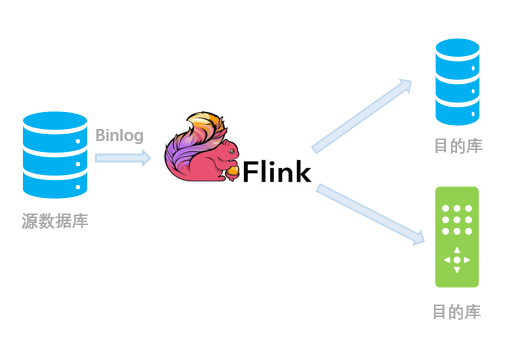
CDC 是变更数据捕获(Change Data Capture)技术的缩写,它可以将源数据库(Source)的增量变动记录,同步到一个或多个数据目的(Sink)。在同步过程中,还可以对数据进行一定的处理,例如分组(GROUP BY)、多表的关联(JOIN)等。例如对于电商平台,用户的订单会实时写入到某个源数据库;A 部门需要将每分钟的实时数据简单聚合处理后保存到 Redis 中以供查询,B 部门需要将当天的数据暂存到 Elasticsearch 一份来做报表展示,C 部门也需要一份数据到 ClickHouse 做实时数仓。随着时间的推移,后续 D 部门、E 部门也会有数据分析的需求,这种场景下,传统的拷贝分发多个副本方法很不灵活,而 CDC 可以实现一份变动记录,实时处理并投递到多个目的地。下图是一个示例,通过腾讯云 Oceanus 提供的 Flink CDC 引擎,可以将某个 MySQL 的数据库表的变动记录,实时同步到下游的 Redis、Elasticsearch、ClickHouse 等多个接收端。这样大家可以各自分析自己的数据集,互不影响,同时又和上游数据保持实时的同步。

工作方式
目前 Flink CDC 支持两种数据源输入方式。
(一)输入 Debezium 等数据流进行同步
例如 MySQL -> Debezium -> Kafka -> Flink -> PostgreSQL。适用于已经部署好了 Debezium,希望暂存一部分数据到 Kafka 中以供多次消费,只需要 Flink 解析并分发到下游的场景。

(二)直接对接上游数据库进行同步
我们还可以跳过 Debezium 和 Kafka 的中转,使用 Flink CDC Connectors(https://github.com/ververica/flink-cdc-connectors)对上游数据源的变动进行直接的订阅处理。从内部实现上讲,Flink CDC Connectors 内置了一套 Debezium 和 Kafka 组件,但这个细节对用户屏蔽,因此用户看到的数据链路如下图所示:
3、Sqoop
适用场景
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。

工作方式
Sqoop的优点:
- 可以高效、可控的利用资源,可以通过调整任务数来控制任务的并发度。
- 可以自动的完成数据映射和转换。由于导入数据库是有类型的,它可以自动根据数据库中的类型转换到Hadoop中,当然用户也可以自定义它们之间的映射关系。
- 支持多种数据库,如mysql,orcale等数据库。
sqoop工作的机制:
将导入或导出命令翻译成MapReduce程序来实现在翻译出的MapReduce中主要是对InputFormat和OutputFormat进行定制。
sqoop版本介绍:sqoop1和sqoop2
sqoop的版本sqoop1和sqoop2是两个不同的版本,它们是完全不兼容的。
4、Canal
适用场景
Canal是阿里巴巴旗下的一款开源项目,用Java开发。
对数据库日志增量解析,提供增量数据的实时同步,目前支持MySQL

工作方式
- canal 模拟 MySQL slave 的交互协议,伪装成 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析binary log 对象(原始为 byte 流)----->kafka等

5、Kettle
适用场景
Kettle最早是一个开源的ETL工具,全称为KDE Extraction, Transportation, Transformation and Loading Environment。在2006年,Pentaho公司收购了Kettle项目,原Kettle项目发起人Matt Casters加入了Pentaho团队,成为Pentaho套件数据集成架构师;从此,Kettle成为企业级数据集成及商业智能套件Pentaho的主要组成部分,Kettle亦重命名为Pentaho Data Integration 。Pentaho公司于2015年被Hitachi Data Systems收购。
Pentaho Data Integration以Java开发,支持跨平台运行,其特性包括:支持100%无编码、拖拽方式开发ETL数据管道;可对接包括传统数据库、文件、大数据平台、接口、流数据等数据源;支持ETL数据管道加入机器学习算法。
Pentaho Data Integration分为商业版与开源版,开源版的截止2021年1月的累计下载量达836万,其中19%来自中国 。在中国,一般人仍习惯把Pentaho Data Integration的开源版称为Kettle。

工作方式
ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少,这里我介绍一个我在工作中使用了3年左右的ETL工具Kettle,本着好东西不独享的想法,跟大家分享碰撞交流一下!在使用中我感觉这个工具真的很强大,支持图形化的GUI设计界面,然后可以以工作流的形式流转,在做一些简单或复杂的数据抽取、质量检测、数据清洗、数据转换、数据过滤等方面有着比较稳定的表现,其中最主要的我们通过熟练的应用它,减少了非常多的研发工作量,提高了我们的工作效率。
-
相关阅读:
软件开发方法
【软考 系统架构设计师】数据库系统② 分布式数据库
如何在Linux机器上使用ssh远程连接Windows Server服务器
Chrome内存追踪
vue3在main.js里面定义全局函数,然后其他页面使用
STM32存储左右互搏 I2C总线FATS读写FRAM MB85RC1M
模糊预测|RFIS与ANFIS模糊模型预测的比较(Matlab代码实现)
Servlet的生命周期
走出心理舒适区的七个最佳方法
前端开发中,文本单行或多行溢出使用省略号显示
- 原文地址:https://blog.csdn.net/Chad_it/article/details/127847453