-
leetcode 反转链表和删除节点
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
为什么把这两个放在一起,因为这两个思路具有相似性
都可以通过重新排列原链表的结构实现删除链表中给定 val 的节点
题目描述
链接 : 203 移除链表元素

示例

实现
方法
- 设置一个新的链表头 newhead
- 遍历源链表,如果和 val 不相等 就拷贝到新链表
- 如果相等,就忽略
图示

程序
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ struct ListNode* removeElements(struct ListNode* head, int val){ //一些常见链表参数定义 struct ListNode* pcur = head; struct ListNode* prev = head; if(pcur == NULL) { return NULL; } struct ListNode* newhead = NULL; struct ListNode* newtail = NULL; // while(pcur) { //拷贝不同的元素 if(pcur->val != val) { if(newhead == NULL) { newhead = newtail = pcur; } else { newtail->next = pcur; newtail = newtail->next; } pcur = pcur->next; } //释放相同的元素 else { prev = pcur; pcur = pcur->next; free(prev); } } //判断新的链表是否为空 if(newtail != NULL) newtail->next = NULL; return newhead; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
链表反转
题目描述
步骤简述
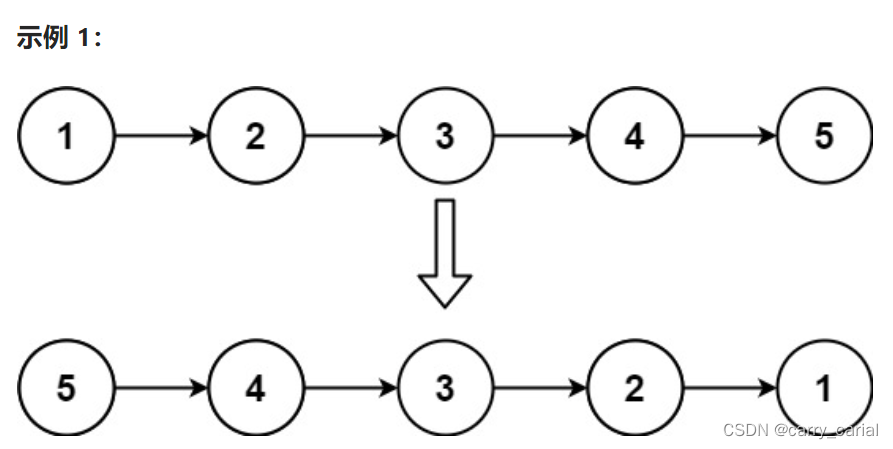
步骤分析- 设定一个新链表头 rehead
- 遍历源链表A , 将源链表A 的元素头插到 rehead 上
为什么会想到这个方法
因为比较自然想到头插链表,头插的一个特性是 输入的数组在链表的顺序是相反的
比如: 按顺序输入 1 2 3 4 ,链表上的顺序 是 4 3 2 1步骤图解

对照上方的步骤看
程序
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ struct ListNode* reverseList(struct ListNode* head){ struct ListNode* pcur = head; if(pcur == NULL) { return NULL; } struct ListNode* plast = pcur; struct ListNode* rehead = NULL; while(pcur) { plast = pcur; pcur = pcur->next; //第一个元素处理 if(rehead == NULL) { rehead = plast; rehead->next = NULL; } //其他元素处理 else { plast->next = rehead; rehead = plast; } } return rehead; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
总结
思路可以借鉴一下 空间换时间的思路,但是实际上链表空间本身是开辟的 空间复杂度是 O(1),对于数组来说也是个很好的思路
-
相关阅读:
数据提取的艺术:如何通过数据治理提高效率
【前端笔记】ant-design-vue 3.x使用modal.method()自定义content内容小记
MytatisP详解
只要5秒就能“克隆”本人语音!美玉学姐不再查寝,而是吃起了桃桃丨开源
java毕业设计南京新东方学校家校通系统源码+lw文档+mybatis+系统+mysql数据库+调试
面试准备2022-08
Java应用开发各种奇葩的问题
Unity实现一个可扩展的UGUI无限滑动列表控件
代码解读:y.view(y.size(0), -1)---tensor张量第一维保持不变,其余维度展平
java“俄罗斯方块”
- 原文地址:https://blog.csdn.net/carry_carial/article/details/127804196

