-
【C/C++内功心法】剖析编译链接的过程,探究源文件是如何一步步变成可执行程序,提升C/C++内功
文章目录
前言
大家好啊,我是不一样的烟火a,今天我将会为大家讲解源文件究竟是如何一步步变成可执行程序的,详细讲解编译链接的过程。虽然本文章读完后不能让大家代码写得飞起,但是一个源文件变成可执行程序的这个过程是十分重要的,你了解了它,它将会大幅提升你的C/C++内功,让你学编程更加的容易。
一、程序的翻译环境和执行环境
在ANSI C的任何一种实现中,存在两个不同的环境。
- 第1种是翻译环境,在这个环境中源代码(如test.c文件)被转换为可执行的机器指令(二进制指令,如test.exe文件)。
- 第2种是执行环境,它用于实际执行代码。
- 一般而言翻译环境也就是编译器。
二、详解编译+链接
1.翻译环境
下面为程序编译的过程。

- 组成一个程序的每个源文件通过编译过程分别转换成目标代码(object code)。
- 每个目标文件由链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序。
- 链接器同时也会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程序员个人的程序库,将其需要的函数也链接到程序中。
看代码:
test.c文件
- #include
- // 想使用其他文件里面的函数需要先用extern声明一下。
- extern int Add(int, int);
- extern int Sub(int, int);
- int main()
- {
- int a = 10;
- int b = 20;
- int c = Add(a, b); // 30
- printf("%d\n", c);
- int d = Sub(a, b); // -10
- printf("%d\n", d);
- return 0;
- }
add.c文件
- // 加法函数
- int Add(int x, int y)
- {
- return x + y;
- }
sub.c文件
- // 减法函数
- int Sub(int x, int y)
- {
- return x - y;
- }
运行成功。

这是我们写的三个源文件。

我们在当前源文件路径下的Debug文件夹里面可以找到三个目标文件。

我们在当前源文件路径下的Debug文件夹里面也可以找到最终的可执行程序。

我们刚刚演示的这些是在vs2019下进行的,而像vs2019这样的程序其实被称作 IDE(集成开发环境)
- 集成开发环境(IDE,Integrated Development Environment )是用于提供程序开发环境的应用程序,一般包括代码编辑器、编译器、调试器和图形用户界面等工具。集成了代码编写功能、分析功能、编译功能、调试功能等一体化的开发软件服务套。所有具备这一特性的软件或者软件套(组)都可以叫集成开发环境。
- 而在Linux下就是把这些工具都裁开,一个工具只负责一个功能。所以在Linux下编写代码就用vim,编译代码就用gcc/g++,调试代码就用gdb,运行或者自动化构建程序就用make和makefile。
如果你去vs2019的安装路径下找一定能找到vs2019的编译器和链接器。
- vs2019的编译器 —— cl.exe
- vs2019的链接器 —— link.exe


2 编译本身也分为几个阶段
- 由于vs2019是集成开发环境,不方便观察每个阶段的细节,所以我下面将会使用Linux下的gcc为大家演示编译和链接的过程。
- 温馨提示:就算没有Linux基础也能看懂哦,所以不用担心没有Linux基础而看不懂。
- 最后我们将刚刚写的 test.c、add.c、sub.c 这三个文件的代码复制到Linux下。
test.c文件
add.c文件
sub.c文件

2.1 预编译(预处理)
在预处理阶段编译器会做以下几个动作
- 将源文件中包含的头文件展开。例如:#include
,其中#include被称为预处理指令。 - #define 定义符号的替换。例如:#define Max 100,其中#define也被称为预处理指令。
- 删除注释。
Linux下的命令。
- 预处理选项 gcc -E test.c -o test.i
- 预处理完成之后就停下来,预处理之后产生的结果都放在test.i文件中。
我们将执行下面这三个命令,让编译器对这三个.c文件预处理完后就停下来。
- 命令1:gcc -E test.c -o test.i
- 命令2:gcc -E add.c -o add.i
- 命令3:gcc -E sub.c -o sub.i
预处理后,当前目录下就会出现三个.i文件。

进入test.i文件。
大家注意观察行数,我们将test.c文件预处理后,得到的test.i文件的代码比源文件多了800多行(这就是因为预处理后,源文件中包含的头文件被展开)。并且我们刚才写的所有注释也都被删除。

验证头文件展开。
在Linux环境下,头文件是放在 /usr/include 这个路径下的,我们可以到这个路径下去找到相应的头文件。
命令:cd /usr/include我们在 /usr/include 路径下可以看到有很多头文件,包括我们刚刚在test.c文件里面包含过的stdio.h文件。

进入stdio.h这个文件。
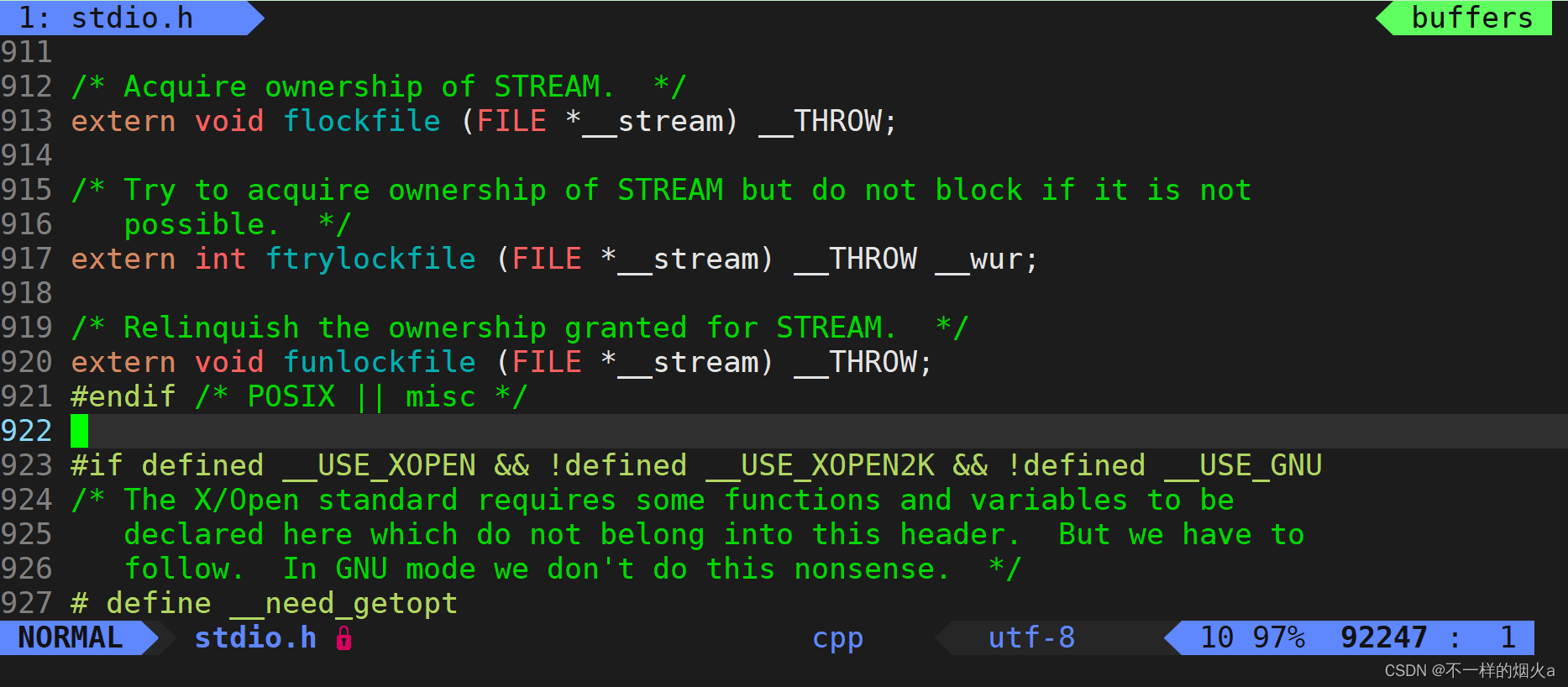
我们注意观察就可以发现test.i文件里面的增加内容基本上都是来自stdio.h文件。

验证#define 定义符号的替换。
我们添加一行宏定义。

然后再对test.c文件进行预处理后,进入test.i文件观察。这时就可以观察到刚刚定义的Max被替换掉了。

2.2 编译
在编译阶段编译器会做以下几个动作
编译器会对你写的代码进行:
- 语法分析
- 词法分析
- 语义分析
- 符号汇总(与后面的汇编、链接有关)
- 最后把你写的代码翻译成汇编语言。
Linux下的命令
- 编译 选项 gcc -S test.c
- 编译完成之后就停下来,结果保存在test.s中。
我们将执行下面这三个命令,让编译器对这三个.i文件编译完后就停下来。
- 命令1:gcc -S test.i -o test.s
- 命令2:gcc -S add.i -o add.s
- 命令3:gcc -S sub.i -o sub.s
- 注意:这里的 -S 选项是大写的哦!
编译后,当前目录下就会出现三个.s文件。

进入test.s文件。
这时我们写的代码就已经被完全转化为了汇编语言。
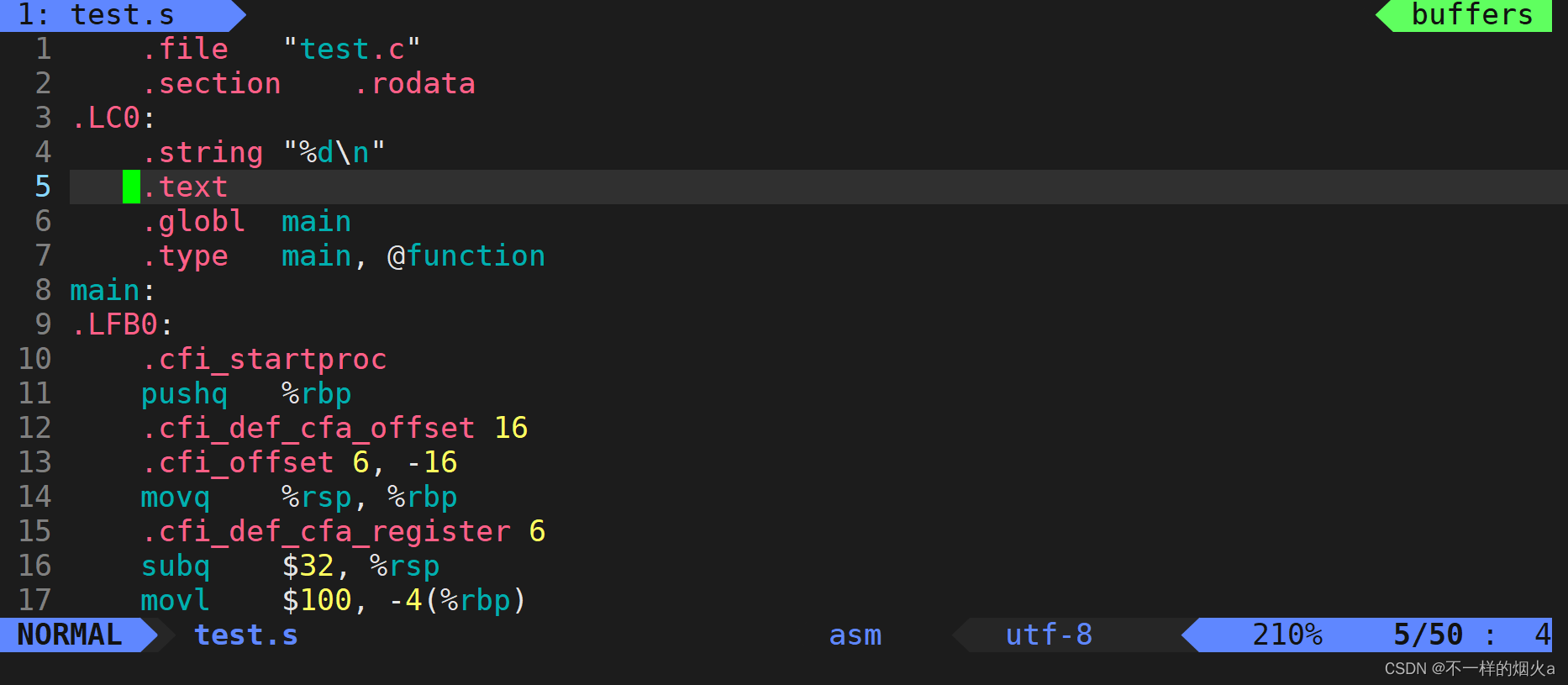
详解符号汇总
什么是符号?
- 其实符号就是程序中的变量名、函数名
- 就比如test.i文件里面的main、Add、Sub、printf都是符号,编译过程中编译器会将它们汇总起来,为后面的汇编和链接阶段做准备。(由于变量a、b、c、d都是局部变量,局部变量只有在当前作用域里才可以用,所以不用统计,一般汇总的符号都是全局的)
- 在add.i文件里面可以汇总到符号Add
- 在sub.i文件里面可以汇总到符号Sub
- 在编译阶段看不出什么,符号汇总的作用主要体现在汇编和链接阶段,所以我们后面讲汇编和链接的时候会详细讲解。
2.3 汇编
在汇编阶段编译器会做以下几个动作
- 形成符号表(与编译过程中的符号汇总有关系)
- 最后把汇编指令翻译成二进制指令。(因为计算机只认识二进制指令)
注意:
- 在Windows环境下的目标文件名是 xxx.obj
- 在Linux环境下的目标文件名是 xxx.o
Linux下的命令
- 汇编 gcc -c test.c
- 汇编完成之后就停下来,结果保存在test.o中。
我们将执行下面这三个命令,让编译器对这三个.s文件汇编完后就停下来。
- 命令1:gcc -c test.s -o test.o
- 命令2:gcc -c add.s -o add.o
- 命令3:gcc -c sub.s -o sub.o
- 注意:这里的 -c 选项是小写的哦!
汇编完后,当前目录下就会出现三个.o文件。

进入test.o文件。
这时test.i文件里面的汇编语言就已经被完全转化为了二进制指令。
详解符号表
注意:
- 在Linux环境下,像 test.o 和 可执行程序 这样的文件的格式是:elf 格式。
- 虽然我们看不懂这样的二进制文件,但是我们可以通过 readelf工具 来看这些二进制文件。
我们可以通过man手册来查看readelf的功能和所有选项。
命令:man readelf
这里我们只需要用-s选项来查看符号表信息即可。

查看test.o文件的符号表。
命令:readelf -s test.o我们可以看到test.o文件的符号表里面有main、Add、Sub、printf这些符号。

查看add.o文件的符号表。
命令:readelf -s add.o我们可以看到add.o文件的符号表里面有 Add 这个符号。

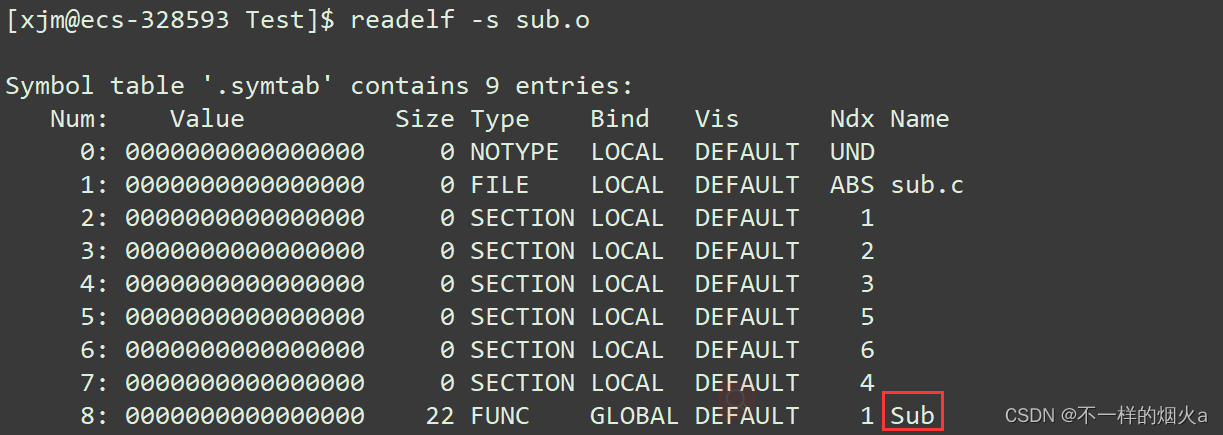
查看sub.o文件的符号表。
命令:readelf -s sub.o我们可以看到sub.o文件的符号表里面有 Sub 这个符号。
形成符号表
每个.o文件里面都有一个符号表,符号表里面有编译过程中记录的符号,并且还有与符号相关联的地址。
- 我们在test.i文件里面汇总了Add、Sub、main这些符号。(由于printf是库函数,这里暂时先不考虑)
我们在编译过程中,test.i文件里面通过extern来声明了Add和Sub这两个函数,让编译器知道有这两个符号。

但是由于我们每个文件都是单独编译的,Add和Sub是定义在其他文件里面的,所以我们下面在调用Add和Sub函数的时候我们只知道有这2个函数,但是却找不到它们具体定义在哪里。

所以我们在形成符号表的时候只能给Add和Sub一个无效的地址(也就是随便给一个地址,因为我们找不到它们具体定义在哪)
由于main函数本身就是定义在当前test.o文件里面的,能够明确的找到它,所以我们可以给main一个有效的地址。

- 我们在add.i文件里面汇总了Add这个符号。
由于Add函数本身就是定义在当前add.o文件里面的,能够明确的找到它,所以我们可以给Add一个有效的地址。

- 我们在sub.i文件里面汇总了Sub这个符号。
由于Sub函数本身就是定义在当前sub.o文件里面的,能够明确的找到它,所以我们可以给Sub一个有效的地址。

3.链接
在链接阶段编译器会做以下几个动作
- 合并段表。
- 符号表的合并与重定向。
3.1 合并段表
我们知道汇编完后的.o文件与最终的可执行程序都是elf格式的。而每个.o文件都是elf格式,是一段一段的,我们最终的可执行程序也是elf格式,为一段一段的,我们需要将每个.o文件的每一段都合并到最终的可执行程序的每一段里面。

3.2 符号表的合并与重定向。
- 将所有.o文件的符号表合并,形成可执行程序的符号表。
- 遇到两个.o文件有一样的符号时,保留有效地址,删除无效地址。
- 如果该符号只有一个无效地址,这时编译器就会报链接错误。
- 当合并完符号表后,可执行程序的符号表就拥有了所有符号有效地址,这样当其调用某个函数的时候就知道应该去那个文件里面找了。

如果调用的函数没有定义(这里用vs2019演示了)
我们这里把加法函数注释掉,然后进行编译。

这时编译器就报错了:无法解析的外部符号 _Add,函数 _main 中引用了该符号。

这是一个链接错误,因为我们将Add函数注释后,就找不到Add的有效地址了,所以编译器会报错。

总结
还是那句话,虽然本文章读完不能让大家代码写得飞起,但是源文件变成可执行程序的这个过程是十分重要的,只有了解了这个,你学编程才会更加的容易。当然我这里只为大家讲了编译链接里面十分重要的一些知识,如果大家想更深入的了解编译链接这个过程,推荐大家可以去看看《程序员的自我修养》这本书。如果大家有什么解决不了的问题,欢迎大家评论区留言或者私信告诉我。如果感觉对自己有用的话,可以点个赞或关注鼓励一下博主,我会越做越好的,感谢各位的支持。
-
相关阅读:
什么是NLP-自然语言处理
10 个 Python 自动探索性数据分析神库!
【libGDX】ApplicationAdapter生命周期
语法基础(变量、输入输出、表达式与顺序语句)
暑假leetcode剑指offer每日一题打卡-第二十天-剑指 Offer 49. 丑数(middle)
MySQL的join你真的了解吗!!!
Harbor仓库概述
04.webpack中css的压缩和抽离
.NET周刊【7月第1期 2024-07-07】
mybatisplus 自定义mapper加多表联查结合分页插件查询时出现缺失数据的问题
- 原文地址:https://blog.csdn.net/qq_64042727/article/details/127183451