-
Linux文本处理三剑客(grep,sed,awk)
文章目录
- 快捷键
- Shell通配符
- 正则表达式
- grep(文本过滤)
- sed(文本编辑)
- awk(文本统计)
- awk文本操作( awk [选项] '{脚本命令}' 文件名)
- 注意(万物皆字符串,一劳永逸)
- awk使用的查漏补缺
- awk的数组下标可为拼接字符串(类Map)
- 插入新字段和格式化空白
- 从ifconfig中筛选IPV4字段(读取某行中某字段)
- 读取配置文件中“某段”(读取某段)
- 根据字段进行‘行’去重
- awk数组做次数统计(数组索引去重统计)
- awk数组排序(sort或PROCINFO)
- 统计各key下独立value:IP个数(键去重并统计值个数)(多字段排重)
- 处理字段中包含了字段分割符(逗号)的数据
- 截取字段中指定区间的字符(substr($n,start,length))
- 替换某字段为其他字段(gsub(/待替换原内容/,"替换内容"))
- BUG之旅
grep,擅长单纯的查找或匹配文本内容
sed,更适合编辑、处理匹配到的文本内容
awk,更适合格式化文本内容,对文本进行复杂处理先了解数据格式,再编写脚本处理数据。
快捷键
- Ctrl+C 中断了进程,返回到终端界面。
- Ctrl+Z 暂停了进程,返回到终端界面
- ctrl+a 移动到命令行首
- ctrl+e 移动到命令行尾
- ctrl+u 清空光标前的内容
- ctrl+k 清空光标后的内容
- ctrl+l 清空屏幕终端内容,同clear
tab补齐,双击tab列出候选项。
Shell通配符
*通配符
*通配符匹配任意一个或多个字符
? 通配符
"?"通配符匹配一个任意字符(相比*存在数量限制)
[] 通配符
[list] 匹配list中任意单个字符
正则表达式
正则表达式是以行为单位,一次处理一行。
linux中正则表达式仅受三剑客(sed,awk,grep)支持,其他命令无法使用(仅能使用通配符*)。操作内容用正则,操作文件名用通配符
正则表达式分类
基本正则表达式^$.[]*
- ^word: 搜索以word开头的。
- word$ 搜索以word结尾的。
- . 点 表示任意一个字符
- \ 保持原样输出

扩展正则表达式
扩展正则必须用grep -E才能生效
grep不加参数,得在特殊字符前面加""反斜杠,识别为正则。(){}?+|等字符
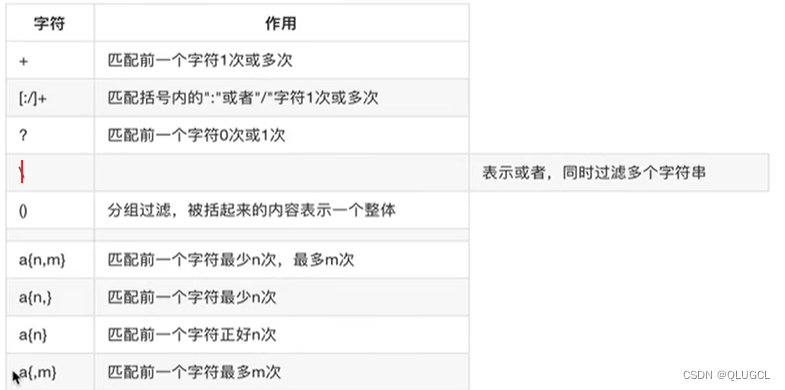
grep(文本过滤)
注意:grep是模糊过滤(包含则通过),实际上若要准确识别还要搭配awk的‘{if判断是否相等语句}‘进行精准过滤。
(查询文本)grep xxx:从stdin中读入若干行数据,如果某行中包含xxx,则输出该行(逐行输出);否则忽略该行。
可以配合ps,ls等stdout命令食用:查询进程/目录中是否存在对应进程和文件。grep配合sort可以有序输出(默认按照第一列的ASCII 码次序排序)
grep xxx | sortgrep详解
Linux命令 zgrep
使用zgrep命令可以在压缩文件中调用grep按正则表达式来搜索
zgrep -hwgrep xxx ./*.filetype:将path下的全部filetype文件内容进行查询匹配逐行输出=》文件名:匹配列


sed(文本编辑)
替换文本内容(sed -i “s/原内容/替换内容/g” file.filetype)
常见用法:
首先写一个tmpl模板文件然后写一个脚本基于tmpl模板文件替换占位符传参。sh 脚本.sh 变量参数 sed -i "s/\${tmpl参数占位符}/"${变量参数}"/g" tmpl复制份- 1
- 2
- 3


替换特殊字符(利用反斜杠)
反斜杠用法

awk(文本统计)
awk中支持C语法, 可以有分支条件判断, 循环语句等, 相当与一个小型编程语言.
-
脚本命令必须用’'括起来,当匹配规则为字符串和正则表达式的时候需要使用”/…/“符号括起来;而执行命令需要使用{}括起来。
-
对awk而言,正则表达式是置于两个正斜杠之间、由字符组成的模式。
正则表达式是以/作为开始和结束的标记,表达式语法在两个/中间包裹。 -
$n~/…/表示某字段匹配该正则表达式:返回true/false
-
awk默认是按行读取并处理文本,最终按行输出。
-
awk实现统计功能都是借助awk数组索引下标可为字符串功能进行标识定位。
awk文本操作( awk [选项] ‘{脚本命令}’ 文件名)
Linux awk命令详解
linux之awk超详解
linux awk数组操作详细介绍cat获得文件内容,grep逐行分析提取文件内容并输出,awk解析操作需求内容的每一行。
cat | grep | awkawk将"作为文本分隔符,然后提取第四列作为sum数组的定位下标并将其对应的数组元素值加一,处理完全部内容后,END最后用for循环逐行输出数组值(一次输出占一行)。
单双引号可以相互包容并原样显示。
注意:实际应用时单包双/双包单,不可单包单,双包双,无意义。无序:cat XXX.filetype | grep "yyy" | awk -F'"' '{sum[$4]+=1} END {for(k in sum) print k ":" sum[k]}' 有序:(已知:k<=100):cat XXX.filetype | grep "yyy" | awk -F'"' '{sum[$4]+=1} END {for(k=1;k<=100;k++) if (sum[k]>0) print k ":" sum[k]}'- 1
- 2
- 3
- -F“”单或双引号中指定分隔符,默认为空格,当分隔符为特殊符号时需要用转义字符。
- awk 中的数组不必提前声明,也不必声明大小。数组元素用 0 或空串来初始化。
- $n 指定分隔的第n个字段,如$1、$3分别表示第1、第3列.$0代表输入整行内容。
- 若awk的{}中要用定义的变量则’{“$变量“}‘或’{“‘$变量’“}’
- BEGIN{脚本命令}:输入开始前执行操作,END{脚本命令}:输入结束后执行操作,其余的{脚本命令}为处理每行数据的操作。
- BEGIN和END必须为大写。
- 一个{}代表一个代码块(作用范围),在{}中实现功能。
- ‘true/false{代码块}’:是/否运行代码块。代码块前可加if判断或者去掉if()只留下判断语句决定是否运行代码块。
- for{}限制for循环的作用范围,print{}限制print输出范围。
- awk中NF,NR的含义
awk中NF和NR的意义,其实你已经知道NF和NR的意义了,NF代表的是一个文本文件中一行(一条记录)中的字段个数,NR代表的是这个文本文件的行数(记录数)。在编程时特别是在数据处理时经常用到。建议你看看有关awk编程方面的资料,这可是一个功能非常强大的工具。
for(i=1;i<=NF;i++)

awk -F, '{SUM['$number']=SUM['$number']+1} END {for (i in SUM) print i,SUM[i]} '- 1
- for…in 输出,因为数组是关联数组,默认是无序的。所以通过for…in 得到是无序的数组。如果需要得到有序数组,需要通过下标获得(注意:数组下标是从1开始,与c数组不一样)。
无序:for(k in arry),有序:for(k=1;k<=len;k++)
print k : arry[k]
注意(万物皆字符串,一劳永逸)
awk当中的数组是关联数组,它的索引全是字符串,即便指定为数值也会转化为字符串:arr[1]==arr[“1”]
若数组内使用自定义变量则AWK的数组索引下标直接用"‘’"来声明字符串变量,防止变量为字符串非数值作为下标导致出错。
未使用双引号则默认为数值,反之可为字符串类型(双引号需要在变量最外侧标明)。'{SUM["'$number'"]=SUM["'$number'"]+$4}'若报错则说明检索的文本没有对应属性导致SUM[]中下标为空。

awk使用的查漏补缺
awk的数组下标可为拼接字符串(类Map)
echo "123,456,789" | awk -F, '{sum[$1"~"$2"~"$3]++}END{for(i in sum)print i,sum[i]}'- 1

插入新字段和格式化空白
awk 命令默认分隔符为空格或制表符。
插入拼接新字段(直接拼接)

echo "a b c" | awk '{$2=$2" 666" ; print}'- 1

格式化空白(牵一发动全身)
默认格式化后仅字段之间仅保留一个空格。
移除每行的前缀,后缀空白,并将各部分左对齐。echo "a b c" | awk '{$2=$2 ; print}'- 1

可以设置字段间保留一个制表符。

从ifconfig中筛选IPV4字段(读取某行中某字段)
正则表达式是以/作为开始和结束的标记,表达式语法在两个/中间包裹
对awk而言,正则表达式是置于两个正斜杠之间、由字符组成的模式。awk:取包含inet的行并且!($2匹配/^127/)的$2.
‘true/false{代码块}’:是/否运行代码块。代码块前可加if判断或者去掉if()只留下判断语句决定是否运行代码块。
注意:awk '/xxxyyy/{print}'等效于grep xxxyyy- 1
ifconfig | awk '/inet / && !($2~/^127/){print $2}'- 1

awk按段读取ifconfig | awk 'BEGIN{RS=""}!/^lo/{print$6}' 等价 ifconfig | awk 'BEGIN{RS=""}NR==1{print$6}'- 1
- 2
- 3


读取配置文件中“某段”(读取某段)
此处也可以在命令行执行。
index($0,"[xxx]"){ print while( (getline var) > 0 ){ if(var ~ /\[.*\]/){ exit } print var } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9


根据字段进行‘行’去重
注意:print==print$0
所有文本操作命令都要在‘{代码块}’中使用‘true/false{代码块}’:是/否运行代码块。代码块前可加if判断或者去掉if()只留下判断语句决定是否运行代码块。
[xxx] 6?6?6?6?6?6 8?8?8?8?8?8?8?8 9?9?9?9?9?9?9?9?9 [yyy] 9?9?9?9?9?9?9?9?9 8?8?8?8?8?8?8?8 6?6?6?6?6?6- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
awk -F "?" '!arr[$2]++{print}' test666.txt awk -F "?" '{arr[$2]++;if(arr[$2]==1)print}' test666.txt- 1
- 2

awk数组做次数统计(数组索引去重统计)
awk '{a[$0]++} END{for(i in a) print i,a[i]}' test666.txt- 1

awk数组排序(sort或PROCINFO)
sort命令
Linux sort命令用于将文本文件内容加以排序。sort可针对文本文件的内容,以行为单位来排序。shell中sort命令有3种执行模式,分别是排序文本,检查文件是否已经排序,合并文件。数组索引无序输出变为按照数组索引降序输出。
PROCINFO[“sorted_in”]=“@val_num_desc”;awk '{a[$1]++}END{PROCINFO["sorted_in"]="@val_num_desc";for(i in a)print i,a[i]}' test666.txt 只输出前十个 awk '{a[$1]++}END{PROCINFO["sorted_in"]="@val_num_desc";for(i in a){if(cnt++==10){exit}print i,a[i]}}' test666.txt- 1
- 2
- 3

统计各key下独立value:IP个数(键去重并统计值个数)(多字段排重)
key:value
统计相同key下不同value的个数。
点睛之笔:awk数组索引下标排重法(awk自带以逗号为间隔的索引下标表示法)
awk当中的数组是关联数组,它的索引全是字符串,即便指定为数值也会转化为字符串:arr[1]==arr[“1”]awk -F"|" '!arr[$1,$2]++{cnt[$1]++}END{for(i in cnt)print i,cnt[i]}' test888.txt- 1

处理字段中包含了字段分割符(逗号)的数据
BEGIN{FPAT=“[^,]+|\”.*\“”}
awk 'BEGIN{FPAT="[^,]+|\".*\""} {print $1}'- 1
截取字段中指定区间的字符(substr($n,start,length))
start为$n字段的起始索引(从一开始),length为读取长度。
- substr($n,start,length)//start开始读取length个字符。
- substr($n,start)//start开始读取到最后。
awk -F"," '{print substr($2,1,3)}' test999.txt- 1

替换某字段为其他字段(gsub(/待替换原内容/,“替换内容”))
在awk语句中,可以使用sub或者gsub进行文本替换,其中sub只是对第一处匹配进行替换,而gsub能够对所有匹配进行替换。
实例演示
源数据格式1:2:3:4
a: b:c:d#将每行第一个:替换成-
printf '1:2:3:4\na:b:c:d\n' | awk '{sub(/:/,"-")}1'- 1
1-2:3:4
a-b:c:d#将每行的:替换成-
printf '1:2:3:4\na:b:c:d\n' | awk '{gsub(/:/,"-")}1'- 1
1-2-3-4
a-b-c-d实例:去掉空格
awk '{gsub(/ /,"")}1'- 1
注意,这行代码末尾有个‘1’,这个数的作用是表示打印,换成其他非零数字都可以,等同于
awk '{gsub(/ /,"");print $0}'- 1

BUG之旅
涉及通配符统计数据时,重复统计问题(表现:统计量>正常量)
当涉及*通配符的统计数据出问题时,一般是通配符导致的重复统计问题,需要精确调整下通配符。
-
相关阅读:
免费Scrum管理工具-Leangoo领歌
springCloud在pom中快速修改运行环境,让配置不再繁琐
【Python】time模块以及应用
5-羧基四甲基罗丹明琥珀酰亚胺酯,CAS号:150810-68-7
【概率论基础进阶】随机变量的数字特征-矩、协方差和相关系数
IFoerster IsoSDK FoxSDK Crack-2022
在一个页面实现数据库的增删改查
10.28模拟赛总结
亚马逊新手运营需要规避哪些风险?怎么分析竞争对手?——站斧浏览器
MySQL分批插入/更新数据
- 原文地址:https://blog.csdn.net/qq_43813373/article/details/127708978