-
oracle高级—索引
索引

SQL优化的几种解决方案- 索引(index)
- 分区(partition)
- 物化视图
- 并行查询
索引的概念
- B树索引结构
leaf block存的是数据rowid和数据项)
1)叶块之间使用双向链连接,为了可以范围查询。
2)删除表行时案引叶块也会更新,但只是逻辑更改,并不做物理的删除叶块。
3)索引叶块中不保存表行键值的null信息。 - 位图索引结构
离散度指的是重复度[比较多用位图索引],
create bitmap index job_bitmap on emp1 (job) ;(因为job的值重复分布的比较多,即离散度比较低)
索引的说明和目的
- 索引是与表相关的一个可选结构,在逻辑上和物理上都独立于表的数据,索引能优化查询,不能优化DML操作,oracle自动维护索引,频繁的DML操作反而会引起大量的索引维护。
- 如果SQL语句仅访问被索引的列,那么数据库只需从索引中读取数据,而不用读取表,如果该语句同时还要访问除索引列之外的列,那么,数据库会使用rowid来查找表中的行,通常,为检索表数据,数据库以交替方式先读取索引块,然后读取相应的表块。
索引的目的:
主要是减少IO,这是本质,这样才能体现索引的效率。- 大表,返回的行数<5%
- 经常使用where子句查询的列
- 离散度高的列
- 更新键值代价低
- 逻辑AND、OR效率高
- 查看索引在建在那表、列:
查看索引
SELECT * FROM USER_INDEXES; SELECT * FROM USER_IND_COLUMNS;- 1
- 2
索引的使用
(1) 唯一索引(unique or non_unique):唯一索引指键值不重复。
create unique index empno_idx on emp1 ( empno) : drop index empno_idx ;- 1
- 2
(2) —般索引:键值可以重复
create index empno_idx on emp1 (empno);- 1
(3)组合索引(composite):绑定了两个或更多列的索引
create index job_deptno_idx on emp1 (job,deptno); drop index job_deptno_idx ;- 1
- 2
(4) 反向键索引(reverse)
(5) 函数索引(function_index)
(6) 压缩索引(compress)
(7) 升序降序索引索引的问题
- 索引碎片问题:由于对基表做DML操作,导致索引表块的自动更改操作,尤其是基表的
delete操作会引起index表的index_entries的逻辑删除,注意只有当一个索引块中的全部index_entry都被删除了,才会把这个索引块删除,索引对基表的delete.insert操作都会产生索引碎片问题。 - 在Oracle文档里并没有清晰的给出索引碎片的量化标准,Oracle建议通过
Segment Advisor(段顾问)解决表和索引的碎片问题,如果想自行解决,可以通过查看index stats视图,当以下三种情形之一发生时,说明积累的碎片应该整理了(仅供参考)。
1 HEIGHT >=4 2 PCT_USED<50% 3 DEL_LF_ROWS/LF_ROWS>0.2- 1
- 2
- 3
举例说明:
建表和索引
CREATE TABLE t (ID INT); CREATE INDEX ind_1 ON t(ID);- 1
- 2
向表中插入100万条数据
BEGIN FOR i IN 1 .. 1000000 LOOP INSERT INTO t VALUES (i); IF MOD(i, 100) = 0 THEN COMMIT; END IF; END LOOP; END;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
查询当前状态,此时记录为空
SELECT NAME,height,pct_used,del_lf_rows/lf_rows FROM index_stats;- 1

分析索引ANALYZE INDEX ind_1 validate STRUCTURE;- 1
执行查询
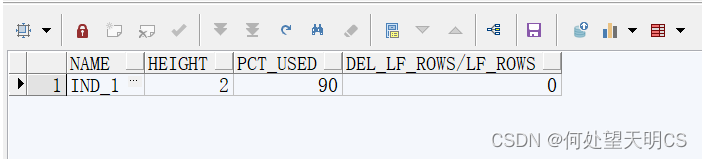
SELECT NAME,height,pct_used,del_lf_rows/lf_rows FROM index_stats;- 1

破坏索引,删除数据
DELETE t WHERE ROWNUM<700000;- 1

再次执行分析和查询

整理索引碎片
ALTER INDEX ind_1 REBUILD [ONLINE][TABLESPACE NAME];- 1

再次执行分析和查询,此时已经整理完成。
-
相关阅读:
制作甘特图
mysql的监控大屏
STM32实战总结:HAL之高级定时器
微信小程序登录以及获取微信用户信息
LVS简介【暂未完成(半成品)】
[机缘参悟-38]:鬼谷子-第五飞箝篇 - 警示之一:有一种杀称为“捧杀”
基于Spring Boot的LDAP开发全教程
论文阅读 - Natural Language is All a Graph Needs
GB28181学习(二)——注册与注销
工控自动化方案:和利时LE系列PLC数采通讯
- 原文地址:https://blog.csdn.net/weixin_43752912/article/details/127673319