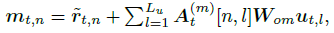目标:对每帧图像提取多样的region feature 对平均采样的T帧图像使用预训练的CNN提取二维grid feature
v
t
∈
R
L
v
×
C
v
v_t \in R^{L_v \times C_v}
vt∈RLv×Cv,
L
v
=
H
v
×
W
v
L_v=H_v \times W_v
Lv=Hv×Wv,
C
v
C_v
Cv是通道数
guidance vector
g
t
,
n
g_{t,n}
gt,n用于指导region feature
r
t
,
n
r_{t,n}
rt,n生成。(简单起见,规定每一帧图像中的region数量为N)
spatial attention map:通过guidance vector
G
G
G对
V
V
V进行注意
diversity loss
λ
\lambda
λ用于控制attention分布的“softness”程度,如果趋于1则attention趋向one-hot,反之更分散
RRA提取多样的region feature同时对帧间关系进行建模;MGCMP的目标是建立region之间的时间联系同时鼓励帧间的信息交流。主要是在每一步更新连续两帧的region feature。(在实现上有些类似GCN)
M
t
(
⋅
)
,
U
t
(
⋅
)
M_t( \cdot ), U_t( \cdot )
Mt(⋅),Ut(⋅)分别表示calculation phase,update phase;
U
=
{
u
1
,
.
.
.
,
u
T
}
U = \{ u_1,...,u_T\}
U={u1,...,uT}为motion feature;
A
t
(
m
)
,
A
t
(
u
)
A_t^{(m)},A_t^{(u)}
At(m),At(u)为两个动态更新的关联矩阵(也叫相似度矩阵);
r
~
\tilde{r}
r~为更新后的region feature
最后压缩(聚合所有)信息 这里的
A
G
G
(
⋅
)
AGG(\cdot)
AGG(⋅)表示聚合方法,有多种选择,作者使用的是平均池化。最后得到updated region feature
F
=
{
f
1
,
.
.
.
,
f
T
}
F = \{ f_1,...,f_T\}
F={f1,...,fT}
3. Adjusted Temporal Graph Decoder(时间关系建模)
目标是结合GCN对特征进行调节,以建立视频特征之间的高阶时间关系,并基于解码器状态调整特征。
G
s
∈
R
T
×
T
G_s \in R^{T \times T}
Gs∈RT×T表示邻接矩阵。 聚合这些特征 得到
F
s
ˉ
\bar{F_s}
Fsˉ并作为decoder的输入
decoder
e
s
−
1
e_{s-1}
es−1表示上一步的word embedding,对hidden state 进行预测
调整graph结构(这里F应该是作为node)
objective loss 从左到右依次为caption loss 和 diversity loss