-
【教学类-09】20221022《动物棋》(数字续写和骰子游戏)(大班主题《动物花花衣》)
效果样式:
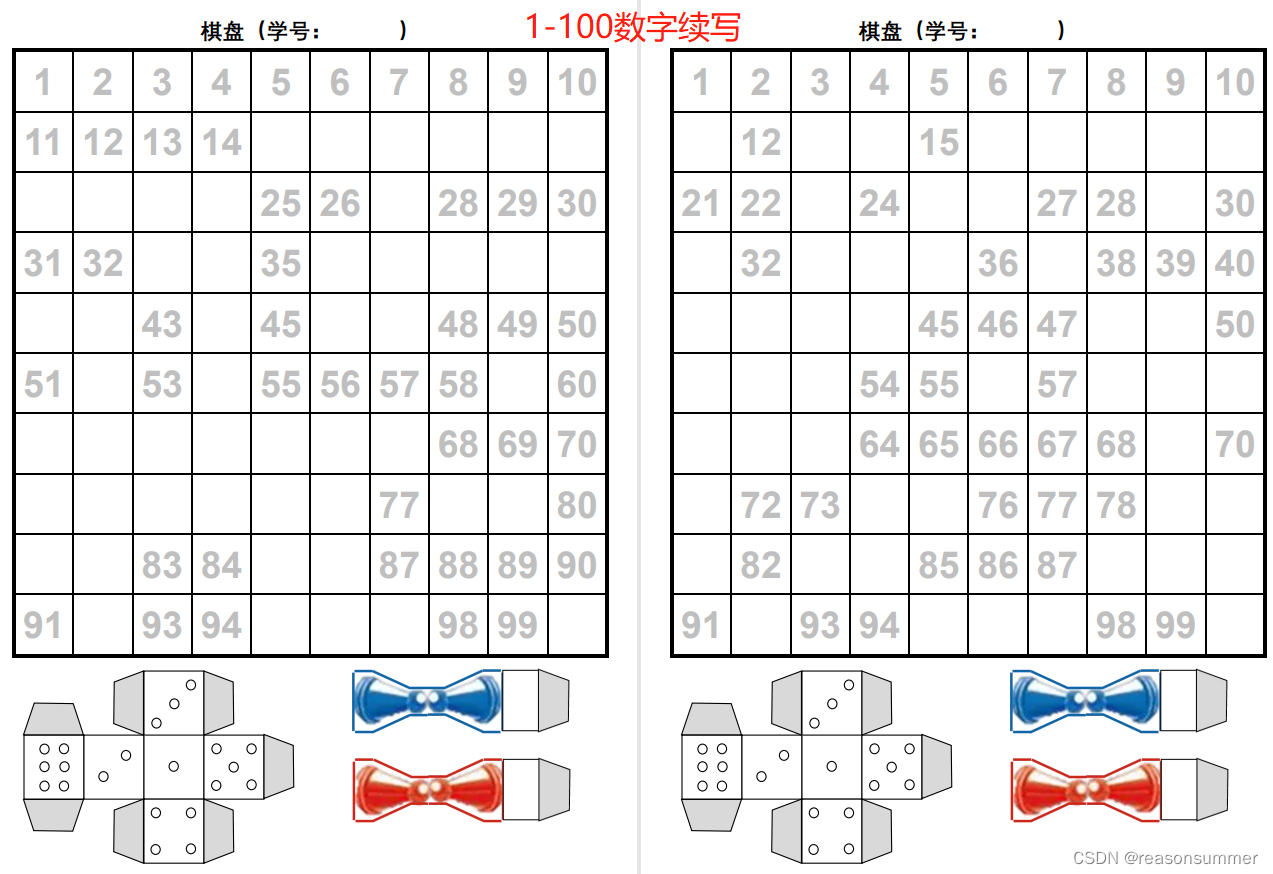
背景需求:
【教学类-08】“门牌号”的设计原理是对已有的Word模板内的“数字”进行随机删除,幼儿尝试补全空格上的门牌号。根据这个思路,我把代码进行调整,制作了一个《旅行棋》,主要目标是练习1-100的数字续写
大班学习材料包中“动物棋”(照片等下学期材料包下发再贴)里面包含了筛子和棋子的图纸,让幼儿玩棋盘游戏。考虑到大班幼儿做题(填数字)的速度有快慢,所以额外在A4纸下方的空白区域加入了筛子图纸和棋子图纸,让先填完数字的孩子有事可做(消磨时间)
材料准备:


特别说明:
100个灰色数字数量太多,如果手动输入要很长时间。因此在代码的第一部分先制作1-100的数字,变成10*10的矩阵导入XLS内
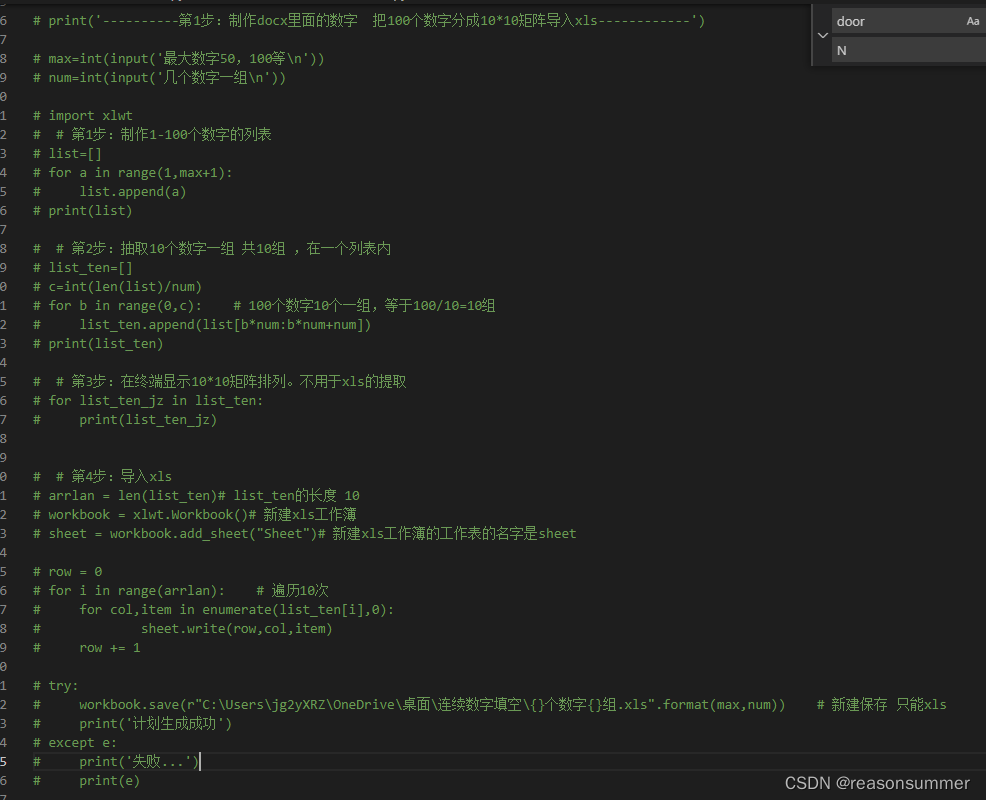

再手动贴入Word模板10*10内,调整字体大小、表格大小、色度(其中100需要单独缩小字号)

筛子和棋子的尺寸(复制到DOCX内还需要手动调整大小)

模板使用到的元素都制作好了
代码设计
- '''
- 作者:阿夏
- 时间:2022年10月20日
- 名称:大班学具:100以内连续数字填空)
- '''
- # print('----------第1步:制作docx里面的数字 把100个数字分成10*10矩阵导入xls------------')
- # max=int(input('最大数字50,100等\n'))
- # num=int(input('几个数字一组\n'))
- # import xlwt
- # # 第1步:制作1-100个数字的列表
- # list=[]
- # for a in range(1,max+1):
- # list.append(a)
- # print(list)
- # # 第2步:抽取10个数字一组 共10组 ,在一个列表内
- # list_ten=[]
- # c=int(len(list)/num)
- # for b in range(0,c): # 100个数字10个一组,等于100/10=10组
- # list_ten.append(list[b*num:b*num+num])
- # print(list_ten)
- # # 第3步:在终端显示10*10矩阵排列。不用于xls的提取
- # for list_ten_jz in list_ten:
- # print(list_ten_jz)
- # # 第4步:导入xls
- # arrlan = len(list_ten)# list_ten的长度 10
- # workbook = xlwt.Workbook()# 新建xls工作簿
- # sheet = workbook.add_sheet("Sheet")# 新建xls工作簿的工作表的名字是sheet
- # row = 0
- # for i in range(arrlan): # 遍历10次
- # for col,item in enumerate(list_ten[i],0):
- # sheet.write(row,col,item)
- # row += 1
- # try:
- # workbook.save(r"C:\Users\jg2yXRZ\OneDrive\桌面\连续数字填空\{}个数字{}组.xls".format(max,num)) # 新建保存 只能xls
- # print('计划生成成功')
- # except e:
- # print('失败...')
- # print(e)
- print('----------第2步:制作docx里面的数字 把100个数字分成10*10矩阵导入xls------------')
- import os
- max=int(input('最大数字50,100等\n'))
- delete=int(input('需要删除几个数字100个里面删除\n'))
- num=int(input('需要多少份教具\n'))
- Y=int(input('共有几层楼\n'))
- X=int(input('每层几间房\n'))
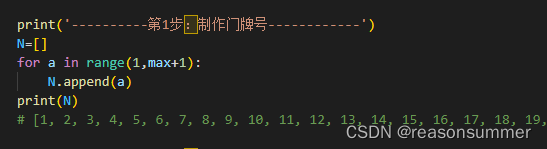
- print('----------第1步:制作门牌号------------')
- N=[]
- for a in range(1,max+1):
- N.append(a)
- print(N)
- # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100]
- print('----------第2步:新建一个临时文件夹------------')
- # 新建一个”装N份word和PDF“的文件夹
- os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\连续数字填空\零时Word')
- print('----------第3步:随机抽取门牌号数字 打开Word,把抽取的门号替换为空------------')
- import random
- from win32com.client import constants,gencache
- from win32com.client.gencache import EnsureDispatch
- from win32com.client import constants # 导入枚举常数模块
- import os,time
- # C:\Users\jg2yXRZ\OneDrive\桌面\连续数字填空\连续数字填空10乘10.docx
- for nn in range( 1,num+1):
- word = gencache.EnsureDispatch('Word.Application')
- #启动word对象应用
- word.Visible = False
- doc = word.Documents.Open(r'C:\Users\jg2yXRZ\OneDrive\桌面\连续数字填空\连续数字填空{}乘{}.docx'.format(Y,X))
- #单个另存为word 单独文件夹内
- doc.SaveAs(r'C:\Users\jg2yXRZ\OneDrive\桌面\连续数字填空\零时Word\{}.docx'.format('%02d'%nn)) # '%02d'%nn=把"1.docx"改成"01.docx"
- doc.Close() #关闭1.docx
- #打开“1.docx”
- time.sleep(1)
- doc = word.Documents.Open(r'C:\Users\jg2yXRZ\OneDrive\桌面\连续数字填空\零时Word\{}.docx'.format('%02d'%nn))
- # 随机抽取几个门牌号(#CSDN博主「孟意昶」 原文链接:https://blog.csdn.net/weixin_44999258/article/details/125163277)
- shuffle = random.sample(N[10:], delete) # 这是从11开始取值,因为如果改1,会把11,12,21中间的1删除
- print(shuffle) # ['602', '403', '505']
- for b in shuffle:
- print(b) # 602\403\505
- # 删除表格里的门牌号 (作者:守候\链接:https://www.zhihu.com/question/388608509/answer/2552638658)
- i = 0
- for ta in doc.Tables: # 遍历表格
- # f为每个表格区域查找
- f = ta.Range.Find
- # 查找框参数
- f.ClearFormatting() # 清除原有格式
- f.Forward = True # 向前查找
- f.Wrap = constants.wdFindStop # 查找完成即停止
- f.MatchWildcards = True # 使用通配符,根据需要设置
- f.Text = '{}'.format(b) # 查找的内容
- # 替换框参数(删除为空=把门号替换为''空值
- f.Replacement.ClearFormatting() # 清除原有格式
- f.Replacement.Text = '' # 替换框内容
- # f.Replacement.Font.ColorIndex = constants.wdRed # 替换文本的颜色设置为红色,此处是为了演示方便,看到效果。根据需要设置
- f.Execute(Replace=constants.wdReplaceAll) # 执行,查找全部
- i += 1
- doc.Save()# 把有空格的1.docx保存
- # 打开1.docx 另存为1.pdf 每一个单页的docx分别保存一个单页的PDF
- doc=word.Documents.Open("C:/Users/jg2yXRZ/OneDrive/桌面/连续数字填空/零时Word/{}.docx".format('%02d'%nn),ReadOnly=1)
- doc.ExportAsFixedFormat("C:/Users/jg2yXRZ/OneDrive/桌面/连续数字填空/零时Word/{}.pdf".format('%02d'%nn),constants.wdExportFormatPDF)
- # 关闭1.docx
- doc.Close()
- print('----------第4步:把都有PDF合并为一个打印用PDF------------')
- # 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
- import os
- from PyPDF2 import PdfFileMerger
- target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/连续数字填空/零时Word'
- pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
- pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
- pdf_lst.sort()
- file_merger = PdfFileMerger()
- for pdf in pdf_lst:
- print(pdf)
- file_merger.append(pdf)
- file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/连续数字填空/(打印合集)连续数字填空{}乘{}.pdf".format(Y,X))
- file_merger.close()
- # doc.Close()
- # print('----------第5步:删除临时文件夹------------')
- import shutil
- shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/连续数字填空/零时Word') #递归删除文件夹,即:删除非空文件夹
重点说明:
1、本文用的基本元素:数字1-100(1-9不需要加前面0)。
2、随机删除50个(总数一半)的数字不包括1-9
测试发现如果1进入替换,会把10*10表格中的11,15、21、31……中间的“1”删掉,暂时无法解决。就保留第一行的1-10,便于幼儿观察规律。

视频演示:
信息说明:旅行棋10*10,共100格,11-100之间删除50格,生成30份,用时4:25
20221022Python旅行棋10乘10
成品效果(PDF打印纸)30份

感悟:
确立“矩阵式”X*Y的纸类学具的设计方法,主要玩法:
1,技能类:描灰色数字(练数字书写)、发现规律数字填空
2、磨时间类:背面废纸面画画,制作小配件玩具。
3、互助类:整理环境(有废纸的情况)、为同学代做题目等。
-
相关阅读:
HTB-Armageddon
GIt的使用
OPENCV--实现meanshift图像分割
Spring MVC组件之ViewResolver
shell脚本相关基础操作汇总
手握“发展密钥”,TCL科技或迎价值重估?
计算机三级四级嵌入式备战经验
项目:CV和NLP结合的Attention视频字幕生成算法实现
聊聊数据库事务内嵌TCP连接
网络安全—DDoS攻防
- 原文地址:https://blog.csdn.net/reasonsummer/article/details/127461964
