-
Ubuntu安装hadoop集群 hive spark scala
1.Ubuntu虚拟机搭建
1.1安装配置Oracle VM VirtualBox虚拟机
- 下载虚拟机exe文件
下载地址:百度网盘连接http://pan.baidu.com/s/1mibrCgw 密码:ymke
安装过程中,若出现多选框,需全选,然后根据提示进行安装,最后Finish安装完成。
- 设定虚拟机的存储文件夹
如图中箭头所示,依次的顺序为,管理,在弹出的对话框中选择常规,然后选择你要存储的文件夹,即点击其它,按下打开按钮后,可以在默认虚拟电脑位置看到我们选择好的文件夹,最后点击确定。

1.2在VirtualBox上安装虚拟机
点击新建按钮,然后输入虚拟机的名称,选择虚拟机的类型,选择版本。如果在可选的版本中没有出现Ubuntu 64位,则可能是电脑的VT-x没有开启。由于电脑的不同,在BIOS中开启的方法也不同,下面列出的为Insyde BIOS系统的开启方法。进入BIOS后,操作如下:
- 进入Configuration
- 选择Intel Virtyal Technology
- 选择enabled 回车
- 选择yes

点击下一步,然后设定内存的大小,建议设定的内存为2g,如果过大,启动虚拟机的时候可能会报错。

点击下一步,选择现在创建虚拟机硬盘。下一步后,选择虚拟硬盘的格式为VDI,下一步选择动态配置,下一步选择存储的大小,然后点击建立。
1.3 Ubuntu Linux系统的安装
- 下载Ubuntu64位系统
百度网盘 请输入提取码 gp30
- 安装虚拟机光碟
选中之前建立的hadoop,点击设置,选择存储,选择没有盘片,选择光盘图标,选择一个虚拟光盘文件。
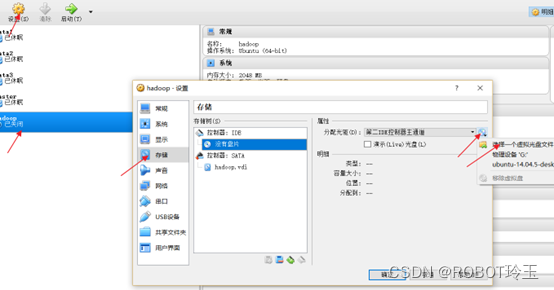
选择之前下载好的iso镜像文件后,然后点击确定。启动hadoop。启动后,语言选择中文简体,然后按下【安装Ubuntu】。
安装过程,选择安装下载更新与第三方软件,选择清除磁盘并安装Ubuntu,点击立刻安装,若弹出对话框提示,则点击继续。选择地点,选择键盘的排列方式为英语(美式)。
输入名称和电脑名称及密码等。选择输入密码才能登陆。选择立即重新启动。
- 启动Ubuntu
安装Guest Additions解决分辨率低等问题。选择设备,点击安装增强功能。


若没有弹出图中的对话框,点击光盘,选中弹出,然后再按之前的步骤操作,即可出现。然后输入登陆密码,等待系统处理。
然后设置Ubuntu系统的文字输入系统和共用剪贴簿。
设定安装和更新软件为最佳的服务器。选择系统右上角的设置,选中系统设置,选择软件和更新。


选择最佳服务器之后,输入密码授权,然后选择重新载入。

2 . Hadoop Single Node Cluster安装
以一台机器建立hadoop环境。
2.1安装JDK(一定要是JDK8)
开启终端机 Ctrl+Alt+T,点击锁定到启动器。

可以配置终端显示的颜色和字体。

java –version 查看当前的Java版本。

用apt来下载相应的软件。
sudo apt-get update 连线至APT Server 更新套件信息
sudo apt-get install default-jdk
安装之后再次检查java版本 java –version
查看java安装路径
update-alternatives –display java
2.2设定ssh无密码登陆
启动hadoop系统,需要NameNode节点与DataNode节点之间进行连线,设定使用ssh登陆。
ssh参考资料SSH原理与运用(一):远程登录 - 阮一峰的网络日志
安装ssh
sudo apt-get install ssh
安装lunix系统下的数据镜像备份工具rsync
sudo apt-get install rsync
产生ssh key
ssh-keygen –t dsa –P “ –f ~/.ssh/id_dsa
将产生的key放到档案中
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
2.3安装Hadoop
- 下载Hadoop
http://hadoop.apache.org/releases.html
选中2.6.5版本,点击binary下载。
执行 wget http://apache.fayea.com/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
下载完成后,解压缩
sudo tar –zxvf hadoop-2.6.5.tar.gz
移至目录
sudo mv hadoop-2.6.5 /usr/local/hadoop
查看安装目录
ll /usr/local/hadoop
- 设定hadoop的环境参数
sudo gedit ~/.bashrc
编辑:在文件最下方输入如下内容
#Hadoop Variables
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
#Hadoop Variables
- 设定core-site.xml,我们必须设定HDFS的名称
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
在
和 之间添加下列内容。fs.default.name hdfs://master:9000 - 编辑yarn-site.xml文件,这是yarn(MapReduce2)相关的组件设定。
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
在
和 之间添加下列内容。yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler - 设定mapred-site.xml,用于监控Map与Reduce程序的JobTracker工作分配状况,及TaskTracker的工作执行情况。
复制文件
sudo cp/usr/local/hadoop/etc/hadoop/mapred-site.xml.template
/usr/local/hadoop/etc/hadoop/mapred-site.xml
编辑mapred-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
在
和 之间添加下列内容mapred.job.tracker master:54311 - 设定hdfs-site.xml,用于设定HDFS分散式系统
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
在
和 之间添加下列内容:dfs.replication 3 dfs.namenode.data.dir file:/usr/local/hadoop/hadoop_data/hdfs/namenode dfs.datanode.data.dir file:/usr/local/hadoop/hadoop_data/hdfs/datanode - 建立格式化HDFS目录
建立NameNode目录:
sudo mkdir –p /usr/local/hadoop/hadoop_data/hdfs/namenode
建立DataNode目录:
sudo mkdir –p /usr/local/hadoop/hadoop_data/hdfs/datanode
修改hadoop目录的所有者:
sudo chown hduser:hduser –R /usr/local/hadoop
格式化namenode:
hadoop namenode –format
- 启动hadoop
方法一:
启动HDFS
start-dfs.sh
启动YARN
start-yarn.sh
方法二:
同时启动HDFS与YARN
start-all.sh
可用jsp命令,查看相关的进行是否启动
Yarn需要启动的为:
ResourceManager
NodeManager
HDFS需要启动的为:
SecondaryNameNode
NameNode
DataNode
启动之后可以开启Hadoop ResourceManage Web页面
可以开启NameNode HDFS Web页面
hadoop3以上查看地址
hadoop2查看地址
http://localhost:50070
2.4安装Hadoop集群
主机master在HDFS中担任NameNode、在MapReduce2(YARN)中担任ResourceManager角色。
多台电脑data1、data2、dta3,在HDFS中担任DataNode、在MapReduce2(YARN)中担任NodeManager角色。
- 建立data1虚拟机
- 将之前建立的虚拟机复制为data1,为data1添加两个网卡,用于连接外网和构建内部网络。


按图所示,进行设置。
- 为data1设定固定ip地址
sudo gedit /etc/network/interfaces 打开文件,设定第一个网卡,输入如下内容:
#NAT interface
auto eth0
iface eth0 inet dhcp
设定DHCP为自动获得ip地址,用于连接外网。设定第二个网卡,输入如下内容:
auto eth1
iface eth1 inet static
address 192.168.56.101
netmask 255.255.255.0
network 192.168.56.0
broadcast 192.168.56.255
设定连接内部网络的为指定的ip地址。
- 编辑主机名称
sudo gedit /etc/hostname开启后,输入如下内容
data1
- 内部网络主机名与ip互通
编辑hosts文件 sudo gedit /etc/hosts
192.168.56.100 master
192.168.56.101 data1
192.168.56.102 data2
192.168.56.103 data3
- 设置xml文件内容
编辑core-site.xml,设定HDFS的预设名称,由于有多台电脑,故应指定主机名称。
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
fs.default.name hdfs://master:9000 使用程序存取HDFS时,可以使用hdfs://master:9000.
编辑yarn-site.xml,设定MapReduce2(YARN)相关的设定。
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.resource-tracker.address master:8025 yarn.resourcemanager.scheduler.address master:8030 yarn.resourcemanager.address master:8050 ResourceManager 与NodeManager的连接位置8025
ResourceManager 与ApplicationMaster的连接位置8030
ResourceManager 与客户端的连接位置8050
编辑mapred-site.xml,设定监控Map与Reduce程序中的jobTracker工作分配状况,及TaskTracker工作执行的情况。
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
mapred.job.tracker master:54311 用于设定map reduce job tracker的连接位置:master:54311
编辑hdfs-site.xml,由于data1只是一个节点,故文件中只保留DataNode的内容。
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
dfs.replication 3 dfs.datanode.data.dir file:/usr/local/hadoop/hadoop_data/hdfs/datanode 所有的都设定好之后,
修改/etc/haoop/workes文件,添加上所有主机的名称,

根据实际的主机名称填写
重新启动data1。
确认网络。
ifconfig,确认图中黄色标注的内容是否正确。

并在浏览器中,输入外网,确认外网的连接。然后将data1关机,并复制data1到data2、data3、master。复制时需要修改虚拟机的名称。


- 同之前设定data1的方法一致,设定hostname和IP地址。data2的ip地址为19168.56.102,data3的ip地址为19168.56.103,master的ip地址为19168.56.100。
- 设定master虚拟机
hdfs-site.xml,由于该虚拟机为主机NameNode,同data1的DataNode不一样。
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
dfs.replication 3 dfs.namenode.data.dir file:/usr/local/hadoop/hadoop_data/hdfs/namenode 设定masters,使hadoop集群知道哪台机器是NameNode
sudo gedit /usr/local/hadoop/etc/hadoop/masters
master
- master连线至data1、data2、data3
ssh data1
配置data1
hduser@data1:~$ sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
[sudo] password for hduser:
hduser@data1:~$ mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
hduser@data1:~$ sudo chown -R hduser:hduser /usr/local/hadoop
hduser@data1:~$
连线data2和data3,配置方式同data1.
配置master
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
sudo chown -R hduser:hduser /usr/local/hadoop
hadoop namenode -format (格式化hdfs)
启动hadoop集群环境。
start-all.sh
查看master开启的程序
jps
Jps
ResourceManager
SecondaryNameNode
NameNode
应保证以上内容都开启。
查看data1开启的程序
jps
NodeManager
Jps
DataNode
从data1退出到master
exit
停止hadoop集群环境
stop-all.sh
- 开启前端页面,查看程序执行情况
启动之后可以开启Hadoop ResourceManage Web页面

可以开启NameNode HDFS Web页面

遇到错误解决
1.查看日志,如果为端口占用,则kill掉占用的进程。
2.如果是ID冲突,删除掉所有节点的/tmp目录下的”hadoop-用户名”文件夹,删除掉所有的hadoop目录中的hdfs中的name与data目录下得内容,然后重新格式化。
3.WordCount示例说明
统计文件中每个英文单词出现的字数。
3.1 流程说明
步骤1:将文字转换为键值对的形式,key:是单词本身,Value:固定1。
步骤2:key相同的排列在一起。
步骤3:相同key的value值相加。
具体实施:
-
- 编辑wordCount.java
- 编译wordCount.java
- 建立测试文件(英文文本文件)
- 执行wordCount.java
- 查看执行结果
3.2 编辑wordCount
所有的命令都是在master的虚拟机执行。
建立测试目录
mkdir –p ~/wordcount/input
转到测试目录
cd ~/wordcout
找到wordCount的源码
网址:
Apache Hadoop 3.3.4 – MapReduce Tutorial
sudo gedit WordCount.java
将源码复制到打开的文件中,并保存。
查看之前编辑好的文件
ll
3.3编译wordCount
打开文件,添加内容
sudo gedit ~/.bashrc
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
确定修改生效
source ~/.bashrc
开始编译
hadoop com.sun.tools.javac.Main WordCount.java
jar cf wc.jar WordCount*.class
ll
ll命令后查看测试目录中,产生了wc.jar,用来执行程序的文件。
3.4建立测试文件
将测试文件复制到之前的测试目录中
cp /usr/local/hadoop/LICENSE.txt ~/wordcount/input
ll ~/wordcount/input
启动hadoop集群环境(保证虚拟机都是开启的)
start-all.sh
上传文件到HDFS目录
建立目录
Hadoop fs –mkdir –p /user/hduser/wordcount/input
切换路径
cd ~/wordcount/input
上传
hadoop fs –copyFromLocal LICENSE.txt /user/hduser/wordcount/input
hadoop fs –ls /user/hduser/wordcount/input
可以查看已经上传的txt文件
3.5 执行wordCount
切换路径
cd ~/wordcount
执行程序
hadoop jar wc.jar WordCount /user/hduser/wordcount/input/LICENSE.txt /user/hduser/wordcount/output
说明:hadoop jar wc.jar WordCount【输入文件路径】 【输出文件路径】
查看输出目录
hadoop fs –ls /user/hduser/wordcount/output
查看输出文件的内容
hadoop fs –cat /user/hduser/wordcount/output/part-r-00000 | more
4.Spark环境搭建
4.1 Scala安装
- 下载Scala
选择2.11.6版本
wget http://www.scala-lang.org/files/archive/scala-2.11.6.tgz
- 设定目录及环境配置
解压缩
tar xvf scala-2.11.6.tgz
目录转移
sudo mv scala-2.11.6.tgz /usr/local/scala
编辑环境配置
sudo gedit ~/.bashrc
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
source ~/.bashrc
- 查看安装是否成功
scala
进入互动界面
输入1+1,看是否会有结果。
4.2 Spark2.0安装
- 下载Spark

选择4旁边的连接,获得下载地址
wget https://archive.apache.org/dist/spark/spark-2.0.0/spark-2.0.0-bin-hadoop2.6.tgz
- 设定目录及环境配置
解压缩
tar xvf spark-2.0.0-bin-hadoop2.6.tgz
目录转移
sudo mv spark-2.0.0-bin-hadoop2.6.tgz /usr/local/spark/
编辑环境配置
sudo gedit ~/.bashrc
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
source ~/.bashrc
- 查看安装是否成功
pyspark
会出现spark与python的版本,最后出现提示符>>>
exit()
离开互动界面。
4.3 测试pyspark读取HDFS
- 建立测试文档
复制txt文件
cp /usr/local/hadoop/LICENSE.txt ~/wordcount/input
ll ~/woedcount/input
启动四台虚拟机
start-all.sh
向HDFS上上传文件
在HDFS上建立目录,接收文件
hadoop fs –mkdir –p /user/hduser/wordcount/input
cd ~/wordcount/input
切换目录后,上传文件
hadoop fs –copyFromLocal LICENSE.txt /user/hduser/wordcount/input
4.4 在不同的模式下执行pyspark
- 本机执行(如果pyspark执行不成功,请参考后面的spark搭建)
pyspark –master local[*]
在>>>后输入如下命令
sc.master (查看当前的执行模式)
textFile=sc.textFile(“file:/usr/local/spark/README.md) (读取本机文件)
textFile=sc.textFile(“hdfs://master:9000/user/hduser/wordcount/input//LICENSE.txt”) (读取HDFS上的文件)
textFile.count() (统计数量)
- Hadoop YARN执行
HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop pyspark –master yarn –deploy-mode client
进入>>>提示符之后,输入上一结的命令进行测试。
在http://master:8088 的前端页面上,查看程序执行情况。
- Spark standalone cluster模式执行
建立Spark standalone cluster执行环境。
复制Spark自带的spark-env.sh
cp /usr/local/spark/conf/spark-env.sh.template /usr/local/spark/conf/spark-env.sh
设置spark-env.sh文件
sudo gedit /usr/local/spark/conf/spark-env.sh
export SPARK_MASTER_IP=master
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=512m
export SPARK_EXECUTOR_INSTANCES=4
分别的含义:设定服务器名称,CPU核心,使用的记忆体,设定执行的个数。
将master上的spark程式,复制到data1
步骤:
在data1上执行:sudo mkdir /usr/local/spark
sudo chown hduser:hduser /usr/local/spark
exit
在master上执行:sudo scp –r /usr/local/spark hduser@data1:/usr/local
可以将spark程序复制到data1
同理,用同样的方法,将spark程序,复制到data2和data3.
设定Spark standalone cluster有哪些服务器:
sudo gedit /usr/local/spark/conf/slaves
打开文件后输入:data1
data2
data3
在master终端机上,启动Spark standalone cluster模式
/usr/local/spark/sbin/start-all.sh
执行pyspark程序
pyspark –master spark://master:7077 -num-executors 1 -total-executor-cores 3 --executor-memory 512m
出现提示符>>>
sc.master
textFile=sc.textFile(“hdfs://master:9000/user/hduser/wordcount/input//LICENSE.txt”) (读取HDFS上的文件)
textFile.count()
注意:读取本机文件时,必须在四台服务器上,同时拥有这个文件,才可。
5.Hive搭建
hadoop集群搭建,三个节点,分别是node01、node02、node03
一、集群搭建
1、解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /bigdata/install
#修改文件名
cd /bigdata/install
mv apache-hive-3.1.2-bin hive
2、解决Jar包冲突
#进入hive的lib目录
cd /bigdata/install/hive/lib
#备份日志jar
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
#guava版本和hadoop的版本不一致,取高版本的jar
mv guava-19.0.jar guava-19.0.jar.bak
#从hadoop的lib复制guava-27.0-jre.jar到hive的lib
cp -r /bigdata/install/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /bigdata/install/hive/lib/
3、配置环境变量
#修改
vi /etc/profile
#HIVE_HOME
export HIVE_HOME=/bigdata/install/hive
export PATH=$PATH:$HIVE_HOME/bin
#保存退出,加载环境变量
sourse /etc/profile
4、修改配置
#进入配置目录
cd /bigdata/install/hive/conf/
mv hive-env.sh.template hive-env.sh
#编辑文件
vi hive-env.sh
export JAVA_HOME=/bigdata/install/jdk1.8.0_141
export HADOOP_HOME=/bigdata/install/hadoop
export HIVE_CONF_DIR=/bigdata/install/hive/conf
export HIVE_HOME=/bigdata/install/hive
5、配置Metastore到MySQL
我这里的mysql数据库安装在node02虚拟机
vi hive-site.xml
javax.jdo.option.ConnectionURL jdbc:mysql://server1:3306/hive?createDatabaseIfNotExist=true JDBC connect string for a JDBC metastore javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver Driver class name for a JDBC metastore javax.jdo.option.ConnectionUserName hive username to use against metastore database javax.jdo.option.ConnectionPassword 123456 password to use against metastore database hive.cli.print.header true Whether to print the names of the columns in query output. hive.cli.print.current.db true Whether to include the current database in the Hive prompt. 6、分发Hive
分发到node02、node03
scp -r hive/ node02:$PWD
scp -r hive/ node03:$PWD
7、初始化元数据库
(1)进入node02虚拟机、登陆MySQL
mysql -uroot -p密码
(2)新建Hive元数据库
create database metastore;
quit;
(3)初始化Hive元数据库
schematool -initSchema -dbType mysql -verbose
8、启动Hive客户端
(1)启动Hive客户端
bin/hive

(2)查看一下数据库
show databases;
6.hadoop3.1.0+hive3.1.3+spark-3.0.0-bin-hadoop3.2 + scala-2.12.11+jdk8
6.1 spark-3.0.0-bin-hadoop3.2
Spark 集群安装(Standalone)
1)机器及角色划分
机器IP
机器名
节点类型
192.168.0.113
hadoop-node1
Master/Worker
192.168.0.114
hadoop-node2
Worker
192.168.0.115
hadoop-node3
Worker
2)三台机器安装JDK环境
3)下载
Spark下载地址:Downloads | Apache Spark

这里需要注意版本,请按照我标题中的版本下载。
# 下载$ wget https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz# 解压$ tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /opt/bigdata/hadoop/server/# 修改安装目录名称 cp -r /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2 /opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2
4)配置spark
首先编辑环境配置
sudo gedit ~/.bashrc
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
source ~/.bashrc
1、配置slaves文件
cd/opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/conf
cpworkers.template workers# slaves文件内容如下:hadoop-node1hadoop-node2hadoop-node3hadoop-node1即是master,也是worker
2、配置spark-env.sh
cd/opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/conf# 创建data目录(所有节点都得创建这个目录)mkdir-p /opt/bigdata/hadoop/data/spark-standalone# copy一份环境变量文件cpspark-env.sh.template spark-env.sh# 加入以下内容:SCALA_HOME=/home/cyuser/scala-2.12.11JAVA_HOME=/home/cyuser/jdk8export SPARK_MASTER_HOST=server1export SPARK_LOCAL_DIRS=/home/cyuser/spark-standaloneexport HADOOP_CONF_DIR=/home/cyuser/hadoop-3.1.0/etc/hadoop3、配置spark-defaults.conf
这里不做修改,如果需要修改,自行修改就行,默认端口7077cpspark-defaults.conf.template spark-defaults.confcatspark-defaults.conf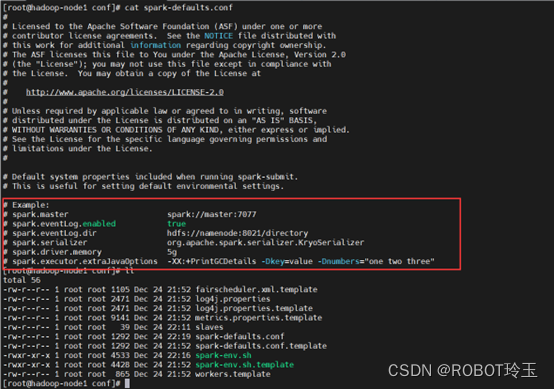
5)将配置好的包copy另外两台集群
$ scp -r spark-standalone-3.2.0-bin-hadoop3.2 hadoop-node2:/opt/bigdata/hadoop/server/$ scp -r spark-standalone-3.2.0-bin-hadoop3.2 hadoop-node3:/opt/bigdata/hadoop/server/5)启动
1、启动Master(在hadoop-node1节点上执行)
cd/opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/sbin$ ./start-master.sh# 查看进程端口,spark master web ui 默认端口为8080$ ss -tnlp|grep :8080# 如果端口冲突,修改start-master.sh脚本里的端口即可$ grep SPARK_MASTER_WEBUI_PORT start-master.sh
访问spark master web ui:http://hadoop-node1:8080
2、启动Worker节点(在所有节点上都执行)
cd/opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/sbin$ ./start-worker.sh spark://hadoop-node1:7077
五、测试验证
spark-submit 详细参数说明
参数名
参数说明
--master
master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local
--deploy-mode
在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client
--class
应用程序的主类,仅针对 java 或 scala 应用
--name
应用程序的名称
--jars
用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下
--packages
包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标
--exclude-packages
为了避免冲突 而指定不包含的 package
--repositories
远程 repository
--conf PROP=VALUE
指定 spark 配置属性的值, 例如 -conf spark.executor.extraJavaOptions="-XX:MaxPermSize=256m"
--properties-file
加载的配置文件,默认为 conf/spark-defaults.conf
--driver-memory
Driver内存,默认 1G
--driver-java-options
传给 driver 的额外的 Java 选项
--driver-library-path
传给 driver 的额外的库路径
--driver-class-path
传给 driver 的额外的类路径
--driver-cores
Driver 的核数,默认是1。在 yarn 或者 standalone 下使用
--executor-memory
每个 executor 的内存,默认是1G
--total-executor-cores
所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用
--num-executors
启动的 executor 数量。默认为2。在 yarn 下使用
--executor-core
每个 executor 的核数。在yarn或者standalone下使用
1)driver client模式(--deploy-mode client)
cd/opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/bin$ ./spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://hadoop-node1:7077 \--deploy-mode client \--driver-memory 1G \--executor-memory 1G \--total-executor-cores 2 \--executor-cores 1 \/opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.0.jar 10这种模式运行结果,直接在客户端显示出来了。

2)driver cluster模式(--deploy-mode cluster)
cd/opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/bin$ ./spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://hadoop-node1:7077 \--deploy-mode cluster \--driver-memory 1G \--executor-memory 1G \--total-executor-cores 2 \--executor-cores 1 \/opt/bigdata/hadoop/server/spark-standalone-3.2.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.0.jar 10这种模式基本上没什么输出信息,需要登录web页面查看
查看driver日志信息

最终在driver日志里查看运行结果了。
6.2 Spark以yarn模式启动
修改配置
- 如果您已经完成了hadoop集群和spark集群(standalone模式)的部署,接下来只需要两步设置即可:
- 假设hadoop的文件夹hadoop-2.7.7所在目录为/home/hadoop/,打开spark的spark-env.sh文件,在尾部追加一行:(要根据实际的hadoop安装目录添加)
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.7.7/etc/hadoop- 打开hadoop-2.7.7/etc/hadoop/yarn-site.xml文件,在configuration节点中增加下面两个子节点,如果不做以下设置,在提交spark任务的时候,yarn可能将spark任务kill掉,导致"Failed to send RPC xxxxxx"异常:
<property>yarn.nodemanager.pmem-check-enabledname>falsevalue>property>
<property>yarn.nodemanager.vmem-check-enabledname>falsevalue>property>
- 本次实战一共有三台电脑,请确保在每台电脑上都做了上述配置;
启动hadoop和spark
- hadoop和spark都部署在当前账号的家目录下,因此启动命令和顺序如下:
~/hadoop-2.7.7/sbin/start-dfs.sh \&& ~/hadoop-2.7.7/sbin/start-yarn.sh \&& ~/hadoop-2.7.7/sbin/mr-jobhistory-daemon.sh start historyserver \&& ~/spark-2.3.2-bin-hadoop2.7/sbin/start-all.sh验证spark
- 在hdfs创建一个目录用于保存输入文件:
~/hadoop-2.7.7/bin/hdfs dfs -mkdir /input- 准备一个txt文件(我这里是GoneWiththeWind.txt),提交到hdfs的/input目录下:
~/hadoop-2.7.7/bin/hdfs dfs -put ~/GoneWiththeWind.txt /input- 以client模式启动spark-shell
~/spark-2.3.2-bin-hadoop2.7/bin/spark-shell --master yarn --deploy-mode client- 以下信息表示启动成功:
2019-02-09 10:13:09 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicableSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).2019-02-09 10:13:15 WARN Client:66 - Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.Spark context Web UI available at http://node0:4040Spark context available as 'sc' (master = yarn, app id = application_1549678248927_0001).Spark session available as 'spark'.Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 2.3.2/_/Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_191)Type in expressions to have them evaluated.Type :help for more information.scala>- 输入以下内容,即可统计之前提交的txt文件中的单词出现次数,然后将前十名打印出来:
sc.textFile("hdfs://node0:8020/input/GoneWiththeWind.txt").flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _).sortBy(_._2,false).take(10).foreach(println)说明:
node0:8020为core-site.xml文件中设置的地址
- 控制台输出如下,可见任务执行成功:
scala> sc.textFile("hdfs://node0:8020/input/GoneWiththeWind.txt").flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _).sortBy(_._2,false).take(10).foreach(println)(the,18264)(and,14150)(to,10020)(of,8615)(a,7571)(her,7086)(she,6217)(was,5912)(in,5751)(had,4502)- 在网页上查看yarn信息,如下图:

参考链接地址:
-
相关阅读:
Android14前台服务适配指南
16Java基本数据类型与引用数据类型/值传递与引用传递
vue3-组合式API
写在大二结束
前端 | 如何使用 css 实现居中效果
KDE算法解析
cx3588系统常见问题
界面重建——Marching cubes算法
tonybot 人形机器人 定距移动 代码编写玩法
大数据ClickHouse进阶(二十三):ClickHouse用户配置
- 原文地址:https://blog.csdn.net/malingyu/article/details/127431625