-
深度学习:VGG(Vision Geometrical Group)论文详细讲解
深度学习:VGG(Vision Geometrical Group)论文详细讲解
前置知识
Lenet-5服装分类
卷积神经网络详细指南
SGD+动量法
反向传播公式推导VGG模型
概述
💡虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。
与芯片设计中工程师从放置晶体管到逻辑元件再到逻辑块的过程类似,神经网络架构的设计也逐渐变得更加抽象。研究人员开始从单个神经元的角度思考问题,发展到整个层,现在又转向块,重复层的模式。
使用块的想法首先出现在牛津大学的视觉几何组(visualgeometry
group)的VGG网络中。通过使用循环和子程序,可以很容易地在任何现代深度学习框架的代码中实现这些重复的架构。网络结构如下:

核心观点总结
优点
- 作者提出了更深的网络在大规模的数据集上的性能更好。
- 第一次提出了卷积块的概念。
- 全连接层 -> 全卷积层的测试表现更好。
缺点
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层。
3*3卷积的优势
感受野(Receptive Filed)

感受野定义
在此之前,为了更好的理解论文,我们要先学会如何计算感受野。我们把图片输入进卷积层,会输出关于这张图的feature map,这张feature map(假设channel=1)中的每一个点都对应了原图的一个区域(换句话说就是这个点是卷积核看过原图的多少个点得到的),而这个区域我们就叫做感受野。
计算公式如下:
R F l + 1 = R F l + ( K e r n e l S i z e l − 1 ) ∗ S r i d e l RF_{l+1} =RF_l+(KernelSize_{l}-1)*Sride_{l} RFl+1=RFl+(KernelSizel−1)∗Sridel感受野样例计算
假设我们有一个 7 * 7的图像,经过一次2 * 2卷积,padding=0,stride=1,输出为6 * 6,在经过3 * 3卷积,padding=0,stride=1,输出为4*4.

其中原图的感受野为1.
R F 1 = R F 0 + ( K e r n e l S i z e 0 − 1 ) ∗ S t r i d e 0 = 1 + ( 2 − 1 ) ∗ 1 = 2 RF_1=RF_0+(KernelSize_0-1)*Stride_0=1+(2-1)*1=2 RF1=RF0+(KernelSize0−1)∗Stride0=1+(2−1)∗1=2
R F 2 = R F 1 + ( k e r n e l S i z e 1 − 1 ) ∗ S t r i d e 1 = 2 + ( 3 − 1 ) ∗ 1 = 4 RF_2=RF_1+(kernelSize_1-1)*Stride_1=2+(3-1)*1=4 RF2=RF1+(kernelSize1−1)∗Stride1=2+(3−1)∗1=4堆叠卷积层的优势
我们知道一个图片经过了一个7 * 7卷积的feature map的感受野是7 * 7,而图片经历了三个3 * 3后的frature map也是7 * 7,在VGG的论文中,就用到了这一个想法。
后来经过实验证明,发现用三个3 * 3卷积的效果确实比7*7好。- 我们首先看一下参数量:我们假设3 * 3卷积核的channel数与7 * 7都固定为C,那么图片经历了7 * 7卷积核的参数就是 77C * C= 49 C 2 49C^2 49C2,而3 * 3的卷积参数为 (33C*C)*3= 27 C 2 27C^2 27C2其中参数差了一半,他们看过图像的区域是一样的,但是参数少了,那么计算就快了,还有些许正则化的功效。
- 模型经过了三个卷积层,那么他就有经历了三次非线性变换,那么模型就会更复杂,有更强的识别能力。
训练(Training)方法
Configuration
为了方便对照,VGG作者设立了6个模型:

激活函数采用ReLU,优化方法采用带动量的SGD,采用了L2正则,在前两个全连接层加入DropOut层。Training Image Size
作者还运用了随机裁剪的数据增强方法,其中我们把图像的最小边设置成S(裁剪大小),其中S不小于224,如果S=224,那么送入网络的就是完整的图像,如果S大于224,模型就会拿到图片中的一个小物体,或者物体的一部分。
作者提到了两种设置S的方法:- 第一种方法:固定S,我们采用两个尺寸,分别为256和384(也就是说用S=256训练一个模型,让后用S=384训练一个模型,最后集成两个模型的结果)。为了加速训练,我们初始化S=256的参数,然后训练收敛后,把它256的参数用作384参数的初始化。
- 第二种方法:多尺度训练,也就是是说S不在固定,我们选用了一个S的范围:[S_min,S_max],其中原文为:[256,512],对于每一种图片,我们在这个范围中随机选取一个S。为了加速训练,我们把S=384的收敛参数作为多尺度训练S的初始化参数。
测试(Testing)方法
当我们的模型训练好,在测试的时候,我们把测试图片的最小边设置为Q(测试尺度),其中Q不一定等于S。如果训练阶段采取多个S,那么测试阶段的Q采用多个S的均值。
在作者后来的实验中,作者发现:S固定没有S不固定的效果要好。
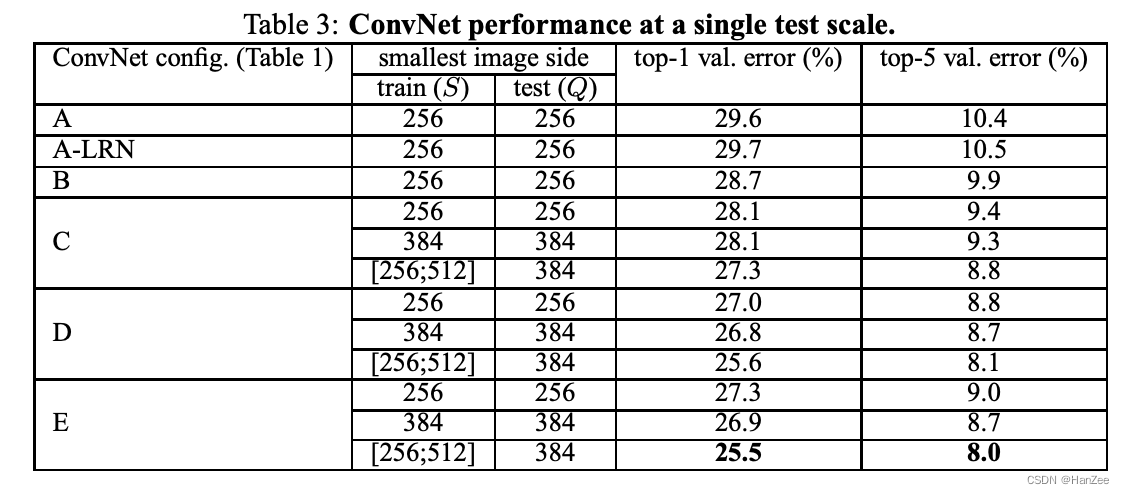
全卷积测试(Densely)
作者把网络结构的后三层全连接网络转换成全卷积网络,把第一层转化成4096个77的卷积核,后面两层则换成了11的记得卷积核,数量为之前神经元的数量。这样的话,如果图像尺寸改变,送入网络后,他不会因为尺寸不对而报错,只会增加feature map的大小,最后我们可以采用均值池化的方式来降维,于是他就不需要裁剪。
Multi-Crop
通过将测试图片缩放到不同大小Q,Q可以不等于S(训练时图片大小)。在QQ图片上裁剪出多个SS的图像块,将这些图像块进行测试,得到多个1*n维的向量。通过对这些向量每一纬求平均,得到在某一类上的概率。这种方法叫做multi-crop。
测试结果如下:

基于VGG的服装分类(Pytorch)
服装分类数据集
我们可以通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中。
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式, # 并除以255使得所有像素的数值均在0到1之间 def load_data_fashion_mnist(batch_size, resize=None): #@save """下载Fashion-MNIST数据集,然后将其加载到内存中""" trans = [transforms.ToTensor()] if resize: trans.insert(0, transforms.Resize(resize)) trans = transforms.Compose(trans)#通过compose组合多个操作 mnist_train = torchvision.datasets.FashionMNIST( root="../data", train=True, transform=trans, download=True) mnist_test = torchvision.datasets.FashionMNIST( root="../data", train=False, transform=trans, download=True) return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=4), data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=4)) #num workers 为线程数- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
定义模型
import torch from torch import nn from d2l import torch as d2l conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512)) def vgg_block(num_convs, in_channels, out_channels): layers = [] for _ in range(num_convs): layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)) layers.append(nn.ReLU()) in_channels = out_channels layers.append(nn.MaxPool2d(kernel_size=2,stride=2)) return nn.Sequential(*layers) conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512)) def vgg(conv_arch): conv_blks = [] in_channels = 1 # 卷积层部分 for (num_convs, out_channels) in conv_arch: conv_blks.append(vgg_block(num_convs, in_channels, out_channels)) in_channels = out_channels return nn.Sequential( *conv_blks, nn.Flatten(), # 全连接层部分 nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096, 10)) net = vgg(conv_arch) # ratio = 4 # small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch] # net = vgg(small_conv_arch)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
测试数据
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save """使用GPU计算模型在数据集上的精度""" if isinstance(net, nn.Module): net.eval() # 设置为评估模式 if not device: device = next(iter(net.parameters())).device # 正确预测的数量,总预测的数量 metric = d2l.Accumulator(2)#累加器 with torch.no_grad():#禁止计算梯度 for X, y in data_iter: if isinstance(X, list): # BERT微调所需的(之后将介绍) X = [x.to(device) for x in X] else: X = X.to(device) y = y.to(device) metric.add(d2l.accuracy(net(X), y), y.numel()) return metric[0] / metric[1]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
训练模型
#@save def train_ch6(net, train_iter, test_iter, num_epochs, lr, device): """用GPU训练模型(在第六章定义)""" def init_weights(m): if type(m) == nn.Linear or type(m) == nn.Conv2d: nn.init.xavier_uniform_(m.weight) net.apply(init_weights) print('training on', device) net.to(device) optimizer = torch.optim.SGD(net.parameters(), lr=lr) loss = nn.CrossEntropyLoss() animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], legend=['train loss', 'train acc', 'test acc']) timer, num_batches = d2l.Timer(), len(train_iter) for epoch in range(num_epochs): # 训练损失之和,训练准确率之和,样本数 metric = d2l.Accumulator(3) net.train() for i, (X, y) in enumerate(train_iter): timer.start() optimizer.zero_grad() X, y = X.to(device), y.to(device) y_hat = net(X) l = loss(y_hat, y) l.backward() optimizer.step()#更新参数 with torch.no_grad(): metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0]) timer.stop() train_l = metric[0] / metric[2] train_acc = metric[1] / metric[2] if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1: animator.add(epoch + (i + 1) / num_batches, (train_l, train_acc, None)) test_acc = evaluate_accuracy_gpu(net, test_iter) animator.add(epoch + 1, (None, None, test_acc)) print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, ' f'test acc {test_acc:.3f}') print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec ' f'on {str(device)}')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
train_iter, test_iter = load_data_fashion_mnist(256, resize=224) train_ch6(net, train_iter, test_iter, 10, 0.01, d2l.try_gpu())- 1
- 2
- 3
结果展示

-
相关阅读:
从零开始学习软件测试-第43天笔记
Linux系统部署PostgreSQL 单机数据库
安卓实现沉浸式安卓状态栏实现
学习C++:C++进阶(四)CMake应用篇---打包、部署和安装 CMake 项目
在微信小程序中安装和使用vant框架
java 计算对象在内存中占用空间 大小
六、python Django REST framework[认证、权限、限流]
Python 爬虫学习之路 第一天
STC 51单片机42——汇编 定时器 舵机
方法(构造方法)与方法重载
- 原文地址:https://blog.csdn.net/qq_18555105/article/details/127413517